
본 포스팅은 <데이터 애널리틱스>를 참고하여 작성되었습니다.
3. 머신러닝
3-1. 문제를 푸는 방법
- 행동에는 어떠한 패턴이 있고 이런 행동을 100% 완벽하게 예측할 수는 없을지라도 그 행동에서 특정한 패턴 또는 정규성을 발견함으로써 가능한 한 매우 비슷하게 예측할 수 있을 것
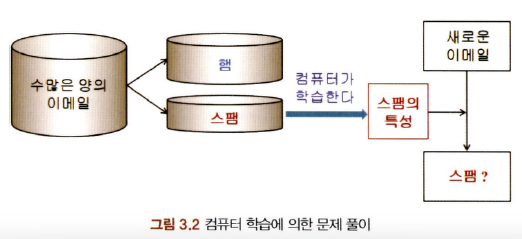
3-2. 머신러닝의 정의
작업 T, 측정된 성능을 P, 경험을 E라고 하자. 어떤 컴퓨터 프로그램이 T를 수행할 때 E가 증가함에 따라 P도 증가하면 그 프로그램은 T 수행에 있어서 E로부터 학습한다고 말할 수 있다. - Tom Mitchell, 1997
머신러닝은 컴퓨터에게 실생활에 대한 관측값과 실생활과의 상호작용에서 획득한 데이터와 정보를 제공함으로써, 컴퓨터가 인간처럼 학습하고 행동하도록 하며 그 학습이 시간에 지남에 따라 자율적인 방식으로 향상되도록 하는 과학 분야 - Daniel Faggella, 2017
3-3. 머신러닝의 유형
3-3-1. 지도학습 (Supervised Learning)
: 입력 속성 값과 목표 속성 값의 쌍으로 구성된 데이터 집합이 주어졌을 때 입력속성 값으로부터 목표속성(class, label) 값을 만들어내는 매핑 함수(Mapping Function)를 구축하는 학습 방법
- 목표 속성 : Class, Label이라고 부름
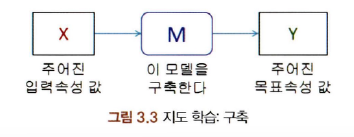
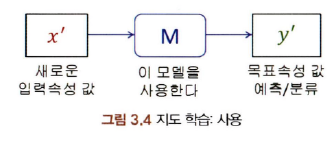
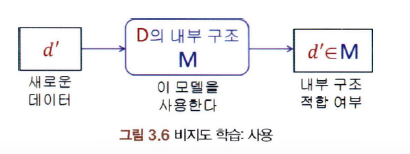
3-3-2. 비지도 학습 (Unsupervised Learning)
: 레이블이 없는 데이터 집합이 주어졌을 때 그 데이터의 내부 구조를 기술하는 모델을 구축하는 학습 방법
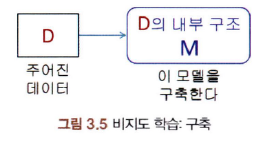
3-3-3. 준지도 학습 (Semi-supervised Learning)
: 지도 학습과 비지도 학습을 혼합해 사용하는 방법
- 모든 데이터에 레이블이 있는 것도 아니고, 모든 데이터에 레이블이 없는 것도 아니므로 섞어 사용하는 방법
3-3-4. 강화 학습
: 학습을 하는 주체 (Agent)가 환경으로부터 받는 피드백을 기반으로 상호작용하면서 학습해나가는 방법
- Agent가 올바른 행동을 하면 보상(Reward)을 받고 틀린 행동을 하면 벌점을 받음(Penalty)
- Reward를 최대화하고 Penalty를 최소화하는 방향으로 자신의 행동을 수정하면서 학습해나감
- 목표 속성의 정답이 주어지지 않고 그 행동이 옳다, 또는 틀렸다는 피드백만 주기 때문에 지도 학습과는 다름
3-4. 머신러닝의 기법들
3-4-1. 지도 학습 기법
-
회귀 분석 (Regression Analysis)
: 독립 변수와 종속 변수 간의 관계를 나타내는 식을 도출해서 독립변수로 종속변수를 설명하고 예측하는 기법
-
로지스틱 회귀 분석 (Logistic Regression Analysis)
: 종속 변수가 이진인 문제에 사용하는 회귀 분석
-
선형 판별 분석 (LDA : Linear Discriminant Analysis)
: 종속 변수에 따라 데이터를 분류해내는 독립변수의 선형 조합을 찾는 기법
-
베이즈 분류기 (Bayes Classifier)
: 독립변수가 서로 독립적이라는 가정하에 베이즈 정리를 이용해 데이터를 분류하는 기법
-
의사결정 트리 (Decision Tree)
: 큰 데이터 집합을 목표속성 값에 대해 연속적으로 작은 데이터 집합으로 나누는 규칙을 도출해 목표속성의 값을 예측하거나 데이터를 분류하는 기법
-
랜덤 포레스트 (Random Forest)
: 여러 개의 의사결정 트리를 무작위로 만들어서 그 결과들을 결합해 목표속성의 값을 예측하거나 데이터를 분류하는 기법
-
서포트 벡터 머신 (Support Vector Machine)
: 데이터 집합의 목표 속성 클래스 사이의 간격을 최대화하는 경계선을 찾아서 데이터를 분류하는 기법
-
인공 신경망 (Artificial Neural Network)
: 수많은 데이터 처리 요소를 네트워크로 연결해 그들을 연결하는 선의 가중치를 조정함으로써 목표속성의 값을 예측하거나 데이터를 분류하는 기법
-
딥러닝 (Deep Learning)
: 입력 계층과 출력 계층 사이에 있는 은닉 계층의 개수가 세 개 이상으로 구성된 신경망
3-4-2. 비지도 학습 기법
-
군집 분석 (Cluster Analysis)
: 레코드를 구성하는 속성의 정보만 사용해 데이터 집합을 그룹으로 나누는 기법
-
연관 분석 (Association Analysis)
: 데이터 집합으로부터 속성 간의 유용한 관계를 나타내는 규칙을 도출하는 기법
3-4-3. 준지도 학습 기법
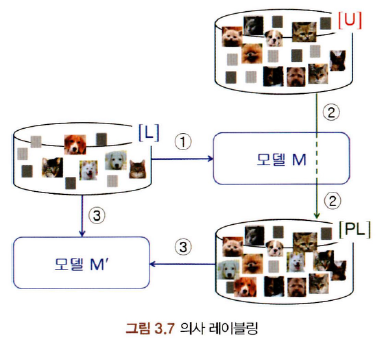
- 의사 레이블링 (Pseudo-labeling)
- 레이블이 있는 데이터 집합[L]로 모델 M을 학습시킨다.
- 레이블이 없는 데이터 집합 [U]에 모델 M을 적용해 의사 레이블이 있는 데이터 집합 [PL]을 만든다.
- 레이블이 있는 데이터 집합 [L]과 의사 레이블이 있는 데이터 집합 [PL]의 일부를 사용해 모델 M을 다시 학습시켜서 모델 M’을 구축한다.
- 다음 과정(1~3)을 여러번 반복한다.
3-4-4. 강화 학습 기법
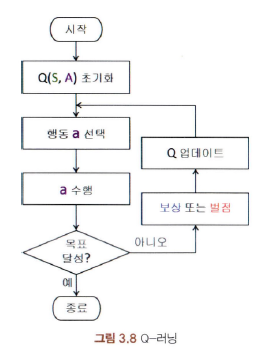
- Q-learning
- Agent가 처한 상황을 S라 하고 Agent가 각 상황에 따라 취할 수 있는 행동의 집합을 A라고 할 때, Q(S, A)로 표현
- Agent는 A 중 하나의 행동인 a를 수행함으로써 현재 상황에서 다음 상황으로 나아간다.
- 수행하는 행동의 결과에 따라서 Agent는 보상을 받거나 벌점을 받는다
- Agent의 목표는 보상을 최대화하고 벌점을 최소화하는 것.
Reference
[1] 데이터 애널리틱스 (2020, 이재식)
