Abstract
비전 기반의 defect recognition은 품질 보증을 위해 널리 사용되고 있다. 딥러닝 기반의 비전 recognition 방법이 accuracyt와 generality에서 기존의 방법보다 우세하다. 학습 비전 기반의 딥러닝 모델들은 많은 양의 라벨 데이터를 요구한다. 그러나, data annotation은 아주 많은 코스트가 들고 딥러닝 기반 방법론의 병목으로 작용한다. 본 연구에서는 generic defect detection 알고리즘을 제시하여 positive & negative samples를 학습하는 것 뿐만 아니라, 새로운 상품에도 잘 generalized 된다. 기존의 few-shot segmentation 방법론과 비교하여 본문의 방법론은 Industrial-5 데이터셋에서 최고의 성능을 보인다.
Introduction
최근 딥러닝이 컴퓨터비전에서 많은 발전을 이루었지만, 여러 task들은 많은 매뉴얼 라벨된 데이터를 학습 과정에서 필요로 했다. 이는 딥러닝을 실제로 산업 현장에서 적용하는데 큰 제약사항이었다.
이런 문제점을 해결하기 위해 다양한 시도들이 연구되어 왔다. reconstruction 방법론은 재구성을 통한 오차로 defect detection을 수행한다. statistical feature distribution 방법론은 정상 이미지의 feature distribution을 통해 defect detection을 수행한다. 이러한 방법들은 모델당 하나의 제품에만 적용 가능하며, defects를 탐지하기 위한 threshold 설정이 필요하다. 게다가 분포 기반은 pixel-by-pixel 연산을 수행하기 때문에 아주 느리다는 단점 또한 포함된다.
인간은 비정상 제품을 보지 않았더라도 빠르게 defect을 location화 하여 탐지한다. 이는 similarities와 differences 기반으로 탐지하는 것이다. 최근, metric learing 기반의 few-shot learning이 분류와 객체 탐지에 많이 활용되었는데, few-shot semantic segmentation에 활용되어 금속 표면 불량 탐지에 좋은 결과를 보였다. 그러나, 이러한 방법론은 불량과 비슷한 쿼리 이미지에서 특질을 뽑아내는것으로 불량을 탐지한다. 인간의 불량 탐지법과는 거리가 있으며, 새로운 제품에는 적용이 불가능하다는 단점이 또한 존재한다.
본 논문에서는, few-shot segmentation 으로 표면 결함 탐지를 정상과 비정상 제품의 차이를 비교해가는 방법으로 수행한다. 이는 새로운 제품에 라벨링이나 불량 샘플의 라벨링, 그리고 네트워크 모델의 재학습 없이 이루어진다. 본 연구의 메인 컨트리뷰션은 다음과 같다.
1. 정상과 비정상 제품 비교 기반의 few-shot segmentation 방법론이다.
2. industrial-5 데이터셋으로 few-shot segmentation을 진행하고, 다양한 ablation 실험과 비교 실험을 진행하였다.
3. L2 distance 기반의 계산 방법론이 few-shot 결함 탐지에 효과적이다.
4. few-shot semantic segmentation 방법론을 제안하여 industrial-5 데이터셋에서 최고의 성능을 보였다.
2. Related work
2.1. Image semantic segmentation
image semantic segmentation의 목적은 각 이미지의 픽셀의 라벨을 예측하는 것이다. Full-convolution network가 제일 초기 방법이며, 구조 전체가 convolution layer로 이루어져 있다. 이는 이미지를 arbitrary 사이즈로 분할하는 특징이 있다. Encoder-decoder 구조는 불량 탐지를 위한 유명한 semantic segmentation의 구조이다. 인코더는 convolution을 사용하고, semantic features를 얻기 위해 다운샘플링을 진행한다. Decoder는 업샘플링을 통해 feature들을 융합하고 segmentation 결과를 내보인다. 이러한 방법론들은 데이터가 충분히 많이 존재하는 상황에서는 좋은 결과를 보였지만, few 데이터인 경우에서는 정확도가 많이 떨어졌다.
2.2. Few-shot image segmentation
few-shot image segmentation은 segmentation 예측을 단지 몇개의 학습 샘플만 존재할때 수행하는 방법론이다. Meta-learning 과 metric기반의 learning 방법론이 few-shot image segmenatation에 사용되어왔다. 메타학습의 목적은 새로운 카테고리에도 같은 문제를 해결할 수 있는 방법론을 연구하는 학문이다. Metric learing은 semantic segmentation을 generic similarity 함수에 의해 수행한다. 최근에, few-shot semantic segmentation 방법론이 metric learning 기반하여, 쿼리 이미지와 서포트 이미지의 타겟 피처간의 similarity를 사용하는 등의 방법이 연구되어 왔다. 그러나 이러한 방법론은 라벨을 representative 하는 defect을 찾아야 하는 문제점ㄷ이 있으며, 또한 알고있는 카테고리에서만 결함 탐지가 가능하다. 그러므로, 우리는 결함 탐지를 정상 제품 이미지와 결함 제품 이미지를 비교하면서 defect을 찾을 것이다.
2.3. Surface defect detection
표면 불량 판정은 스크래치, 크랙, 오일등의 결함을 테스트하는 것이다. 기존의 방법은 너무나 많은 라벨링 코스트를 요구하였다. 또한 shallow feature를 바로 사용하기 떄문에 복잡한 백그라운드나 조명 변화등에서 탐지 능력이 떨어졌다. 따라서 지도학습 기반의 결함 탐지 방법론의 문제를 해결하기 위해 weakly-supervised 방법론 및 unsupervised, few shot learning등이 대두되었다.
Task description
2가지 데이터셋
: 학습셋, 을 포함함
: 테스트셋, 를 포함함
메타학습 방법론을 따라가서, episodes에 따라 학습과 테스트를 진행함. 각 에피소드에는 랜덤하게 K 정상 샘플을 선택하고, 같은 카테고리에서 하나의 defective sample을 선택한다. 정상 샘플은 support set이라고 하고 {} 로 나타내진다. query set은 로, 는 결함 이미지 의 binary mask 이다. segmentation 모델은 처음으로 쿼리 이미지와 서포트 이미지의 관계를 학습한다. 그리고, 이 관계를 이용하여 쿼리 이미지를 semantically segment한다. 각 에피소드는 새로운 테스크이며, 우리는 네트워크를 iteratively 하게 학습하기 떄문에 학습 모델이 좋은 generalization capa를 가지게 된다. 학습 셋에서 segmentation 모델을 획득한 다음, test set에 검증을 진행하여 새로운 제품에도 같은 방법론이 적용되는지를 검증한다.
Our method
사람의 결함 감지는 정상과 이상 샘플들간의 similarities 와 differences 로 판별한다. 본 연구의 네트워크는 쿼리 이미지와 서포트 이미지의 similarities 와 differences간으로 비교한다. 그리고 쿼리 이미지의 defects를 segment 하는 basis로 사용한다. 이러한 전략은 쿼리 이미지에서 서포트 이미지에 가장 비슷한 포인트를 찾고, near-defect-free 쿼리 이미지를 얻는것이다. 이는 쿼리가 replaced된 것이고, 오리지날 쿼리 이미지에 마이너스를 하여 defect location을 검출한다. 더 좋은 결과를 얻기 위해 convolutional 네트워크를 활용한다.
MSNET에 기반하여, 다양한 distances, layers, scale of feature를 활용한다. 전체적인 데트워크 아키텍처는 아래 그림과 같다.
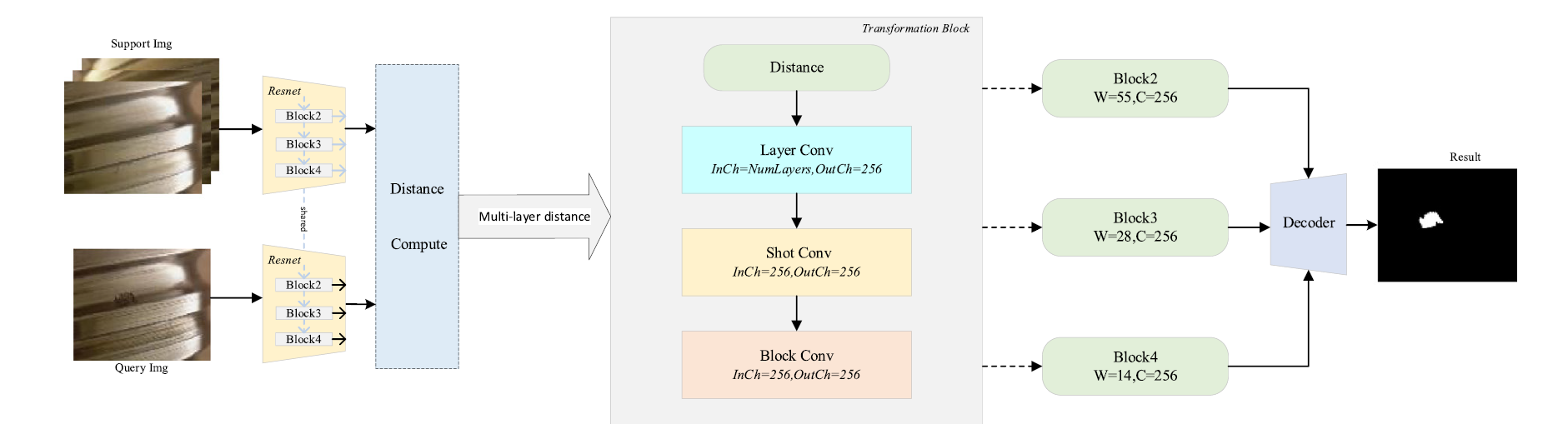
2개의 가지로 되어있는데, 거리 기반으로 결함의 위치를 탐지한다. shared backbone (이미지넷으로 pre-trained)은 멀티 스케일의 서포트, 쿼리 feautre를 뽑아낸다.
서포트 feature 
쿼리 feature 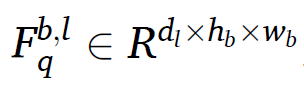
: layer l 의 feature 차원
, : 블록 B에서의 feature map 의 width, height
다른 제품에서의 distance를 같은 스케일에서 계산하기 위해 서포트 이미지와 쿼리 이미지의 feature map이 노말라이즈된다.
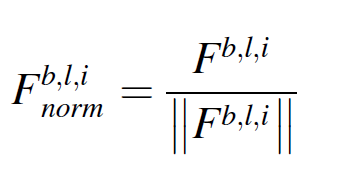
서포트 feature와 쿼리 feature의 similarity는 코싸인 similarity를 사용한다.
L2 distance로 결함의 위치를 찾기 위해 쿼리 feature map의 포인트에서 가장 비슷하게 대응되는 서포트 feature map에서의 포인트로 치환한다.
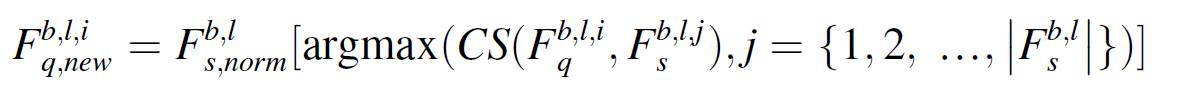
이 과정을 통해 L2 distance를 구하고, normalize 까지 진행한다.
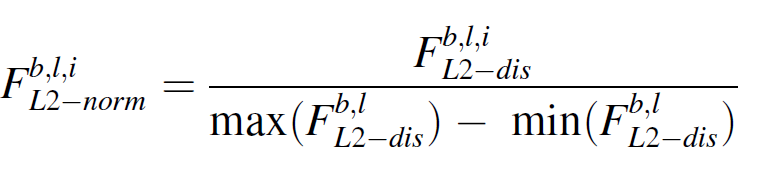
Transformation Block은 layer conv를 사용하고, 다른 레이어간의 featurers를 merge한다. 또한 shot-conv를 진행하여 다른 shot에서 얻어진 features를 merge한다. 또한 Block Conv를 통해 defect segmentation 결과를 해당 스케일에서 진행한다. 마지막으로, U-net 과 비슷한 디코더를 통해 multi-scale features를 통합하고 cross-entropy를 통해 네트워크를 최적화한다.
구체적인 알고리즘은 다음과 같다.

Dataset and metric
Industrial-5 데이터셋을 활용한다.
각각의 20개의 제품을 가지고 있다. positive sample 과 negative sample 로 나뉘어 있으며, negative sample은 pixel-level labeled binary mask가 있다.
Experiment
Comparative experiment
기존의 Few-shot segmentation 방법은 결함 타겟을 support로 두고, 쿼리 특질과 타겟 특질의 관계를 basis로 하여 결함을 탐지하였다. 그러나, 본 연구에서는 정상 이미지를 서포트로 두기 때문에 서포트 이미지에 라벨된 마스크를 가지고 있지 않는다. 그러므로, 기존의 few-shot segmentation 방법론과 비교하여 모든 서포트의 마스크가 foreground에 있다. 즉, 모든 마스크의 값은 1이다.

이 결과에서 우리의 방법론이 기존의 few-shot 방법론보다 outperform함을 보인다. 새로운 클래스에 대해 generalization ability 또한 성능이 좋다. 제안한 방법론의 distance calculation method가 결함 탐지에 매우 효과적임을 보여준다.
또한 기존의 few-shot segmentation 방법론은 쿼리 이미지에서 결함 타겟 서포트 이미지와 비교하여 타겟을 위치시킨다. 문제점은 새로운 제품의 일부의 정상 이미지에서 feature를 학습하여 쿼리 이미지에서의 결함을 탐지하는 것이다. 새로운 문제를 해결해야 하는 inconsistency 때문에 이 태스크가 잘 이루어지지 않는 것이다.
Support images quantity experiment
5-shot의 sementic segmentation 결과물은 다음과 같다.
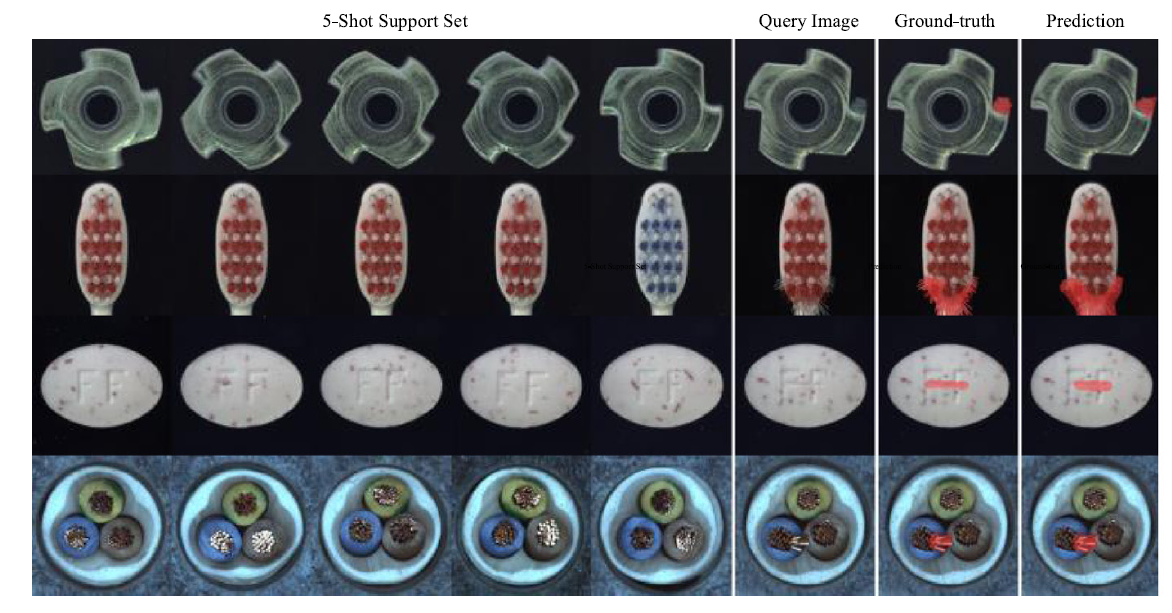
texture 과 color이 challenge할 지라도 정확하게 segmentation을 진행함을 알 수 있다.
shot 별로 지표를 보면 다음과 같다.
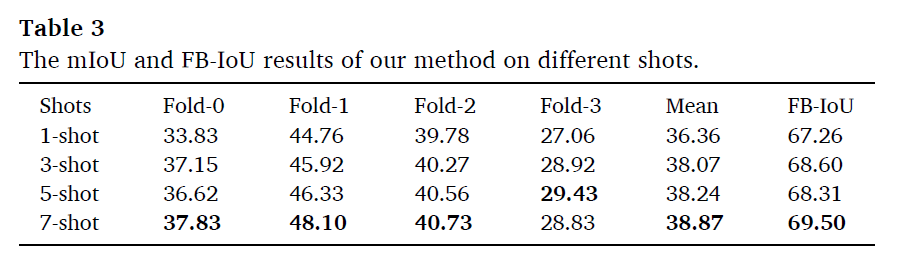
1shot 에서 3shot으로 갈 때 성능 향상이 매우 큼을 알 수 있다. 즉, 3개의 정상 제품의 샘플 만으로도 structure, brightness, color 등의 feature를 학습할 수 있음을 보였다.
Ablation study
제안한 distance가 다른 distance 에 비해 좋은점을 ablation study로 보였다.
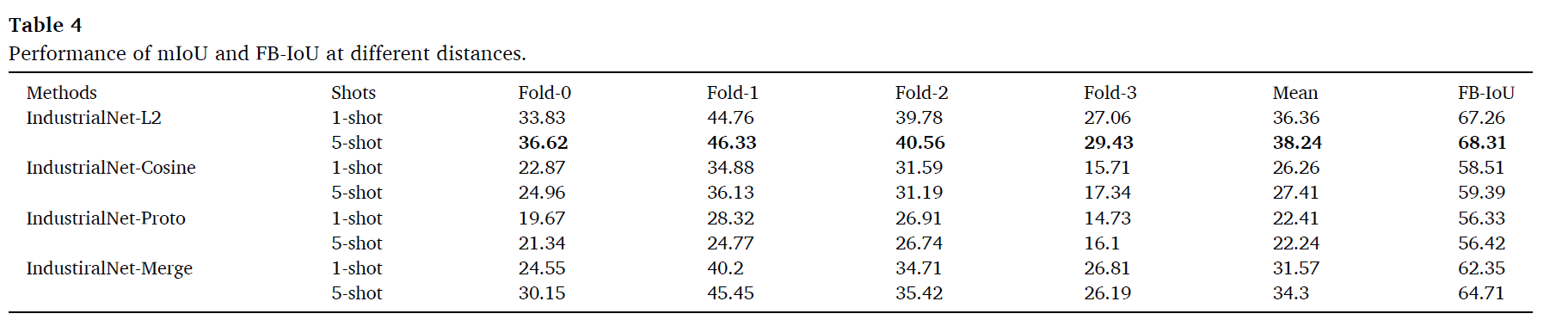
이러한 이유는 L2 distance가 노이즈에 강건하며, defect의 location을 더 정확하게 위치시켰기 때문이다. 이는 다음 activation map에서 설명이 된다.
Comparison by activation maps
각각의 distance의 activation map을 시각화 하면 다음과 같다.
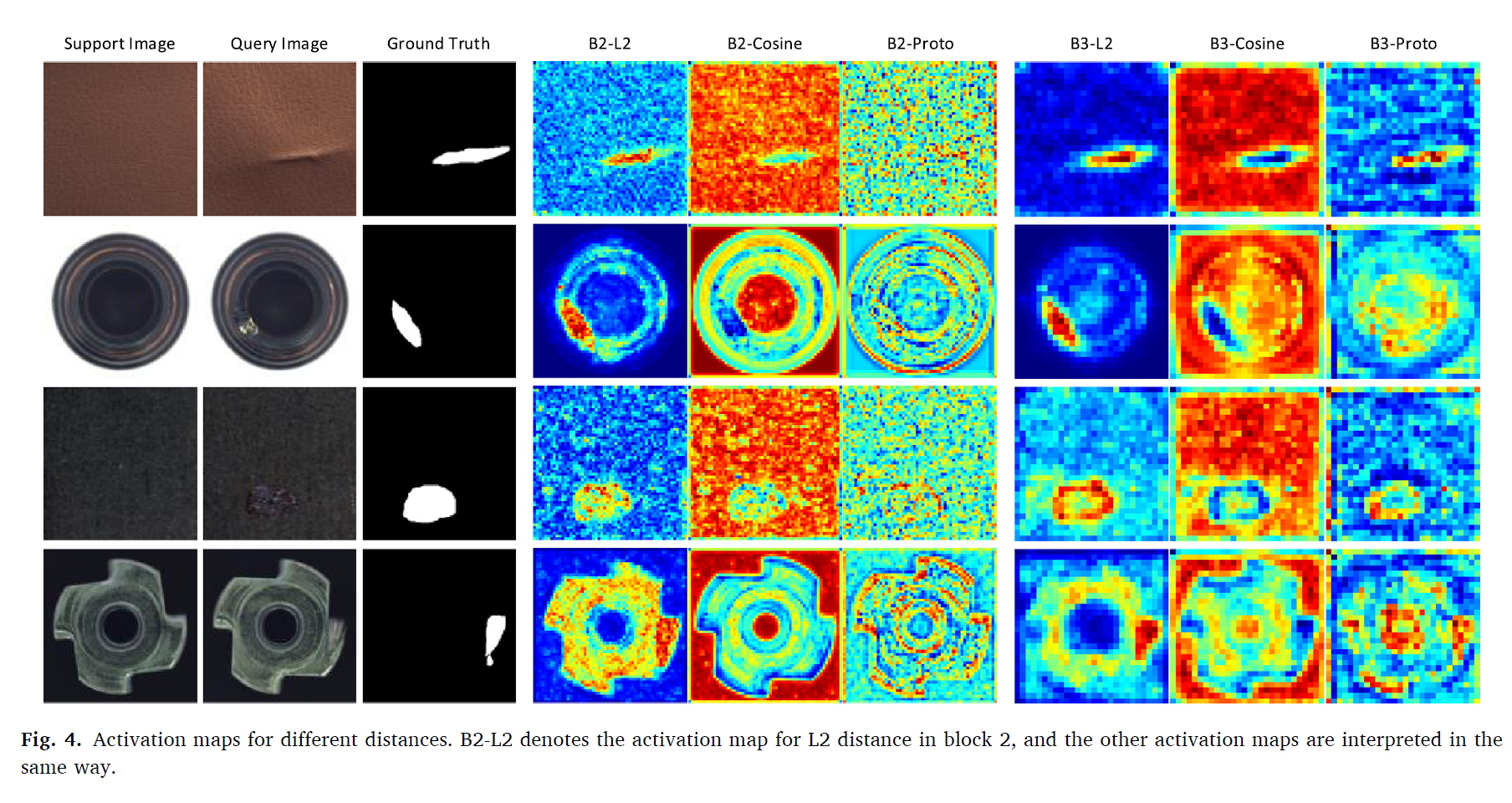
모든 3가지 distance 방법론이 defect을 위치시켰지만, L2 distance 방법론이 가장 적은 노이즈를 가지고 높은 정확도로, 민감한 경계면을 가지며 defect을 위치시킴을 알 수 있다. 따라서 L2 distacnce를 제안한 본 논문의 방법론이 few-shot 결함 탐지 태스크에 최적의 성능을 보임을 알 수 있다.
