Data-Driven Approach for Fault Detection and Diagnostic in Semiconductor Manufacturing 요약
저자 : Shu-Kai S. Fan , Chia-Yu Hsu
저널 : IEEE TRANSACTIONS ON AUTOMATION SCIENCE AND ENGINEERING
Abstract
I. INTRODUCTION
센서 데이터는 온도, 압력, 유체의 흐름, 가스 흐름, 라디오 주파수 파워등을 포함하는데, 이것들은 제품 생산 과정에서 모니터링 되며, 이것들을 통해 장비 모니터링, 툴의 상태 보전, 가상 계측에 활용된다. 조기이상탐지와 빠른 진단은 장비의 효과를 보증하는데 중요하며, 공정 과정을 컨트롤하고, 수율을 높이는데 필요하다.
반도체 생산 공정은 아주 복잡한 웨이퍼의 fabrication 공정 과정을 아주 많은 스텝, 레시피, 장비를 거치며 진행이 된다. 이 과정에서 FDC를 목적으로 센서가 설치되었고, 이것들을 SVID(Status variable idenficitation) 이라고 한다. 이러한 센서들은 실시간으로 모니터링 되어야 한다. 또한 빠르게 비정상적인 행동과 assignable cause를 구분해야 한다.
다변량 통계 공정 컨트롤 (MSPC : Multivariate statistical process control) 은 다양한 인풋을 모니터링하고, 공정의 전체적인 프로세스가 in control 상에 놓고자 한다. 이는 PCA를 활용하고 PLS(Paritial Least Squares) 를 활용한다. 그러나, 각 센서값들이 배치마다 달라지기 때문에 이상적인 가정의 정상 분포는 적용하기 힘들다. 이는 작동 환경이 배치마다 달라지기 때문인데, MSPC 방법론은 적합하지 않다. 최근에 데이터 마이닝 혹은 머신러닝 방법론이 이에 많이 사용되고 있다. 기존의 통계 모델에 비해 머신러닝 방법론은 더 적절하게 특성을 획득할 수 있다.
반도체에서 FDC의 챌린징 이슈는 적합한 classifier를 통해서 웨이퍼의 이상을 정확하게 탐지하는 것이다. 이는 키 SVID를 통해 이루어진다. 이러한 인디케이터 기반의 방법론은 모니터링 목적에 맞게 통계량이 계산된다는 것이다. 하지만 SVID와 같은 오리지널 데이터는 다양한 통계 indicators를 변환이 되기 때문에 이러한 방법으로는 엔지니어가 정확하게 이상이 탐지된 시점을 파악하기 어렵다. FDC 모델이 SVID 를 통해 작동하려면, 이상 탐지 뿐만이 아니라, fault 진단을 프로세싱 스텝과 시간에 따라서 수행해야 된다는 것이다. 게다가, 다른 제품의 레시피와 툴은 아주 다르기 때문에 제품마다의 특성을 반영해야한다.
따라서 본 연구에서는 data-driven 프레임워크에서, 몇몇 머신너링 방법론을 조합하여 웨이퍼 공정 과정의 FDC를 제안하고자 한다.
1. Fault detection 모듈에서는 SVID를 정상과 비정상 웨이퍼간 구분할 수 있는 key SVID를 추출해낸다. 그리고, 랜덤 포레스트 알고리즘을 통해서 SVID와 k-means를 통해 이 과정을 수행한다.
2. 앙상블 클래시파이어를 통해 이상을 퇌지한다. 이는 KNN과 네이브 베이지안 클래시파이어를 활용한다.
3. fault 진단 스테이지에서는 key SVID의 프로세싱 타임 포인트가 feature로 활용이 되어서 높게 영향을 미치는 타임 스텝을 결정한다. 이를 통해 key processing time identification을 수행하여 비정상 웨이퍼의 탐지 능력을 높인다.
key 파라미터와 key 프로세싱 타임 포인트를 통해서 potential root cause를 추적할 수 있다. 또한 t-sne를 통해 고차원의 특질을 시각화 한다.
II. FUNDAMENTALS OF FEATURE SELECTION BY USING MACHINE LEARNING
A. Variable Importance on Random Forests
랜덤포레스트 알고리즘은 카테고리화를 통해 피처를 선택하는 방법론이다. 이는 예측 퍼포먼스가 좋고 낮은 오버피팅, 높은 해석력을 가졌다. 해석력은 각 변수의 중요성을 비교할 수 있는 tree decision에 의해 쉽게 평가가 된다. 이는 Classification and regrssion tree(CART)라고 불린다. 변수중요도는 다음과 같이 계산된다.
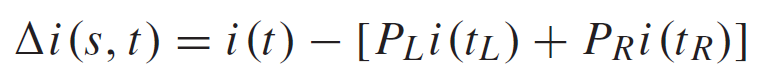
i (t) : 노드 t의 Gini impurity (데이터셋 s안의 클래스 i에 해당)
i (tL) : 노드 tL 에서 동일한 값
i (tR) : 노드 tR (t에서 스플릿) 에서 동일한 값
PL : 데이터가 노드 t에서 왼쪽으로 스플릿된 비율을 의미한다.
PR : 데이터가 노드 t에서 오른쪽으로 스플릿된 비율을 의미한다.
이때 변수 중요도는 다음과 같이 나타난다.
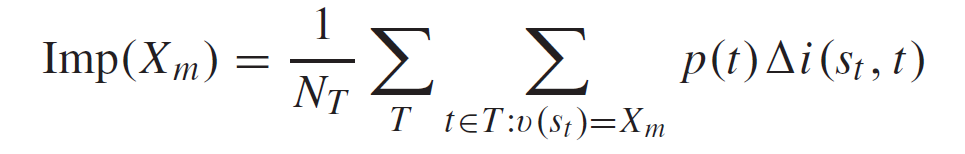
NT : 랜덤 포레스트의 트리 수
Xm : 트리 splite을 위한 feature의 갯수
p(t) : 노드 t에 있는 샘플들의 비율
v(st) : st 스플릿에 사용된 feature
반도체 SVID 의 중요도를 평가하는 것은 raw 데이터를 추적이 가능하게끔 만들어 준다. 또한 threshold 를 정해서 스크린 포텐셜 키 파라미터를 정한다.
B. Data-Driven Methods for Fault Detection and Diagnosis
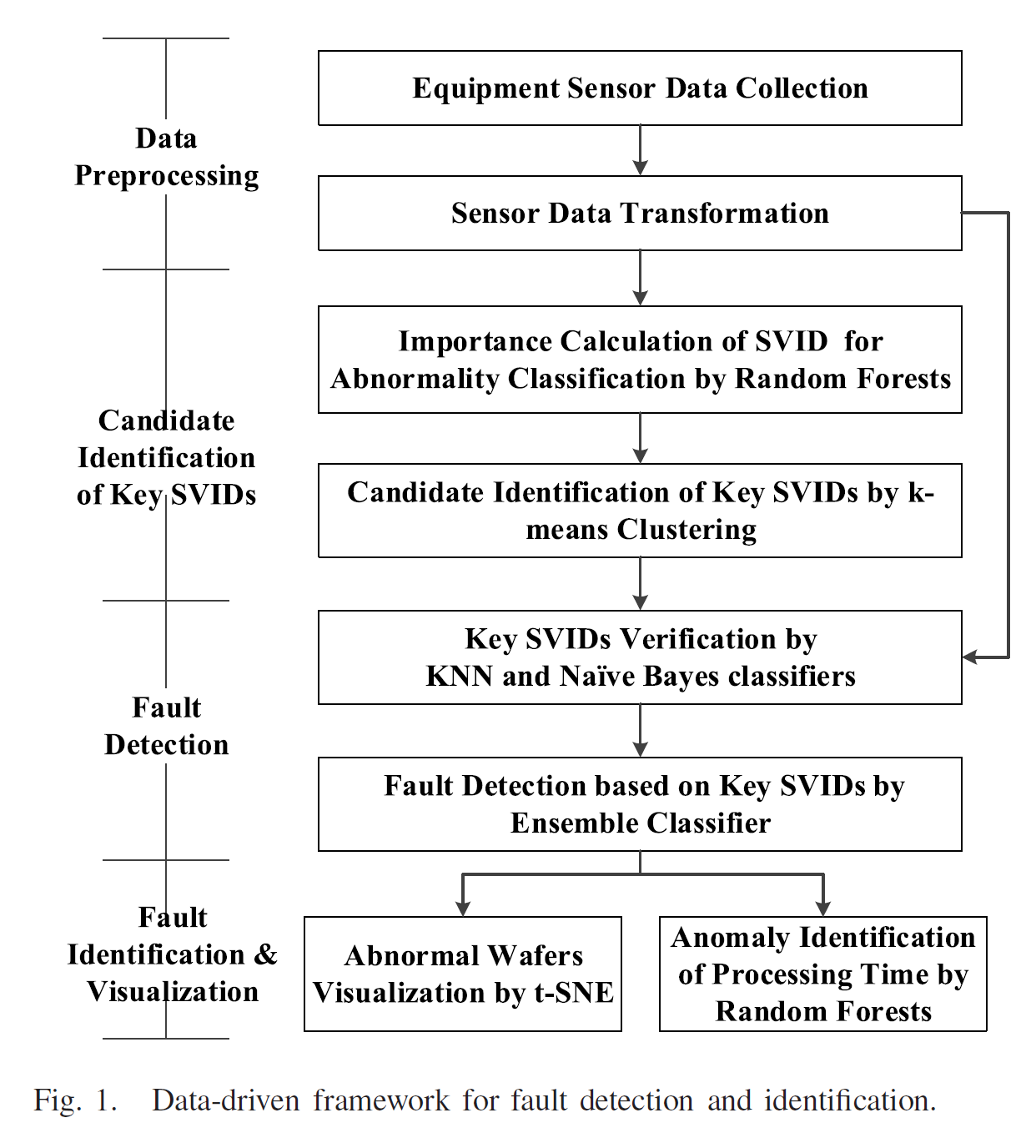
본 연구에서는 위와 같은 과정을 거쳐 키 파라미터와 키 프로세싱 타임을 얻는데 집중한다. 이는 기존의 연구가 fault detection과 diagnosis 를 직접적으로 수행하고자 하는 목적과는 다르며, 이것이 성공적으로 가능하다면 알려지지 않은 원인을 엔지니어에게 시간과 함께 제공할 수 있다.
III. PROPOSED APPROACH
A. Preprocessing for FDC Data
웨이퍼 i 에 대한 SVIDs데이터 Xi는 다음과 같이 정의된다.

xi, j,k : i번째 웨이퍼에서 j번째 SVID를 시간 k에서 수집한 데이터
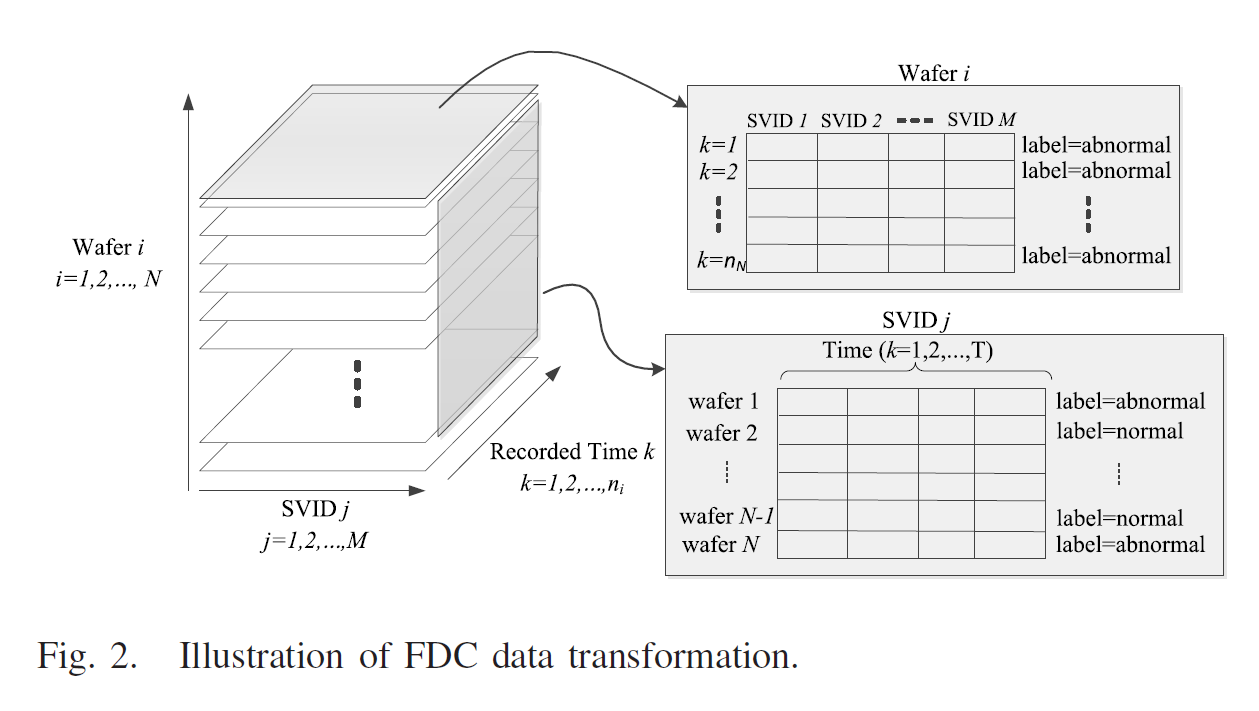
FDC 데이터는 변환되는데, key SVID를 얻기 위해서 X가 2-D 행렬로 unfold 되어서 X' 는 웨이퍼맵을 수평으로 자른 것을 의미한다. X'' 는 웨이퍼맵을 수직으로 자른 것을 의미하낟. 라벨이 0,1 로 되어서 정상인 경우 0, 비정상인경우 1이 된다.
B. Candidate Identification of Key SVIDs
랜덤 포레스트 알고리즘을 통해서 K번째 프로세싱 타임에서의 SVID 벡터는 다음과 같이 정의된다. 이는 i번째 웨이퍼에서 k번째 프로세싱 타임을 의미한다.
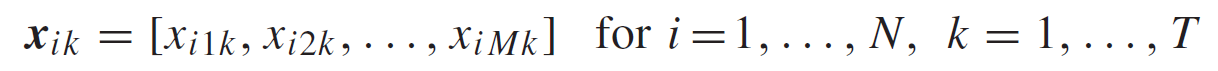
여기서 얻어진 importance value를 threshold 로 선별하고, kNN 클러스터링을 통해 k개의 클러스터로 분해한다.
C. Fault Detection
SVID를 클러스터링 한 뒤, 가장 높은 중요도를 보이는 그룹이 fault dectection model을 빌드하기 위한 그룹으로 선택되고, 이를 통해 앙상블 classifier 를 구축한다.
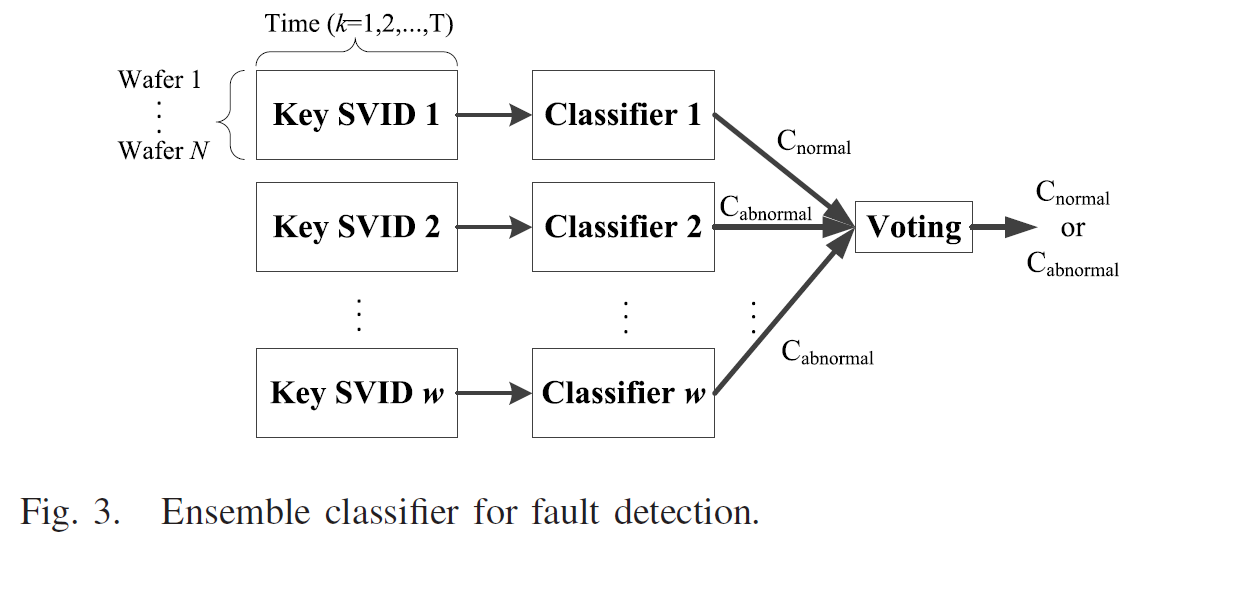
Naïve Bayes classifier 를 통해 효과적인 classification을 수행한다.
D. Fault Diagnostic and Data Visualization
key processing time 과 steps을 알기 위해서 row vector를 불러온다.
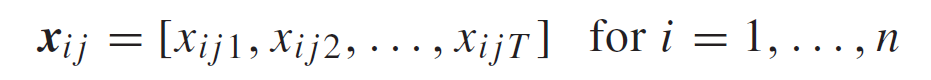
랜덤 포레스트를 통해 key processing time 과 step을 찾는다.
t-SNE를 통해 고차원의 데이터를 3차원으로 축소한다.
IV. EMPIRICAL RESULTS
A. Data Collection and Data Preprocessing
CVD 장비의 데이터를 활용한다. 66개중에 7개를 제외한 SVID가 활용되었으며, 1153개의 웨이퍼가 수집되었다.
A챔버 : 1130개의 웨이퍼가 정상, 23개의 웨이퍼가 비정상이다.
B챔버 : 919개의 웨이퍼가 정상, 46개의 웨이퍼가 비정상이다.
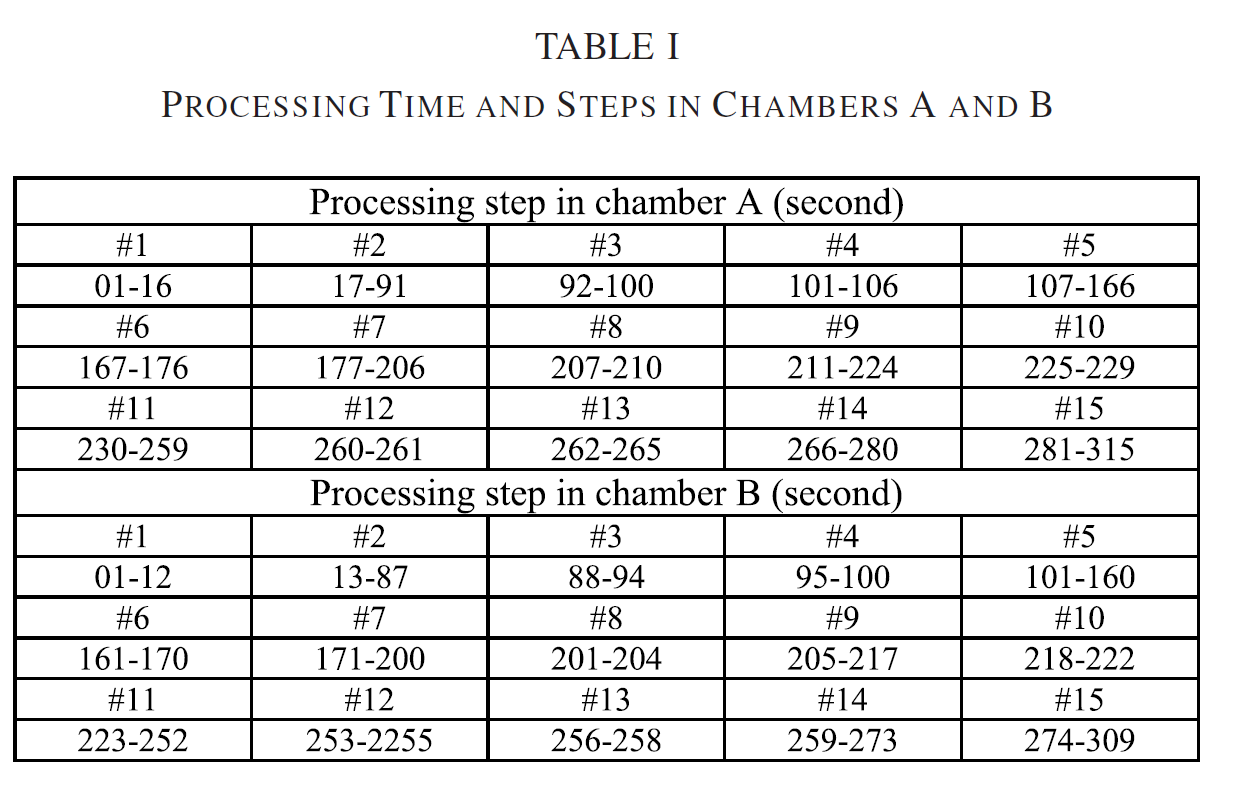
A의 시간은 325s, B의 시간은 309s 이다.
B. Key SVID
랜덤 포레스트를 수행한 결과는 다음과 같다. 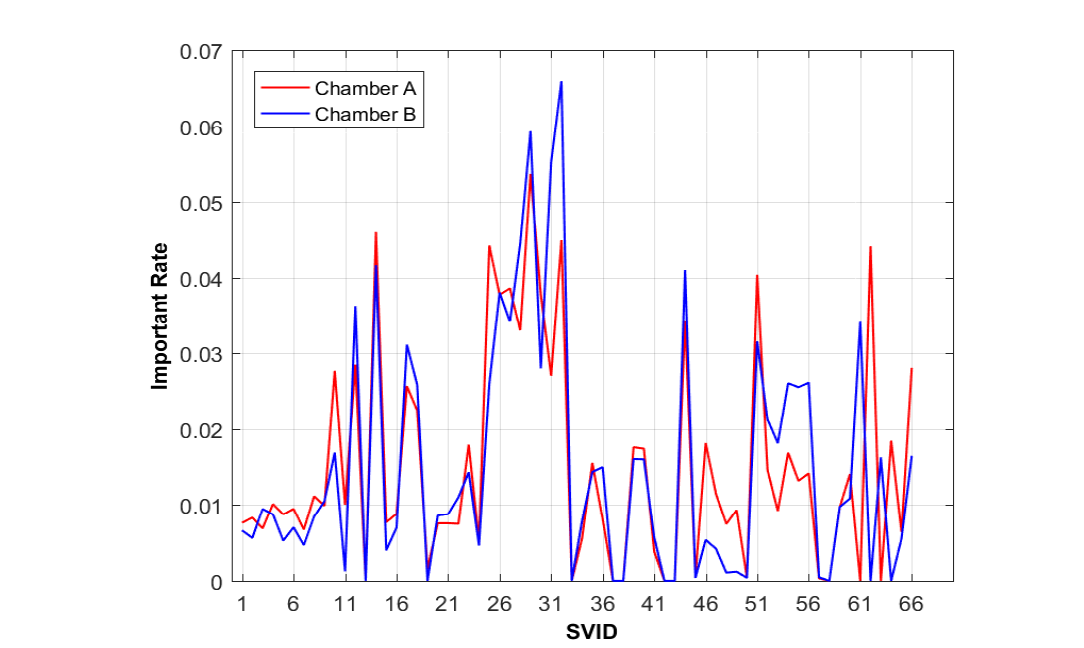
이후 kNN을 수행한다.
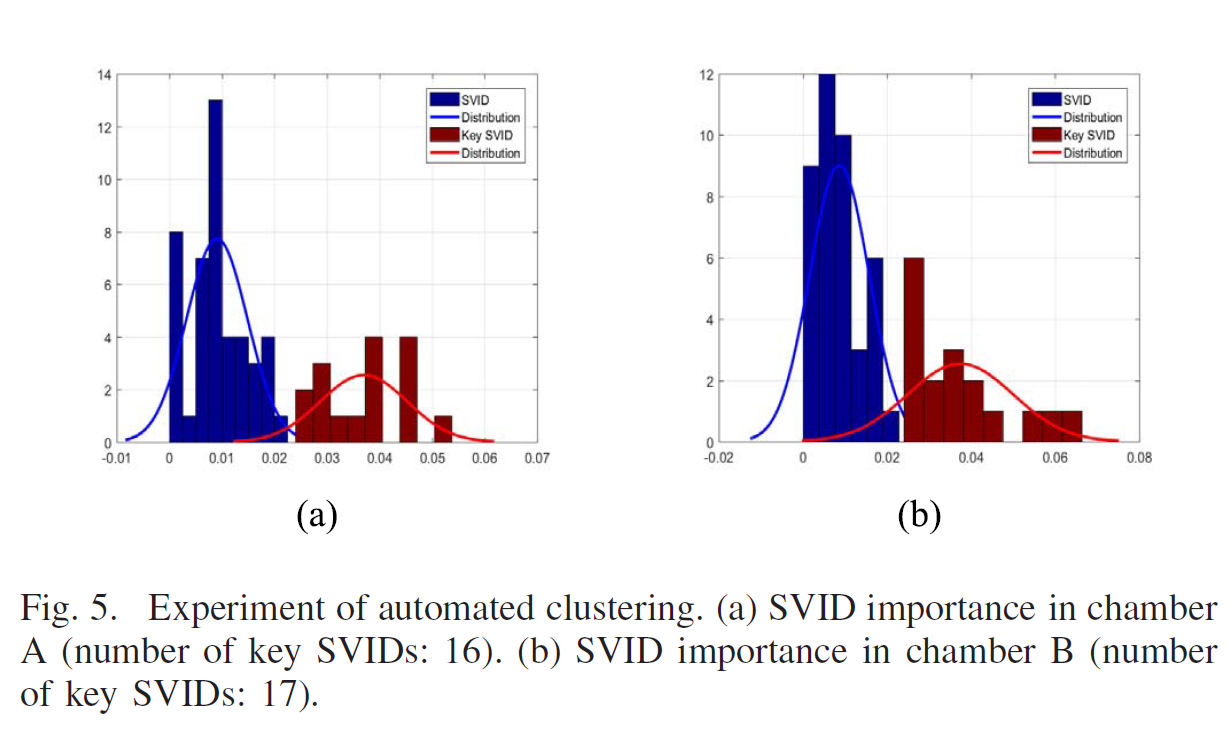
k = 2 로 설정하여서 key 파라미터 그룹과 non-key 파라미터 그룹을 분리하였다.
C. Fault Detection for Further Verification
key SVID를 13개개로 설정하여 Fault dectection을 수행한 결과 chamber a에 대한 결과는 다음과 같다.
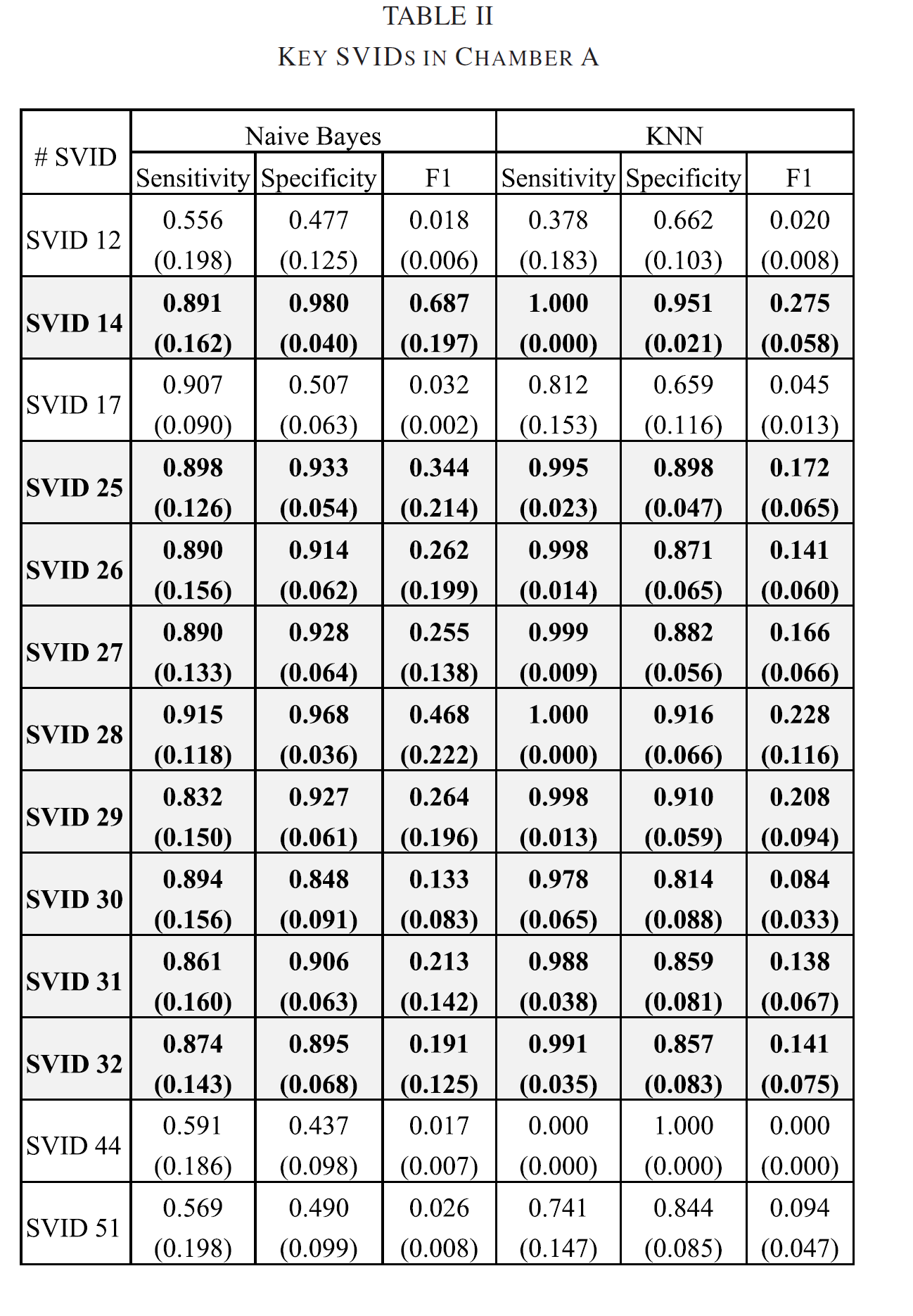
따라서, 최종적으로 9개의 key parameter를 선정하였다.
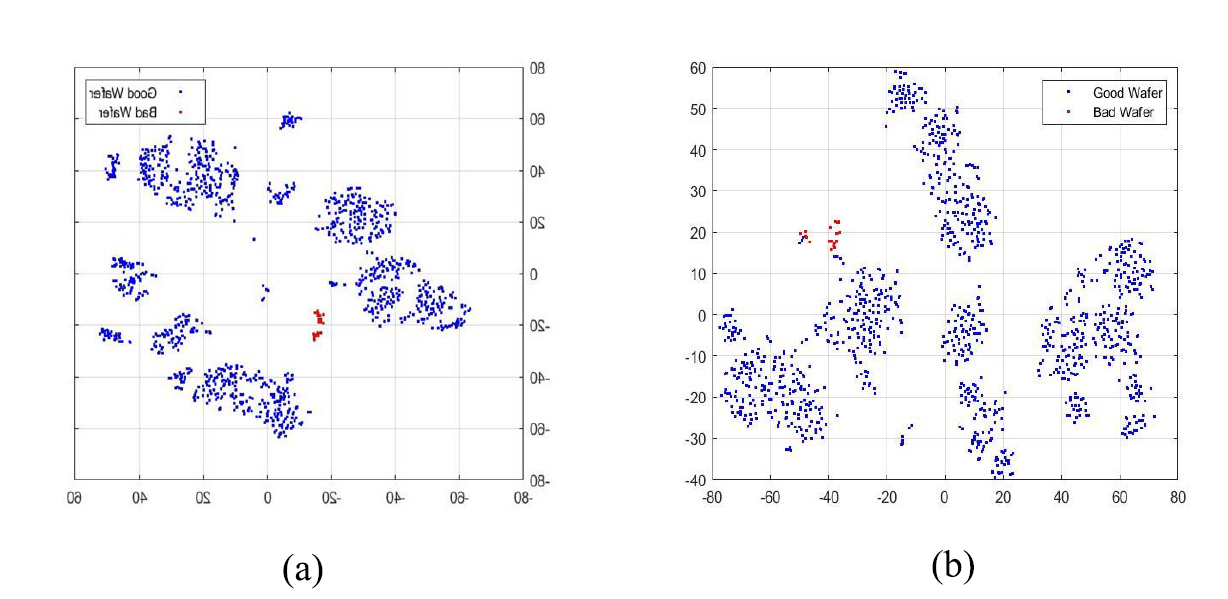
파라미터를 줄여서 t-SNE로 시각화한 경우, 파라미터를 줄인 것이 더 좋은 분리를 수행하였다.
D. Fault Diagnostic via Key Processing Time Identification
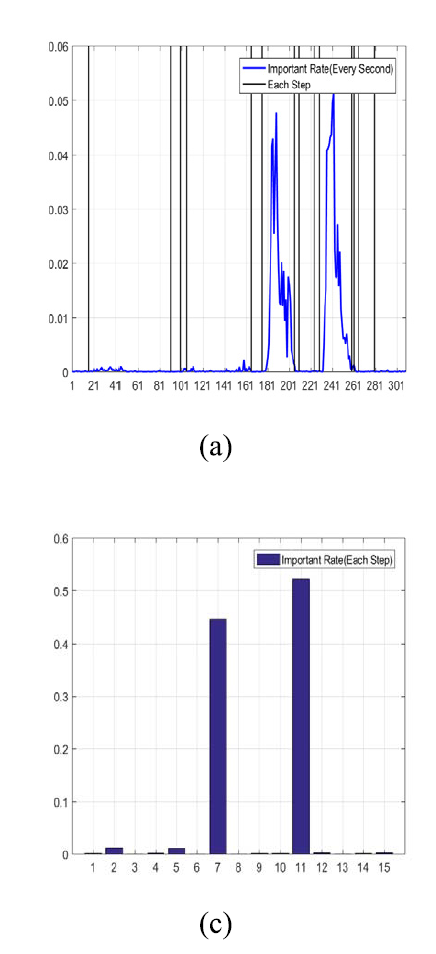
key time 및 step은 다음과 같이 나타난다. 이를 통해 어느 시점에 문제가 생겼는지 엔지니어가 확인을 할 수 있다.
V. CONCLUSION
본 연구를 통해 반도체 웨이퍼 제조 공정에서 key SVID와 key 스텝 및 타임을 추출할 수 있었다. 미래 연구로는 추출한 패턴을 가지고 prognosis를 수행하는 것이다. 또한 본 연구가 CVD만 수행되었지만, PVD, 에칭에도 수행하고자 한다.
