Multivariate Time-series Anomaly Detection via Graph Attention Network
Abstract
다변량 시계열 데이터는 산업 분야에서 다양하게 활용 가능. 지금까지의 한계로는 다변량 시계열 데이터의 관계를 explicit 하게 밝히지 않아 false alarm을 일으킴
본 연구에서는, 이상치 탐지를 위해 단별량 시계열을 독립 feature로 고려하고 각각 두개의 graph attention layer를 병렬 배치하여 temporal, feature dimenstion에의 dependency를 봄.
또한 우리는 forecasting-based model 과 reconstruction based modle을 jointly optimize함. 이는 single timestamp prediction과 전체 tieme-series의 reconstruction을 혼합하여 더 나은 time-series representation을 할 수 있게 함
Introduction
단변량 시계열의 이상치 탐지 알고리즘은 하나의 metric에서는 잘 작동하지만, 전체 시스템에 대해서는 탐지가 어려움.
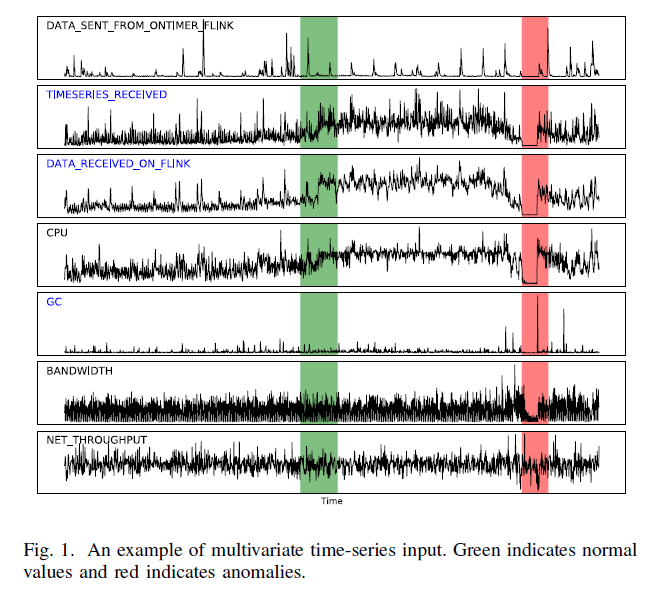
예시와 같이, 시계열에서는 시계열의 다변량 간의 관계를 파악하여 이상치를 탐지하는 것이 매우 중요함.
Malhotra et. al 은 LSTM-based의 encoder-decoder Network를 제시하여 시계열의 reconstruction probabilities를 모델링하고 이 error가 multiple sensor들에서 에러를 디텍트 하는데 사용됨
Hundman et, al 은 LSTM을 prediction error를 기반으로 한 다변량 시계열 이상치 탐지 연구를 진행함
OmniAnomaly는 stochastic recurrent neuarl network를 사용하여 다변량 시계열 modelling data 분포의 normal pattern을 latent variable을 활용하여 획득함.
본 연구는 이전 연구들에서 multivariate correlations를 explicit 하게 capture하지 않았으므로, 이것을 개선하여 improvement를 진행함
Solution : MTAD-GAT(Multivariate Time-series Anomaly Detection via Graph Attention Network) 사용
contribution :
1. self-supervised 를 통해 multivariate-time series 문제 다루어 SOTA score 달성
2. 2개의 parallel 한 graph attention (GAT)를 활용하여 다른 time-series와 timestamp의 relationship을 이전의 정보가 불필요한 상태에서 찾음.
3. forecasting(single time-stamp prediction 에 목적) 과 reconstruction(entire time-series 의 latent representation 에 목적) 기반의 모델을 joint optimizing target으로 둠
4. 우리의 네트워크는 interpretability가 있고, 이는 attention score로 human intuition과 상관관계가 있음.
5. Code와 datset은 github에 open되어 다른 work에 사용가능
Related work
Univariate Anomaly Detection
Hypothesis testing, waveltet analysis, SVD, ARIMA
Netflix : PCA를 통한 이상치 탐지
Twitter : Seasonal Hybrid Exteme Studyt Deviation test
DONUT : unsupervised anomaly detecion method based on Cariational Auto Encoder and SR-CNN - Spectral Residual 과 CNN을 통해 SOTA 달성
Multivariate Anomaly Detection
1) Forecasting based models
prediction error 를 통해 이상치 탐지를 진행
LSTM-NDT : unsupervised 및 non-parametric thresholding을 제시
Ding et. al : real-time 이상치 탐지 알고리즘으로 Hierarchical Temporal Memory(HTM) and Bayesian Netwrok 기반임
Gugulothu et. al : non-temporal dimension reduction 및 recurrent auto-encoder를 통해 end to end learning framework 제시
DAGMM : temporal dependency 고려하지 않고 이상치 탐지 고려하여 단지 전체의 observation을 인풋으로 함.
2) Reconstruction-based models
Latent variable을 통해 entire time-series를 represent 하게 학습을 진행
Pankaj et. al : LSTM-based Encoder-Decoder framework로 normal 시계열 data의 representation 학습
Kitsune : unsupervised로 feature를 instance로 mapping을 하고 decoder를 통해 reconstruction
MAD-GAN : entire variable set 을 고려하여 latent interactions를 capture함
GAN-Li : GAN으로 학습된 discriminator에 실제와 fake를 넣어 residuals을 만듦
LSTM-VAE : LSTM을 variational auto-encoder에 integrates 하여 singals를 fuse 하고 분포를 재구성함. temporal dependencies를 latent space에 LSTM encoder를 통해 압축함
OmniAnomaly : deterministic method로 unpredictable instances 때문에 실수할 가능성이 높으므로 stochastic model을 제시하여 다변량 시계열 이상치탐지를 진행함. 정상 pattern을 stochastic variable connection과 plannar normalizing flow를 통해 normal pattern 을 capture함
Methodology
Problem Definition 1: 다변량 시계열 input이 x ∈ R^(n×k) 라면, n은 timestamp의 maximum length이며, k는 input feature 갯수임
long-time series를 위해 fixed-length inputs을 슬라이딩 윈도우를 통해 만들었음. y ∈ R^n, yi ∈ {0, 1} 일때,ith timestamp is an anomaly라고 탐지했었음.
우리는 inter-feature correlations와 temporal dependencies를 2개의 graph attention networks를 parallel 하게 모델링함. 그리고 GRU(Gated Recirrent Unit) 네트워크를 활용해 long-term dependency를 봄
또한 forecasting 및 reconstruction 기반의 모델의 이점 두가지 모두를 합하는 joint objection function을 사용함.
A. Overview
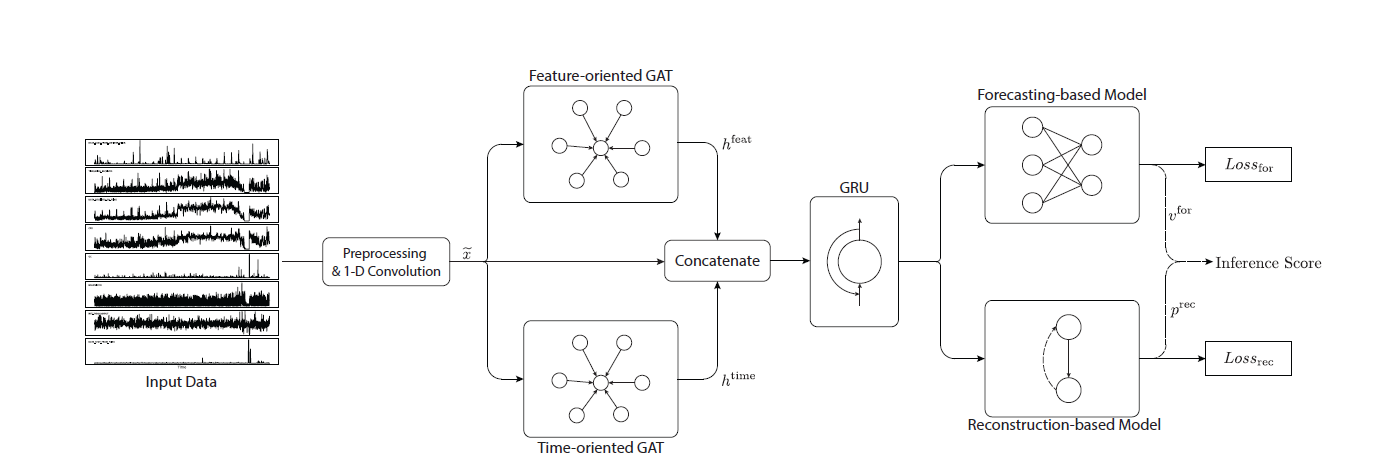
1) 첫번째 레이어에 1-D convolution을 커널 사이즈 7을 활용하여 고차원의 feature 추출함
2) 2가지 GAT layer에 input으로 넣어짐
3) 2 GAT layer output을 concatenate 한 뒤 GRU 에 feed함
4) GRU output을 forecasting 과 reconstruction model에 넣어서 final result를 가짐
B. Data Preprocessing
각각의 time-series data에 대해 normalization 과 cleaning 을 진행
normalization : training 과 testing set
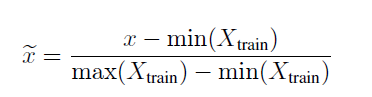
cleaning : training set
SOTA 단변량 anomaly detection method 에서 Spectral Residual 을 통해 이상치를 탐지하고 그 time stamp 주변을 normal 로 대체함
C. Graph Attention
GAT 는 Graph Attention으로 arbirary graph의 nodes 사이의 relationship을 모델링함. 그래프가 n 노드가 주어졌더라면, {v1, v2, · · · , vn}, vi는 각 노드의 feature vector 임
GAT 레이어는 output representation을
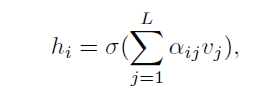
다음 식으로 계산함
hi : node i 의 output representation
σ : 시그모이드 활성함수
αij : attetnion score로 노드 j에서 i로부터의 contribution을 측정함. L은 노드 i 근처 노드의 갯수
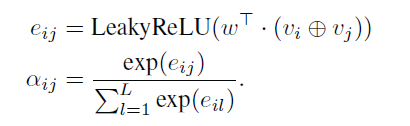
⊕ : 2개의 node representation concatenation
w ∈ R^(2m) : learnable parameter의 column vector로 m은 각 node의 feature vector의 차원
2개의 graph attention layer의 2가지 타입을 활용함
-
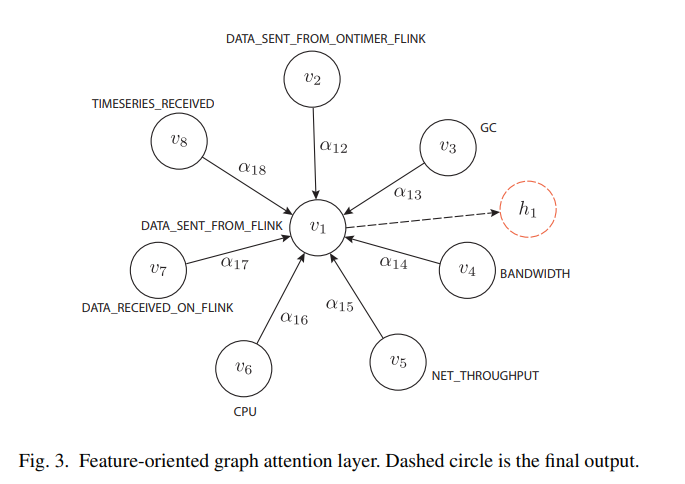
Feature oriented graph attention layer
다변량의 시계열을 graph로 다루고, 각 node는 특정 feature를 represent하여 각 edge는 2개의 상호작용 feature의 relationship을 나타냄.
각 노드 xi = {xi,t|t ∈ [0, n]} 이므로, k 노드가 있고, timestamp의 수는 n, k는 mulicariate features의 수가 됨.
-
Time-oriented graph attention layer
temporal dependency를 capture하기 위해 사용하는데, 모든 타임스탬프를 슬리아딩 윈도우를 하여 complete graph로 만듬. node xt는 time stamp t에서의 feature vector를 나타내며 주변의 노드는 현재 슬라이딩 윈도우의 모든 타임스탬프를 포함함. 이는 트랜스포머와 비슷하여 모든 sequence 의 word는 fully connected self attention operation으로 모델됨. feature oriented graph attention layer의 아웃풋은 kxn의 행렬이며, 총 k노드의 n 차원을 의미하며, time-oriented graph attention layer는 nxk의 크기를 가지고 있고, 우리는 이것을 concatenate하여 nx3k의 크기 shape로 나타냄.
D. Joint optimization
forecasting based model과 reconstruction based model 두 가지를 jointly optimization을 하기 위해 각 모델의 파라미터를 동시에 업데이트함. 로스 펑션은 두가지를 합한 것임.
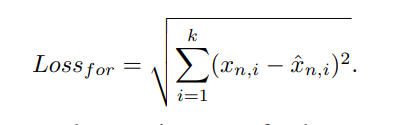
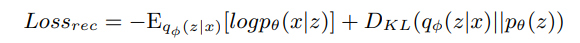
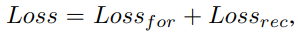
E. Model Inference
프리딕션 벨류와 복원 확률값이 나오므로, anomally detection을 위해서는 전체적인 effectiveness를 높여야 함. interference score를 구해서 이것이 threshold 값보다 크다면 anomaly라고 규정함
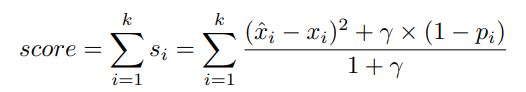
x햇과 x의 차이는 forecasting 값과 실제 값의 차이, (1-p) 는 복원 모델에서 abnormal 확률, 감마는 하이퍼 파라미터로 두가지를 combine하기 위한 값임. grid search로 찾음
Experiments
A. Datasets and Metrics
SMAP (Soil Moisture Active Passive satellite)
MSL (Mars Science Laboratory rover)
TSA (Time Series Anomaly detection system)
precision, recall and F1-score, AUC scores
B. Setup
Omni Anomaly, LSTM-NDT, KitNet, DAGMM, GAN-Li, MAD-GAN, LSTM-VAE와 비교함
n=100인 sliding window 를 모든 모델에 동일하게 사용함
감마값은 0.8을 grid search를 통해 찾음
hidden dimension 사이즈 : GRU layer (d1), fully-connected layers (d2), the VAE model (d3) : 300으로 emprically 정함
아담 optimizer 사용, 100 epoch로 학습하였으며, learning rate 는 0.001
C. Comparison with SOTAs
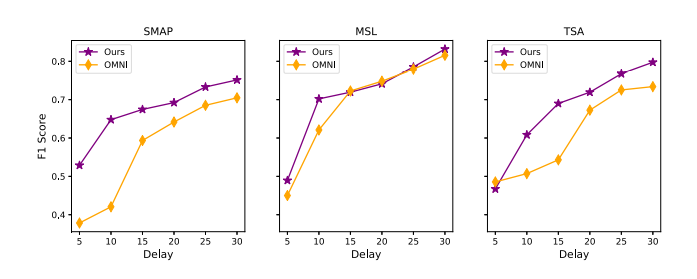
SOTA모델보다 F1 score가 더 높음을 알 수 있음.
OmniAnomaly는 feature correlation을 explicitly하게 강조하지 않아 본 연구의 모델이 더 성능이 좋음
DAGMM는 temporal information을 고려하지 않아 본 연구 모델의 성능이 좋음
LSTM-NDT 은 unpredictable 한 dataset에서는 잘 작동하지 않음. 즉, forecasting-based and reconstruction based model 들의 adventage를 잘 활용해야 함을 알 수 있었음.
D. Evaluation with Different Delays
모델이 빠르게 anomalies 를 detect 하는 것 또한 중요함.
전체 segment를 true positive 라고 가정하고, anomaly detect point가 정확한 것은 첫 anomaly segment이후 최대한의 delta로 timestamp가 이루어져 있다는 의미
딜레이 delta가 올라갈수록 F1 score가 올라가는 것을 알 수 있고, delay가 충분하다면 비슷한 성능을 보이게 됨. 따라서 본 모델은 delay 가 작을때 성능이 좋음을 확인할 수 있으며 delta=10일때 53.98%, 13.04%, 19.93% 의 차이를 보임
따라서 본 모델은 실시간으로 loss 없이 anomalies를 detect 할 수 있음을 보여줌
Analyses
A. Effectiveness of Graph Attention
disabling the feature-oriented GAT layer와 time-oriented GAT layer를 하여 2개의 graph attention 의 영향을 봄
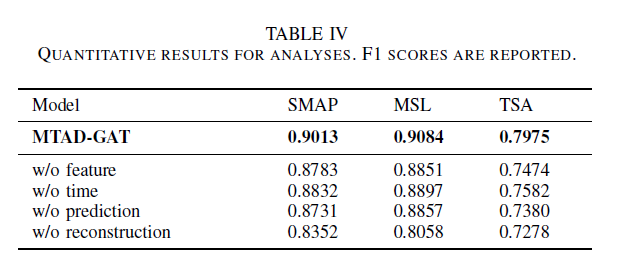
F1 score가 각각 feature, time이 없을 때 낮아짐을 알 수 있음.
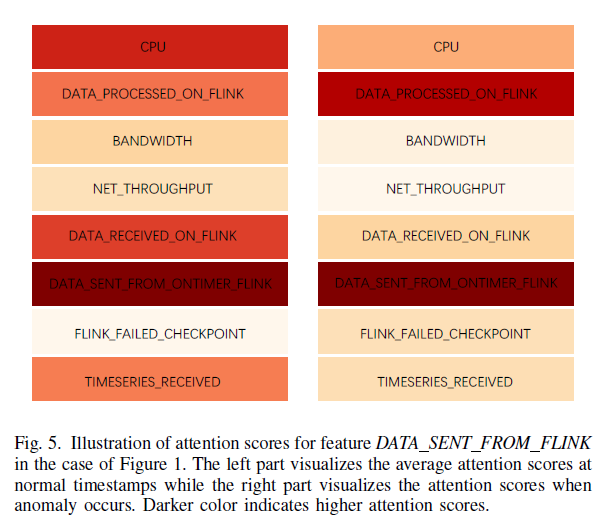
또한 attention score가 anomalies가 발생했을 때, attention scores가 CPU, data-processed on flink 보다 data-sent from ontime flink 보다 적은 correlation을 가짐을 알 수 있음. 즉, garbige collection issue가 있다는 뜻이고, reprocessing 이 계속 진행되어 output matries 에 spike를 일으킴 이는 DATA SENT FROM FLINK가 inconsistency를 보이는 것을 알 수 있음
B. Effectiveness of Joint Optimization
본 연구의 모델을 single optimization counterparts와 비교
w/o prediction, w/o reconstruction 보다 original model이 더 f1 스코어가 높은것을 확인했었음
Forecasting based model : time-series의 randomness에 robust
Reconstruction based model : perturbation & noise에 robust
따라서 이것을 jointly optimization 하는 것이 f1 score도 높고 anomaly detection에 효과적
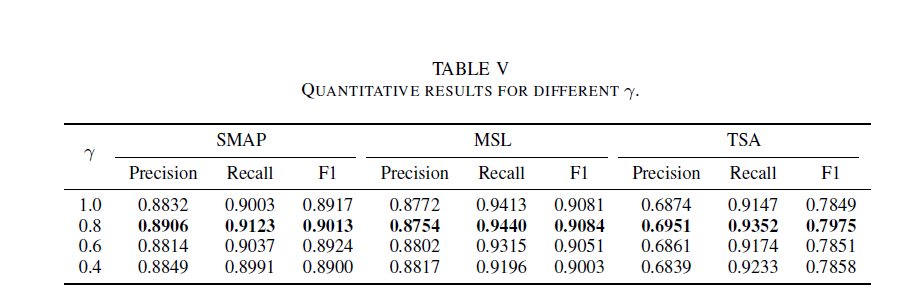
C. analysis of γ
forecasting based error 와 reconstruction-based probability를 합치는 파라미터를 구함
precision, recall, and F1을 감마값에 대해 구함
D. Anomaly Diagnosis
inference score를 크게 하는 8개의 feature를 select
TSA에 대해 700개의 qulified instances를 label하고 HitRate@P% and NDCG 를 사용하여 anomaly detection 성능을 측정함
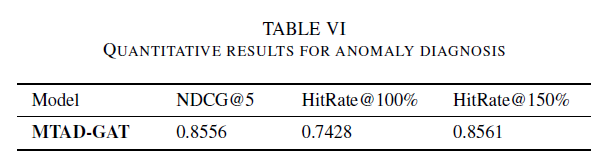
70%의 true root cause를 capture 할 수 있었고, top5의 root cause를 알고리즘을 통해 학습함
실제 시나리오에서는 다른 feature들간의 관계가 변하는것에 따라 root cause가 될 수 있음.
Fig.1 에서 dip 이 있다면, output stream에서는 lower value가 나옴을 예측할 수 있음. 그러므로 feature DATA SENT FROM FLINK and
DATA RECEIVED FROM FLINK가 consistent tendency를 가져야 함. 만약 둘이서 abnormal correlation이 있다고 하면, 2개의 feature가 root cause의 potential이 있다고 봄
우리의 모델은 이것을 잘 캡쳐하여 복잡한 환경에 대해 잘 대처함을 알 수 있음
Case study
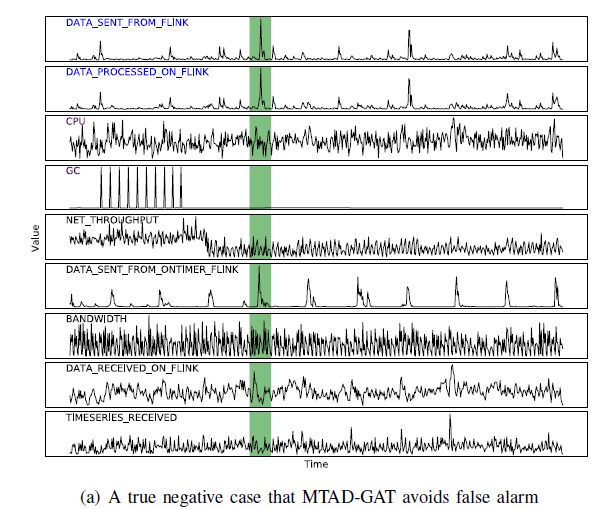
(a)에서는 본 모델의 true negative 케이스임. green에서 몇몇 spike를 보임. 단변량에서는 error 로 출력할 것
feature relation에서 다른 것은 변하지 않음을 알 수 있음. DATA SENT FROM FLINK and DATA PROCESSED ON FLINK 에서 스파이크가 있어도 normal로 봄
시스템을 모니터링하는데 있어서 false alart를 줄일 수 있음

(b)에서는 false positive case임. FLINK CHECKPOINT DURATION and
CPU에서 anomalies를 detect함. 하지만 이것은 increase of input data volume에 의해 일어났으며, DATA RECEIVED ON FLINK and
DATA SENT FROM ONTIMER FLINK가 일정함을 알 수 있음. unsupervised anomaly detection algorithm가 anomaly라고 detect 할 수 밖에 없었음
Conclusion
graph attention network for multivariate time-series anomaly
detection을 위한 novel framework를 제시함
feature-wise and temporal relationships
of multivariate time-series and leveraging a joint optimization를 이용하여 3 dataset에 대해 SOTA보다 더 좋은 성능을 보여주었으며, anomaly diagnosis 를 root casue 통해 할 수 있음을 보여줌
추가적으로 도메인 prior 지식 및 피드백을 통해 퍼포먼스를 높일 수 있을 것으로 예상됨
