Optimal Feature Selection for Defect Classification in Semiconductor Wafers
저자 : José L. Gómez-Sirvent , Francisco López de la Rosa, Roberto Sánchez-Reolid, Antonio Fernández-Caballero , and Rafael Morales
저널 : IEEE TRANSACTIONS ON SEMICONDUCTOR MANUFACTURING(2022)
I. INTRODUCTION
반도체의 미세화로 많은 품질 이슈들이 생겨나고 있다. 검사 시스템에서 AI 테크닉에 대한 요구가 점차 커져가고 있고, ADC(automatic defect detection and classification) 시스템이 구축되어졌다. 컴퓨터 비전 기반의 검출 방법론은 두가지로 나눌 수 있는데, CNN 방법론을 feature extraction과 classification에 쓰는 방법론과, 컴퓨터 비전 방법론으로 feature extraction을 수행하고, 머신러닝 알고리즘을 통해 classification을 수행하는 방법론으로 나뉜다.
현재 메이저한 트랜드는 딥러닝 아키텍처를 사용하는 것이다. 그러나 이러한 방법론들은 best features를 찾아내야 하며, 이것이 optimal 솔루션인지를 보증할 수가 없다. 따라서 본 논문의 contribution은 다음과 같다.
1. exhaustive search (ES)를 통해 optimal subset of features를 찾는다. 이는 반도체의 SEM 이미지에서 defect을 classification 하는데 optimal subset을 찾는 알고리즘이다.
2. 가능한 모든 random selection의 subset에 대한 expected valuse를 계산한다.
3. 본 연구의 효과를 검증하기 위해 모든 subset 사이즈에 대한 계산을 수행하여 다른 모델들과의 성능을 비교한다.
4. 모든 feautres 의 combination을 비교한 뒤, 결과가 ES에 의해 얻어진 서브셋과 비교하여 이 결과가 실제로 optimal 솔루션인지를 검증한다.
II. FEATURE SELECTION METHODS
Feauter selection 방법론은 4가지로 나뉜다.
1. filter methods : 통계량을 통해 feature를 selection 하는데, 문제는 classifier에 대한 성능을 고려하지는 않는다.
2. wrapper methods : classification 모델에 넣어서 그들의 성능을 평가한다. 하지만 이것은 느리지만 정확한 subset을 찾을 수 있다.
3. embedded methods : optima subset을 classification 알고리즘을 수행할 때 얻는 것이다. 이는 tree 기반이 유명하다.
4. hybrid methods : 1번과 2번이 혼합된 형태로, 1번으로 먼저 차원을 축소한 뒤, 2번째 방법론으로 정확한 subset을 찾는다.
본 연구에서는 다양한 알고리즘을 참조한다.
One-way ANOVA, Mutual information, Minimum redundancy maximum relevance, Recursive feature elimination, Extremely randomized trees classifier, Random selection
이런 다양한 솔루션 중에서 최적의 솔루션은 하나이기 떄문에 ES를 수행하여 어떤 솔루션이 최적인지를 평가한다. flow는 다음과 같다.
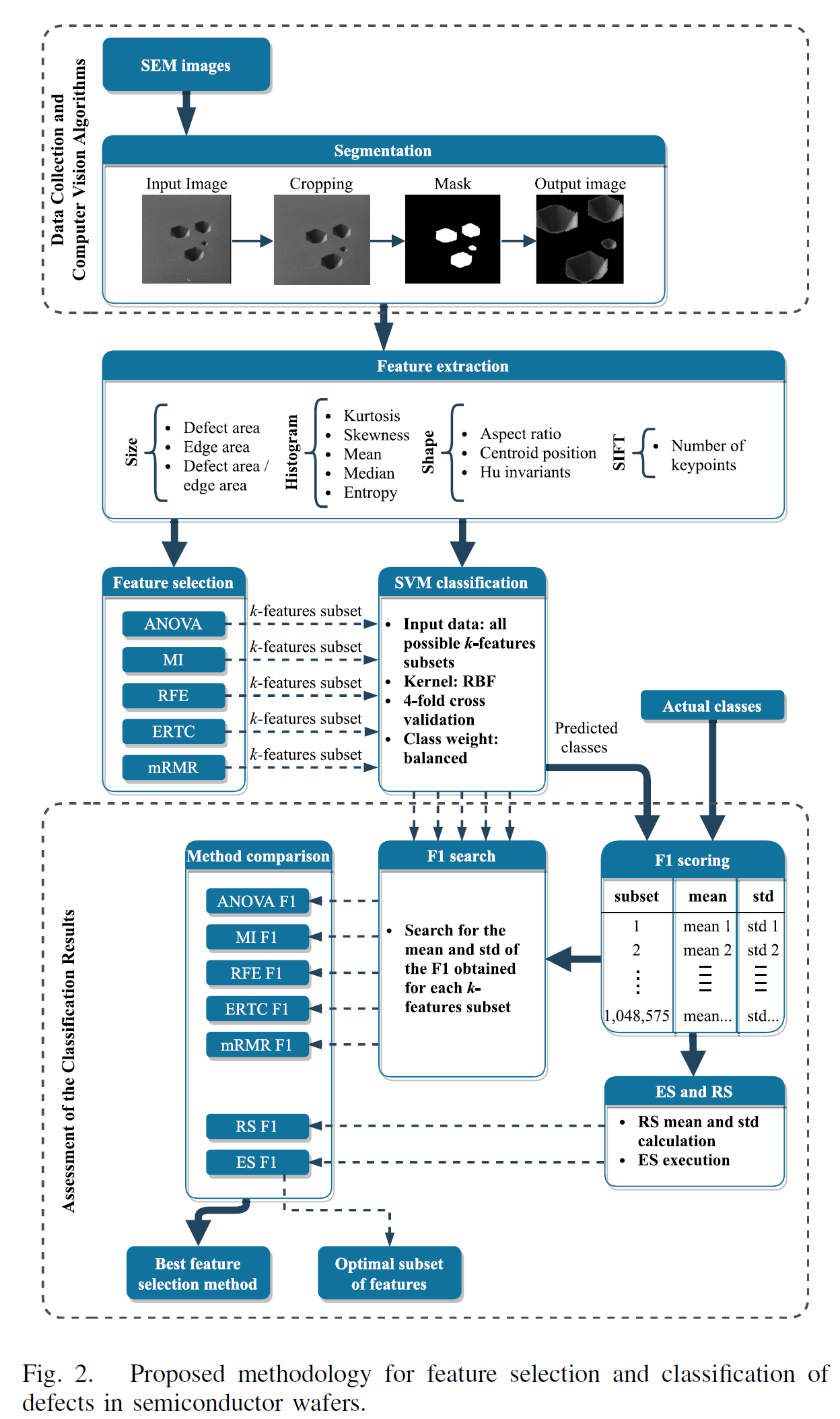
III. METHODS AND MATERIALS
A. Data Collection and Computer Vision Algorithms
먼저 SEM 이미지를 전문가가 defect을 라벨링 한다. 총 7개의 defect class가 정의된다.

defect 은 centered 되게 정렬 되었으며, 배경은 같은 색상이다. 이 라벨링 이후 컴퓨터 비전 알고리즘을 통해 특성을 추출하기 위해서 전처리를 수행한다. 첫번째 스테이지는 defect의 segmentation이다.
1. defect 이미지의 크롭
2. background의 제거 (백그라운드는 threshold를 통해 graytone을 마스킹하고 제거하였다)
이를 통해 output image와 같은 형태로 출력이 된다.
B. Feature Extraction
이미지의 특성을 추출하기 위해 feature vector를 사용한다.
1) Size Descriptors : 모든 이미지가 같은 scale이 아니기 때문에, defect area와 edge area간의 비율로 사이즈 feature를 추출한다.
2) Shape Descriotrs : defect의 형태학적 특성을 추출한다. (i) aspect ratio; (ii) relative position of the centroid within the image; and (iii) the original seven Hu invariants 이 있다.
3) Histogram Descriptors: 이미지의 grey 가 어떻게 분포되어있는지 특성을 추출한다. (i) kurtosis; (ii) skewness; (iii) mean; (iv) median; and (v) entropy 가 있다.
4) Number of Key Points: 스케일에 따라서 변호하지 않는 특성(SIFT) 를 사용한다.
C. Feature Selection
ANOVA, MI, RFE, ERTC, mRMR을 사용하여 각 모델에서 k개의 feature를 추출한다. ES 방법론을 통해 optimal subset을 미리 찾고, 6개의 방법론으로 레퍼런스를 활용한다.
D. SVM Classification
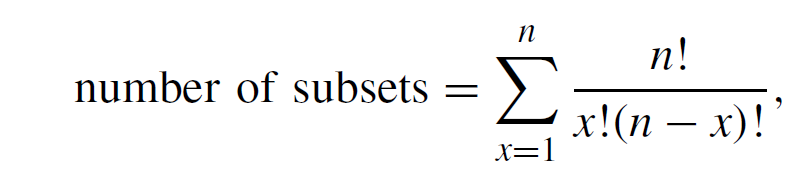
Subset의 수는 다음과 같다. 20개의 feature를 계산하면, 1,048,575개의 subset이 존재하게 된다. 이 candidate들에 대해 SVM with kernel radial basis function (RBF) 알고리즘을 통해 classification을 수행한다. RBF 커널은 linear 커널과 다르게 linear 하지 않는 데이터에 대해서도 효과적으로 seperable하다.
E. Assessment of the Classification Results
F1 스코어를 통해 clssification result를 비교하는데, RS와 ES가 같이 검증을 한다.
IV. EXPERIMENTAL RESULTS
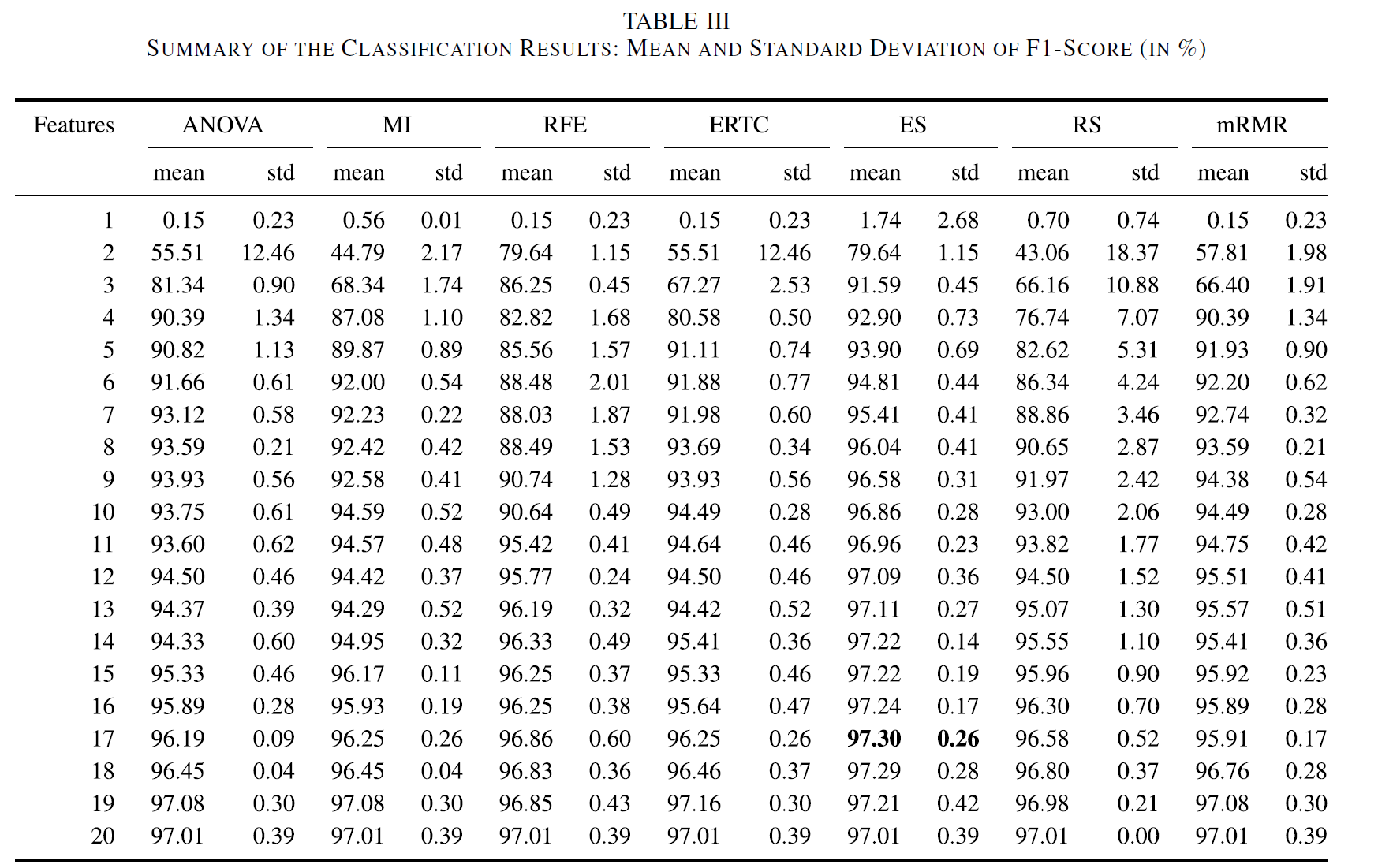
ES를 통해 17개의 features에서 maximum mean F1-score 97.30%를 달성하였다.
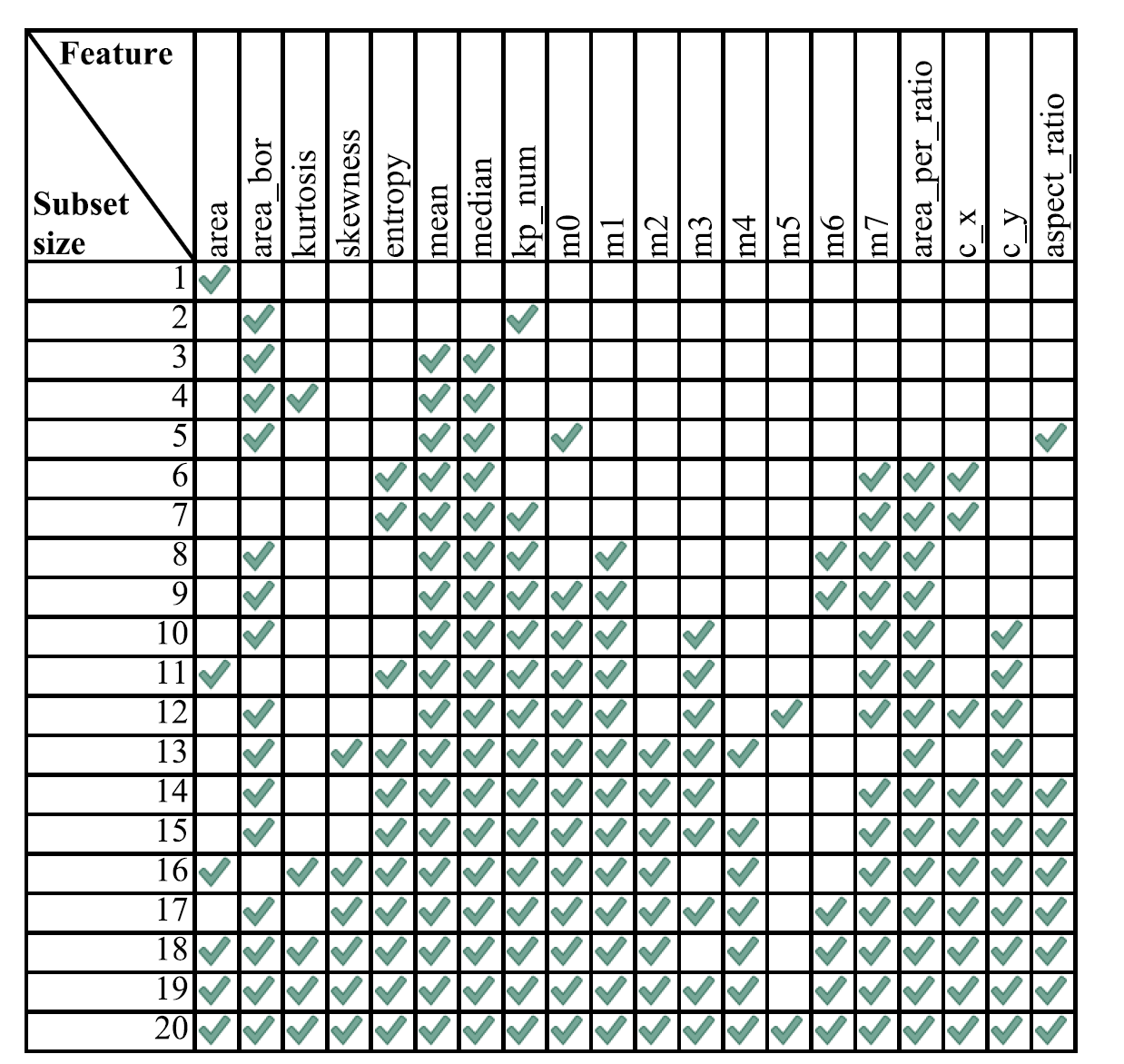
ES에서 각 subset이 어떻게 select되었는지는 다음과 같다.
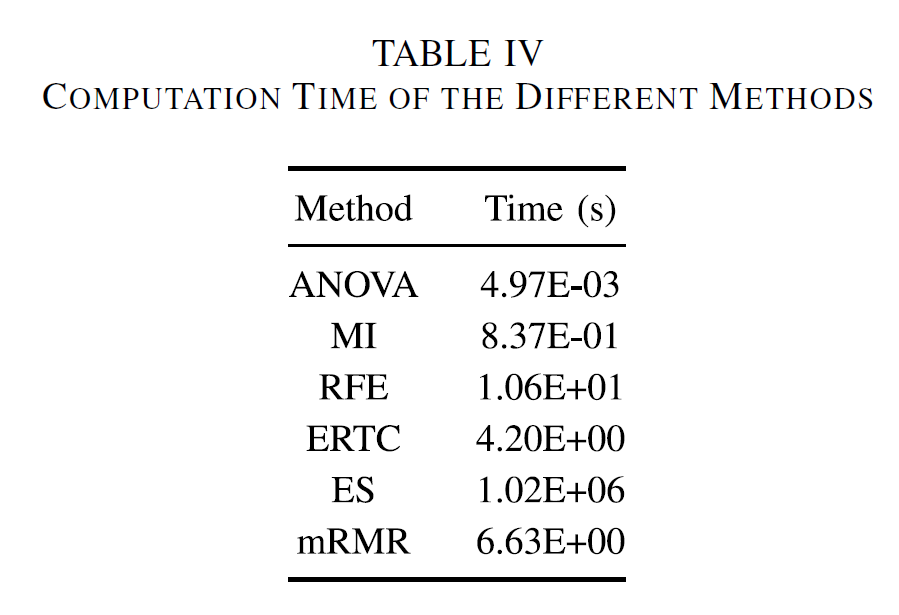
하지만 ES 방법은 너무 높은 computation cost를 요구한다. 다른 방법들은 몇 초만을 요구하지만, ES 방법은 1.02E + 06 s 를 요구하였다.
Non-exhaustive 방법론 중에서는 ANOVA가 시간도 빠르고 비슷하게 좋은 결과를 보였다.
V. CONCLUSION
본 연구는 SEM 이미지의 feature중에서 classification 성능을 높일 수 있는 optimal subset을 찾는 것이다. SVM classifier를 통해 모든 feature 에 대한 성능을 평가하였고, ES를 통해 optimal subset임을 검증하였다.
본 연구에서 제시한 방법론에서는 17features에서 97.30%, 13features에서 97.09%를 달성하였다. 반면에 다른 방법론들은 비슷한 결과를 19 혹은 20개의 feature로 달성하였다.
이러한 방법론, 특히 ES방법론 같은 경우는 계산 비용이 높지만, 기존의 머신비전의 CNN 기반의 방법론들에 비해서는 효과적이다. 또한 제안한 방법론으로 적절한 feature 차원의 축소가 수행된다면 데이터의 상관이 낮은 추출이 가능하고 이를 통해 univariate method를 통한 분석이 가능한 데이터셋을 획득할 수 있다.
