Self-supervised Equivariant Attention Mechanism forWeakly Supervised Semantic Segmentation
2023 하계 논문세미나
Abstract
이미지에서 weakly- supervised semantic segmentation은 최근에 많은 연구가 되어 왔다. 최근 CAM(Class Activation Map)이 발전된 연구이다. 하지만, CAM은 full과 weak supervisions 사이 간극 때문에 object mask로써 기능하기 어렵다. 본 연구에서는 self-supervised equivariant attention mechanism(SEAM)을 제안한다. 이는 추가적인 지도학습을 통해 이 간극을 줄인다. 우리의 방법은 관측에 기반하는데, 이는 fully supervised semantic segmentation을 할 때 equivariance가 implicit한 constraint이다. 픽셀 레벨의 라벨들과 data augmentation 된 것들은 동일한 공간 변환을 수행한다. 하지만 이러한 constraint 는 CAM에서 이미지 레벨의 supervision 시에 잃어버리게 된다.
따라서, 우리는 pre-trained 된 CAM에 consistency regularization을 하는 모델을 제안한다. 또한, PCM(Pixel Correlation Module)을 제안하는데 이는 문맥이 어떻게 보이는지에 대한 정보를 활용하여 현재 필섹의 예측을 주변 결과와 비교해 수정함으로써 CAM의 consistency를 더 향상시킨다.
Introduction
Semantic segmentation은 다른 이미지 분류나 detection과는 다르게 픽셀 레벨의 라벨이 필요하고, 이는 시간이 많이 소요되며 코스트가 많이 들어가게 된다. 최근에 weakly-supervised semantic segmentation(WSSS)가 많이 연구되어 왔는데 이는 weak supervision을 활용하는 것이다. 즉, 이미지 레벨의 classification labels와 scribbles, 바운딩 박스 등등이 fully-supervised와 동일한 segmentation이 이루어지기를 목표로 하고 있다.
최근 진보된 WSSS 기법에는 CAM을 기반으로 하는데, 이는 이미지 분류 라벨을 기반으로 한다. 하지만, CAM은 백그라운드를 분류하는데는 취약하다. 또한 augmentation 변환 방법에 따라 CAM의 결과가 달라진다.
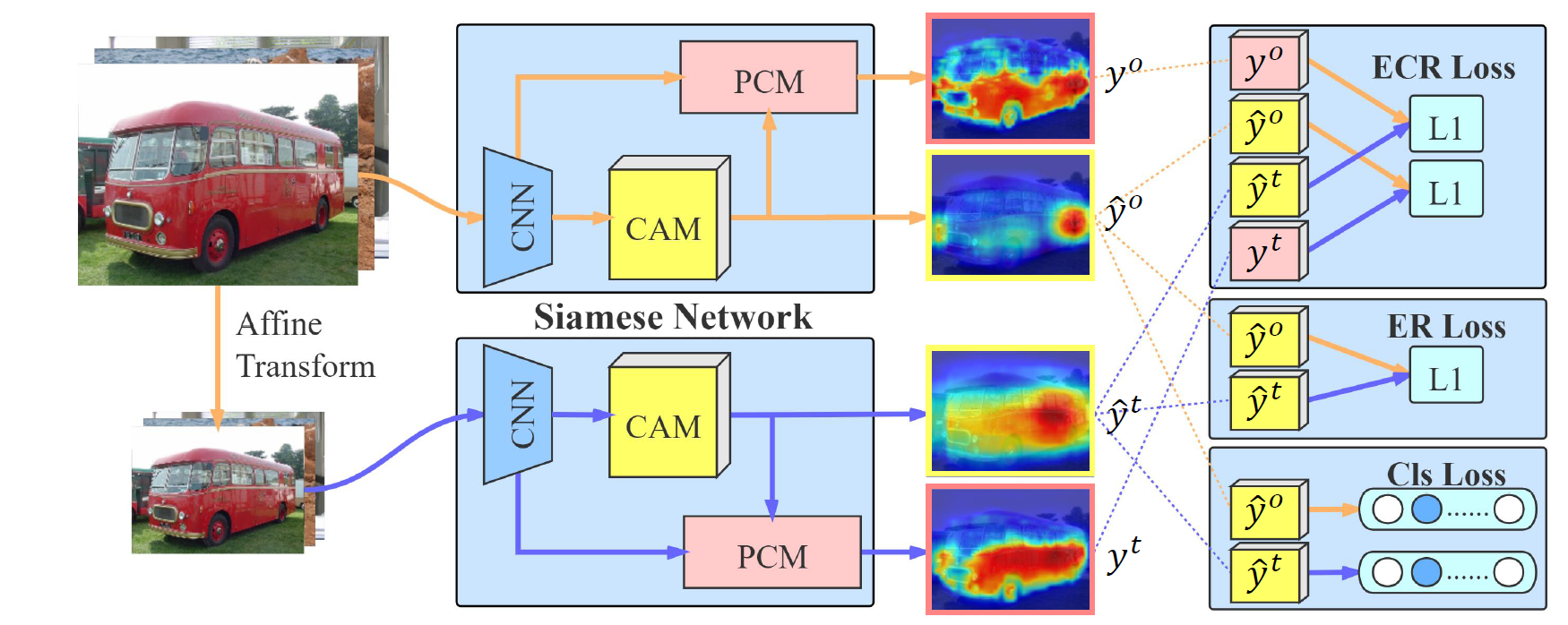
우리가 제안하는 self-supervised equivariant attention mechanism(SEAM)은 이러한 갭을 줄인다. CAM의 결과물에 다양한 변환을 하고, consistency regularization을 통해 self-supervision 을 제공한다. 또한, pixel correlation modue(PCM)을 통해 각 픽셀마다의 appearance 문맥 정보를 획득하여 CAM을 affinity attention maps로 변환한다. SEAM은 equivariant cross regularization(ECR)로스를 사용하며, 오리지널 CAM과 revised된 CAM은 다른 branch에서 regularization을 진행한다. 메인 contribution은 다음과 같다.
1. SEAM을 제안하며, PCM을 통해 supervision gap을 줄인다.
2. siamese 네트워크 아키텍처를 디자인하여 (ECR)로스를 통해 PCM과 self-supervision을 효과적으로 융합하고, CAMs를 over & under activated된 부분을 줄인다.
3. PASCAL VOC2012 실험을 통해 알고리즘이 이미지라벨 annotations에 SOTA임을 보인다.
Related works
2.1 Weakly Supervised Semantic Segmentation
Fully supervised learning 과는 다르게, WSSS는 weak labels로 네트워크 학습을 한다. Bounding box, scribbles, image-level classification 등이 있다. 이미지 레벨의 classification 라벨들을 통해 모델을 학습하는데 활용한다. 대부분은 CAM을 segmentation mask를 근사하는데 활용한다. Adversarial erasing 이 대표적으로 CAM 을 expansion 하는 방법인데, 네트워크를 feature들을 다른 regions에서 학습하고 activation을 확장하는 형식이다.
2.2 Self supervised Learning
annotated labels 대신에, self-suypervised learning은 annotation 없이도 학습이 가능하게 한다. position prediction, spatial transformation prediction, image inpainting 들과 같은 방법들이 있었다. 이것들이 확장되어 gan을 만들었다. 이것들은 생성된 데이터들을 통해 더 robust한 representation을 학습할 수 있게 되었다.
fully와 weakly supervised semantic segmentation에 많은 갭이 있는것을 고려하여 우리는 additional supervision을 찾아서 이 갭을 줄여야 한다. 이미지 레벨의 classification 라벨은 오브젝트의 경계면에 잘 맞아야 하는데, 본 연구의 모델은 equivariance of ideal segmentation function을 통해 추가적인 정보를 제공한다.
Approach
motivation
: 각 이미지 샘플
= : 파라미터 를 가지는 segmentation function
: pixel level segmentation mask
: image level label
WSSS 기반의 접근 방법론은 분류와 segmentation의 최적 파라미터는 임을 가정하낟. 그러므로, classification 네트워크를 학습한 뒤 풀링 펑션을 제거하여 segmentation을 진행한다.
그러나, 이 둘의 특성은 다르기 떄문에 다른 equvariant 한 식을 제시
SEAM은 어테션 메카니즘으로 self-attention과 equivariant regularization을 결합한다.
Equivariant Regularization
data augmentation을 하면서, fully supervised semantic segmentation은 픽셀 레벨의 라벨들이 있으며, 인풋 이미지와 같은 transformation이 진행된다. 이것이 네트워크의 implicit equivariant constraint로 작용하고 다음과 같은 식이다.
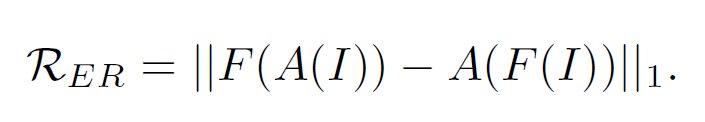
: 네트워크
: spatial affine transformation (ex : rescaling, rotation, filp 등)
한 갈래는 네트워크 아웃풋의 transformation을 적용하고, 다른 갈래는 같은 변환을 통해 이미지 warp를 진행한다.
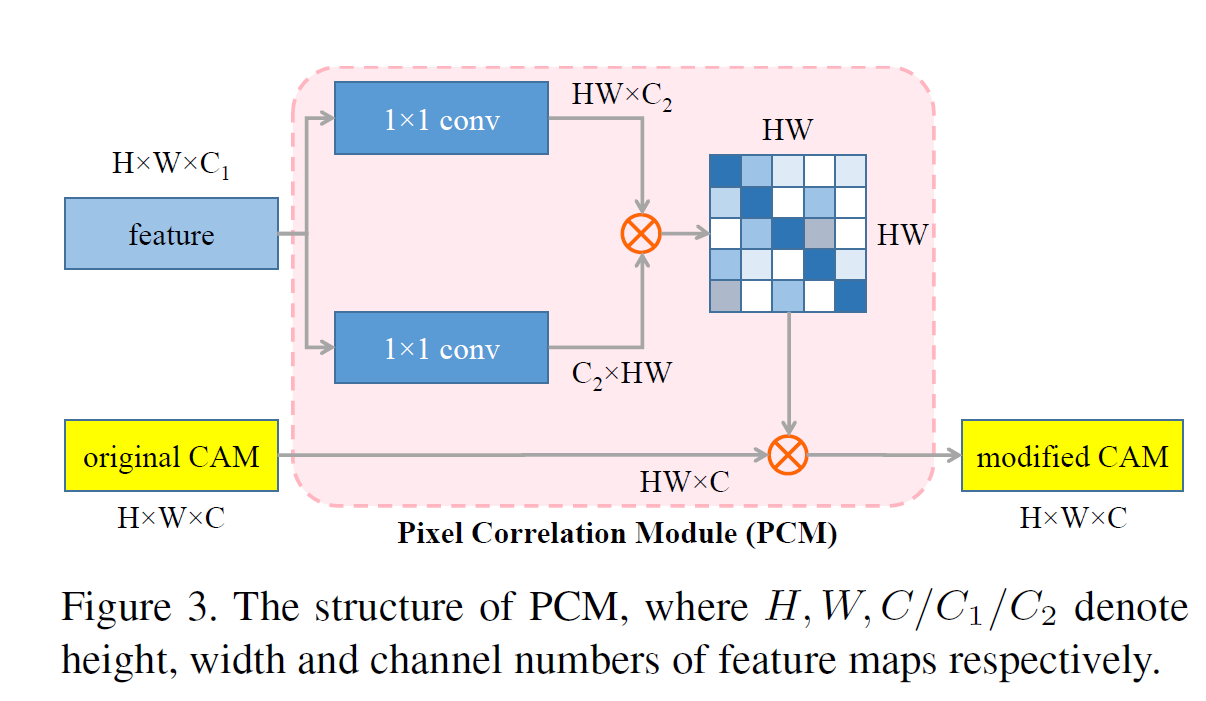
Pixel Correlation Module
Equivariant Regulartization은 네트워크 학습에 추가적인 정보를 제공하지만, convolution 레이어로만 이것을 처리하기 힘들다. Self-attetion은 context 정보를 획득하기 용이하고, pixel-wise의 예측 결과를 정제한다. 따라서 CAM refine을 위해서 self-attention을 결합하면 다음과 같은 식이 나온다.
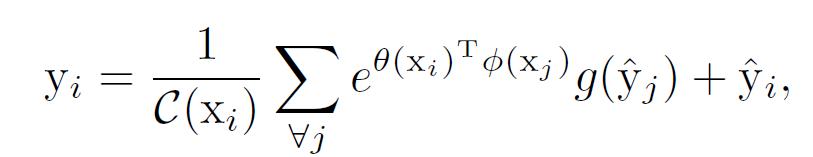
: original CAM
: revised CAM
original CAM은 residual space 상으로 g 함수에 의해 임베딩된다.
CAM을 문맥 정보로 정제하기 위해 PCM을 제안하는데, 네트워크 끝에 각 픽셀의 low-level의 피처를 통합한다. 픽셀간 feature의 유사도를 평가하기 위해 코사인 거리를 활용한다.
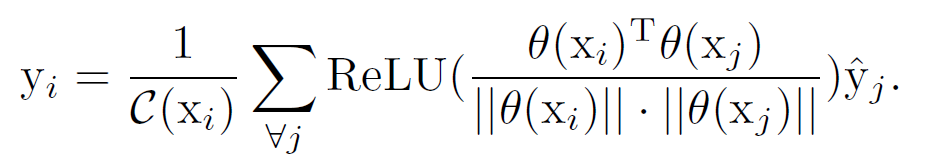
위 식은 다음과 같이 변환된다.
전체 프레임워크는 다음과 같다.
Loss Design of SEAM
이미지레벨의 라벨 은 인간이 anntated 한 것이다. 우리는 fglobal average pooling layer를 네트워크 끝단에 붙여 예측 벡터 z를 이미지 classification을 진행하고, multi-label 의 soft 마진 로스를 채택하여 네트워크를 학습한다. 분류 로스는 다음과 같다.
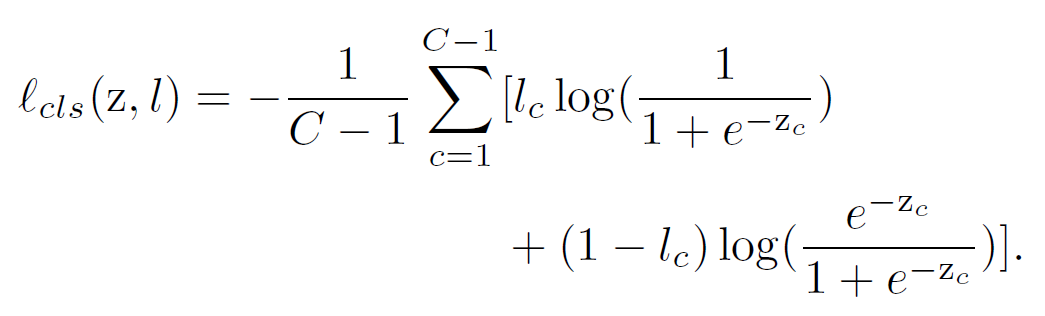
: 오리지널 인풋 이미지 branch로부터 생성
: transformed 이미지 branch로부터 생성
global average pooling layer는 이 둘을 예측 벡터 , 로 변환
이 둘을 통해 classification 로스 계산
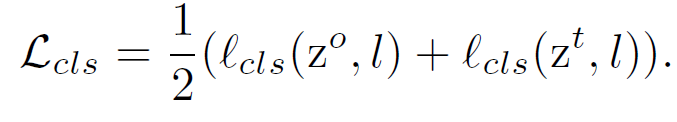
ER loss (Equivariant regularization) 는 다음과 같음
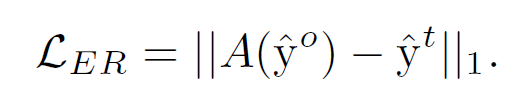
하지만, 이렇게 정의를 한다면 문제점이 생긴다. 이는 PCM이 local minimum에 빠르게 빠져 모든 픽셀들이 같은 class로 예측이 될 가능성이 많다는 것이다. 그러므로, equivariant cross regularization (ECR) 로스를 다음과 같이 설정한다.
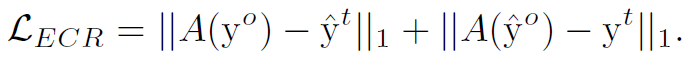
따라서, SEAM의 최종적인 로스는 다음과 같다.
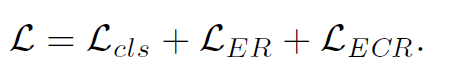
Experiments
Implementation Details
PASCAL VOC 2012 dataset with 21 class annotations 사용 -> 20개의 오브젝트가 있으며, 1개의 백그라운드가 있음.
SBD의 training set을 추가
네트워크 학습에는 이미지 레벨의 분류만 가능. ResNet38이 backbone network로 사용됨.
네트워크 학습 과정에서 gradient back-propagtaion cutoff하여 PCM 과 네트워크학습이 동시에 학습되는것을 방지함. 이를 통해 PCM이 context refinement 모듈로써 작동되게 하며, 네트워크 백본으로 학습될 수 있게 함.
추론과정에서 본 연구의 SEAM이 shared-weight 이므로 multi-scale 및 flip test로 pseudo segmentation labels를 만듦.
Ablation Studies
SEAM을 검증하기 위해 높은 pseudo label accuracy 는 CAM과 ground truth segmentation masks의 가장 좋은 match를 만들어낸다.
Comparison with Baseline:

베이스라인 대비하여 SEAM에 사용된 모듈들이 다 사용되면 56.83%까지 평균 성능이 향상된다.

이 결과를 시각화 하면, c의 베이스라인 대비 d가 over-activataion 을 더 적게 하며, 더 정확한 activation 렴을 보였다. 또한 mask가 더 ground thruth 에 가깝게 된다.
Improved Localization Mechanism :

weakly supervised localization mechanism 인 GradCAM과 ++ 을 비교하였다. fully 와 weakly supervision gap을 GradCAM에서는 잘 줄이지 못했다. SEAM을 통해 improved localization methods가 적용되고, 이를 통해 segmentation 태스크에 적합하다고 볼 수 있다.
Affine Transformation:
affine transformation의 여러가지 candidate 는 다음과 같다.
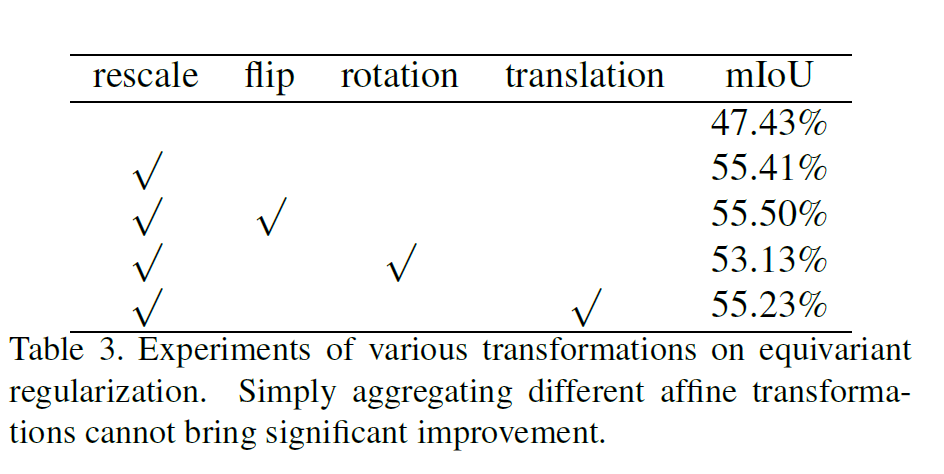
이 결과를 통해 여러가지 기법을 섞는것이 큰 정확도의 차이를 보이지는 않았다. 따라서 SEAM 은 단순히 resacle 만을 활용하였다.
Augmentation and Inference:
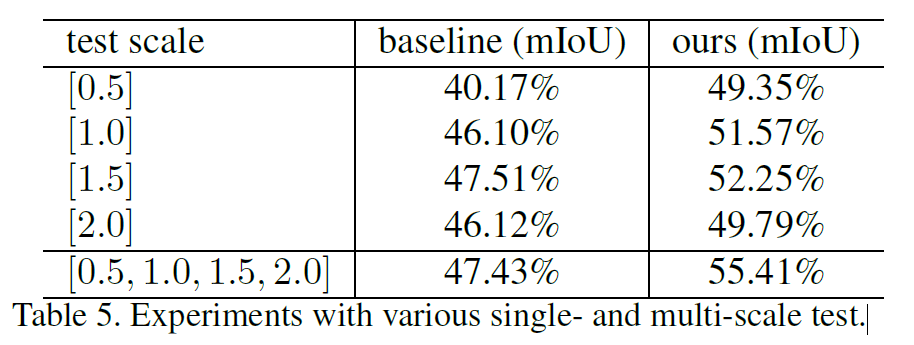
퍼포먼스를 높이기 위해 multi scale의 augmentation을 사용하였다.
Source of Improvement:
SEAM의 Improment는 activation의 over 혹은 under activation을 줄임으로써 보일 수 있다. 따라서, 다음과 같은 metrics를 정의하여 성능을 평가한다.
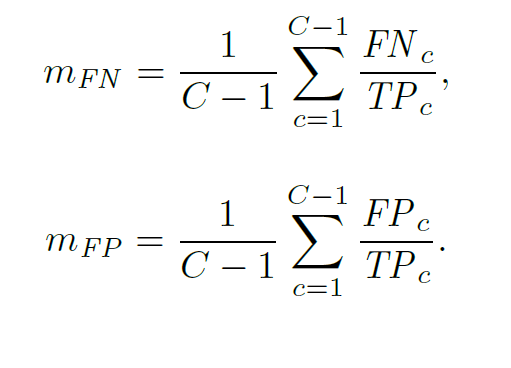
는 class c에 대해서 true positive pixel의 수
는 class c에 대해서 False positive pixel의 수
는 class c에 대해서 False negative pixel의 수
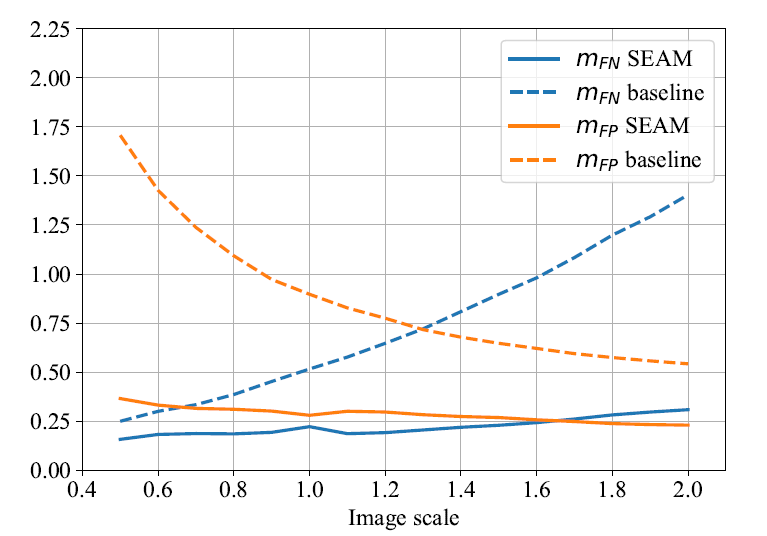
이 크면, CAM이 under-activated 되었음을 의미한다.
이 크면, CAM이 over-activated 되었음을 의미한다.
따라서 베이스라인 대비, 이미지스케일이 클 수록 SEAM이 over-activated 및 under-activated 에서 유의미한 성능 향상을 보였다.
Comparison with Stateofthearts
 이미지 레벨의 supervision을 진행한 sota 모델보다 더 진보된 성능임을 보였다. 또한 모델의 정확도 향상을 네크워크의 복잡성 혹은 saliency detection의 발전의 따른것이 아니고, self-supervised PCM으로 이룬것이 의의가 있다.
이미지 레벨의 supervision을 진행한 sota 모델보다 더 진보된 성능임을 보였다. 또한 모델의 정확도 향상을 네크워크의 복잡성 혹은 saliency detection의 발전의 따른것이 아니고, self-supervised PCM으로 이룬것이 의의가 있다.
또한 아래 그림과 같이 ground truth와 거의 비슷하게 작거나 큰 객체를 잘 분류함을 알 수 있다.

