Abstract
제조 분야에서 defective part를 찾아내는 것이 중요하지만, 이 연구는 정상 데이터만 사용하여 학습한다는 문제점이 있다. 클래스 별로 솔루션을 만들 수는 있지만, 궁극적인 목표는 다른 태스크에 자동으로 적용할 수 있는 모델을 만드는 것이다. 최적의 접근 방법론은 이미지넷 모델로 부터 ouliter detetcion model을 임베딩 하는 것이다. 본 연구에서는 이런 작업을 발전시켜 PatchCore 를 제시하는데, 정상 patch features 들의 representative 메모리 뱅크를 이용하는 것이다. PatchCore는 detection과 localization에서 SOTA 퍼포먼스를 보이면서 동시에 시간 퍼포먼스도 좋았다. MVTecAD 벤치마크에서 , AUROC를 99.6%를 달성하였으며, SOTA에 비해 에러를 반으로 줄였다.
Introduction
사람은 몇몇의 샘플만 보더라도 정상 범주의 variance 인지 이상인지를 구분가능하다. 본 연구에서는 이 문제를 다루는데, 기존의 OOD와 비슷하다. MVTec AD 벤치마크 데이터에서 AE, GANs,adaptation 등등으로 문제를 풀어나갔고 최근에 이미지넷 deep representations을 통해 이를 해결하고 있다. 이는 adaptation task가 없는데 이 과정 없이도 anomaly detection 혹은 localization 성능이 뛰어나다. 이러한 성능이 나타나는 이유는 test 샘플과 정상 샘플들이 deep feature represenatation 에서 멀티스케일 특성을 활용할 수 있기 때문이다. fine-grained 는 상세 해상도를 통해, structural deviations는 고차원의 feature 을 통해 이루어진다. 하지만 이러한 고차원의 feature representation은 제한이 많다.
따라서 본 연구에서는 PatchCore를 제안하여
1) 테스트 타임에서 nominal information의 활용을 최대화
2) 이미지넷 클래스에서 biases 를 줄인다
3) 높은 추론 속도를 유지한다.
이는 locally aggregated 된 미드 레벨의 feature pathes 를 활용함으로써 달성한다. 미드 레벨의 feature patches 는 고해상도에서 편향을 줄이고, 로컬 이웃의 통합은 공간적 문맥을 유지한다. 이를 통해 메모리 뱅크를 구성하며, 이것을 서브 샘플링을 도입하여 중복을 줄이고, 패치 레벨 메모리 뱅크를 통한 추론 시간을 줄인다.
Method
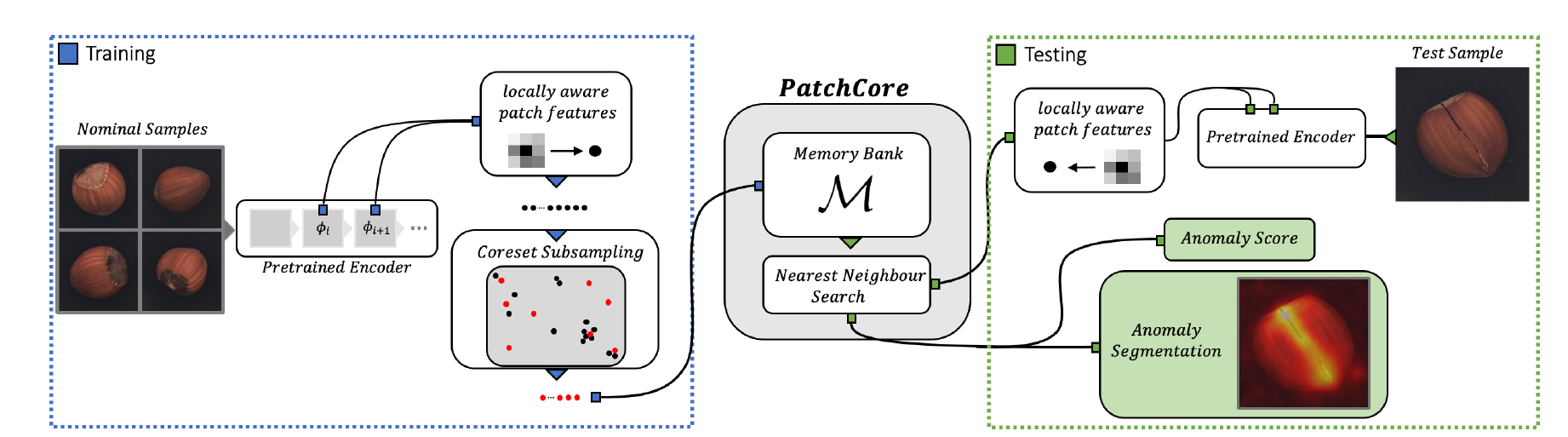
Locally aware patch features
PatchCore는 이미지넷을 활용한 pre-trained 된 네트워크를 이용한다. 특정 네트워크의 hirearchies가 중요한 역하을 하기 때문에 레벨이 중요하다. j 레벨이라고 하는데, 각 공간의 resolution블럭의 final output이다.
feature representation의 하나의 선택은 네트워크 구조에서 마지막 선택을 하는 것이다. 하지만 이는 2가지 문제점을 야기하는데, 첫 번째로 지역적 정보가 손실되며, 두 번째로 이미 학습된 네트워크의 추상적인 representation은 산업용 데이터에 직접적인 적용이 어렵다.
따라서, 본 연구에서는 미드 레벨에서의 패치 메모리 뱅크를 도입한다. 이는 너무 generic 하거나 혹은 너무 biased 되어있지 않다. ResNet 같은 경우에 j는 2 or 3이 된다.
각 패치 representation은 receptive field 를 충분하게 가진다. 그러나, 스트라이드 풀링을 활용하여 네트워크를 깊게 보면 ImageNet에 특화되고 anomaly detection과 덜 관련이 있게 되므로 활용도가 낮아진다.
따라서 각 패치에서의 representation을 볼 때, 지역 이웃 aggregation이 중요하다. 각 패치 레벨 feature representation이 receptive field size를 크게 한다. 따라서 불균등한 패치 크기를 고려하게 된다.
Coresetreduced patchfeature memory bank
이미지 사이즈가 클수록 메모리 뱅크는 크게 되고, 인퍼런스 시간이또한 증가한다. 이러한 이유로 SPADE는 low & high 레벨의 feature map을 활용하였다. SPADE는 픽셀 레벨의 anomaly detection을 위해 feautre map의 preselection을 요구한다. 이는 마지막 feature map의 global averaging으로 이루어진다. 이는 이미지넷 기반의 representation이 full image 기반으로 계산되어지며 localization 퍼포먼스 또한 좋지 못하게 된다. 따라서 M개의 meaningfully 한 뱅크를 만들어서 패치 기반의 anomaly detetion 과 segmentation이 진행되어야 한다. 이것은 그러나 랜덤 서브샘플링으로 인해 몇몇 magnitude 에 의해 M개의 인코딩된 feature의 정보를 잃어버리게 된다. 따라서 M을 랜덤하게가 아닌, 코어셋을 활용하여 퍼포먼스를 유지하면서도 추론 시간을 줄이게 된다. PatchCores는 nearest neighbour computations를 활용하기 때문에 minimax facility location coreset selection을 이용한다. 이는 즉, 오리지널 메모링 뱅크에서 패치 레벨 feature 공간에서 비슷하게 coverage를 가지게 된다.
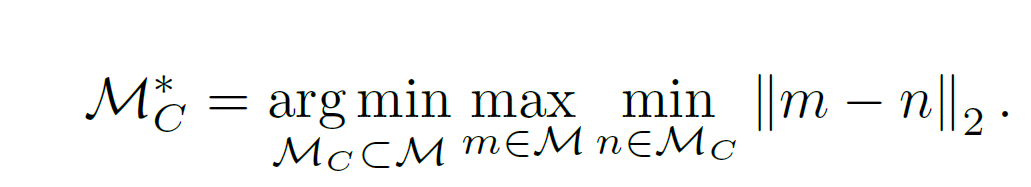
Anomaly Detection with PatchCore
patch-feature bank M 에서, 이미지 레벨의 anomaly score s 를 테스트 이미지에 대해서 구한다. 이는 테스트 패치 features와 각 M 의 있는 nearset neighbour 사이의 거리를 구함으로써 나타낸다.
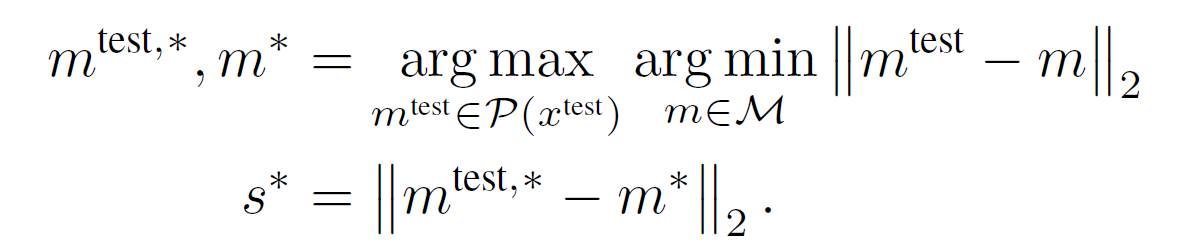
만약 anomaly candidate와 가장 가까운 메모리 뱅크의 feature 가 이웃 샘플들간의 거리가 있었다면 s 가 높아진다.
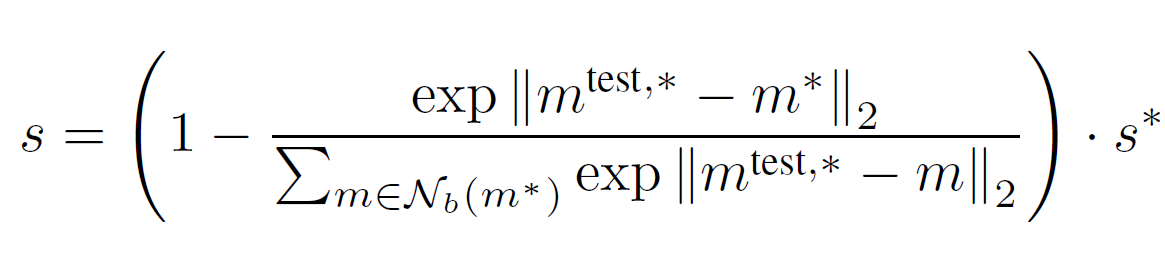
단지 patch distance를 maximize 하는 것 보다는 re weighting 하는것이 더 robust 하다.
Experiments
Experimental Details
Dataset : MVTec AD
Evaluation Metrics : AUROC, PRO
Anomaly Detection on MVTec AD
메모리 뱅크 subsampling 의 정도에 따라 (25%, 10%, 1%) 로 진행하였음


anomaly detection 퍼포먼스가 다른 모델 대비 더 좋았음. 또한 coreset subsampling 을 통해서 1%를 하여도 다른 모델대비 성능이 뛰어났음.
Inference Time
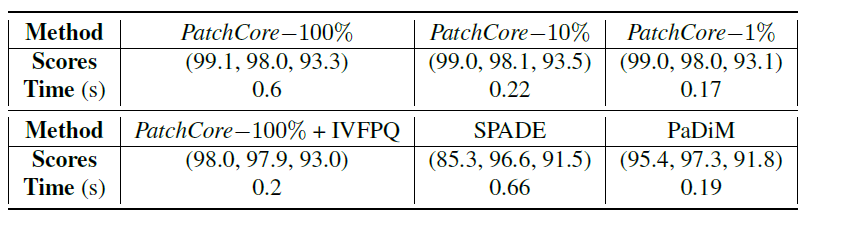
PatchCore 100%를 사용하는 것은 성능 또한 좋았지만, 시간또한 outperform 하였다. 추가로, subsampling 을 진행하여 추론 시간을 더 줄일 수 있었다.
Ablations Study
Locally aware patch-features and hierarchies
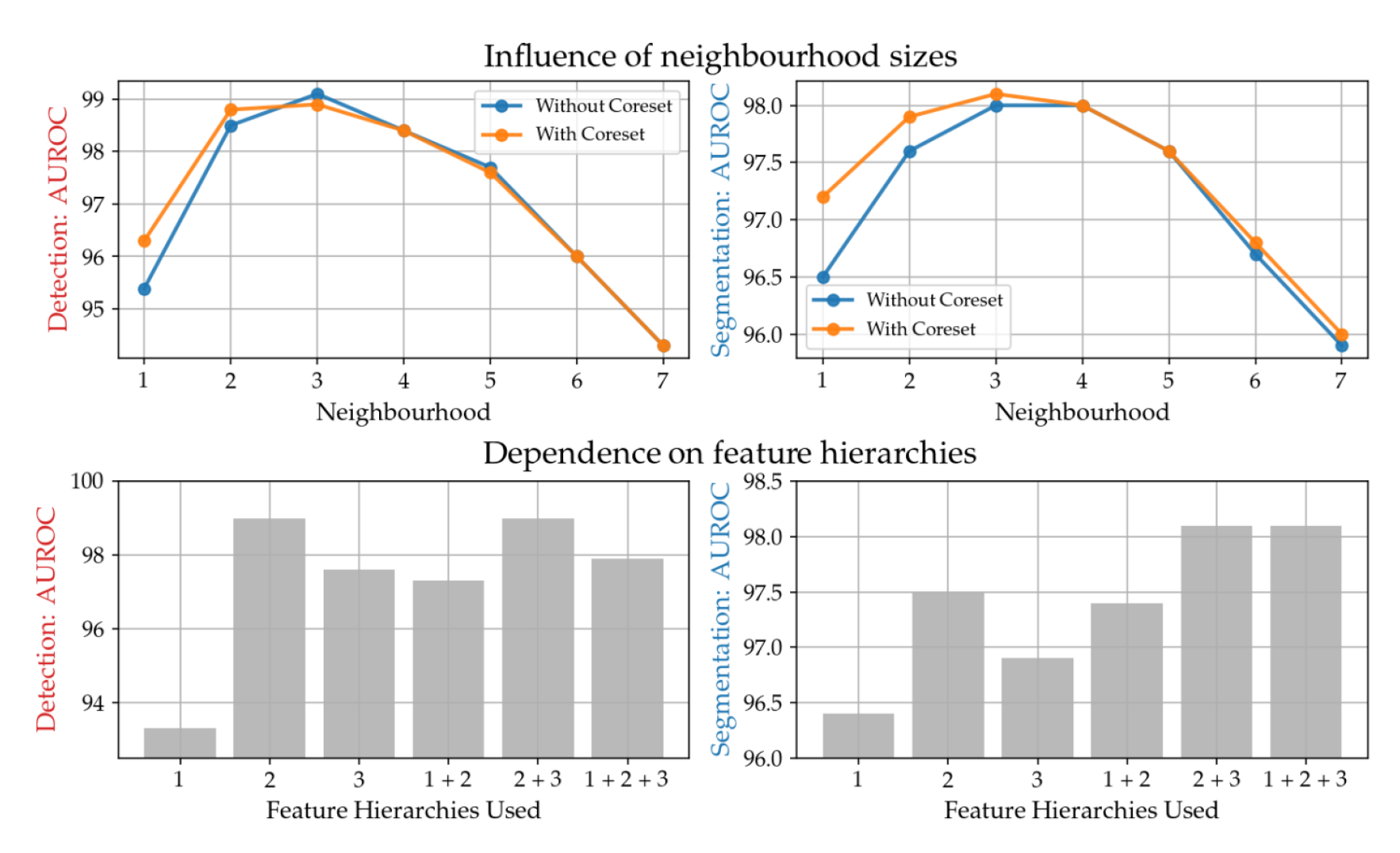
다른 이웃 사이즈를 통해서 퍼포먼스를 비교하였다. p = 3 인 경우에 패치 기반의 local & global 문맥을 잘 반영함을 볼 수 있다.
또한, 네트워크의 하단으로 갈 수록 더 많은 global context를 볼 수는 있지만, resolution의 할학과 더 많은 bias를 가지게 된다. level 2에서 SOTA 퍼포먼스를 이미 달성하였다. 하지만, 2 + 3 이 더 추가적으로 성능 개선의 효과를 보이기도 하였다.
Importance of Coreset subsampling
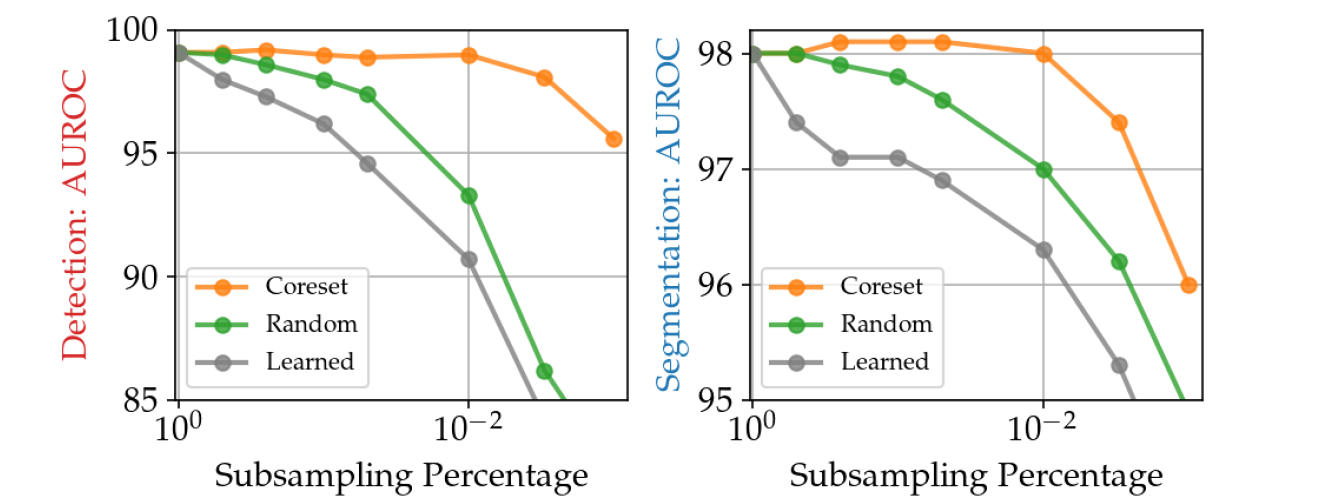
서브셋의 비율을 줄여나가면서 퍼포먼스 retention을 비교하였다. Coreset의 경우 1%의 서브샘플링에서도 거의 성능 하락을 보이지 않았다.
Lowshot Anomaly Detection
nominal data가 제한된 경우에, 실제 상황과 비슷하다. 그러므로, MVTec AD의 결과에 더해 더 적은 학습 예제를 통해 타 모델과의 비교를 하였다.
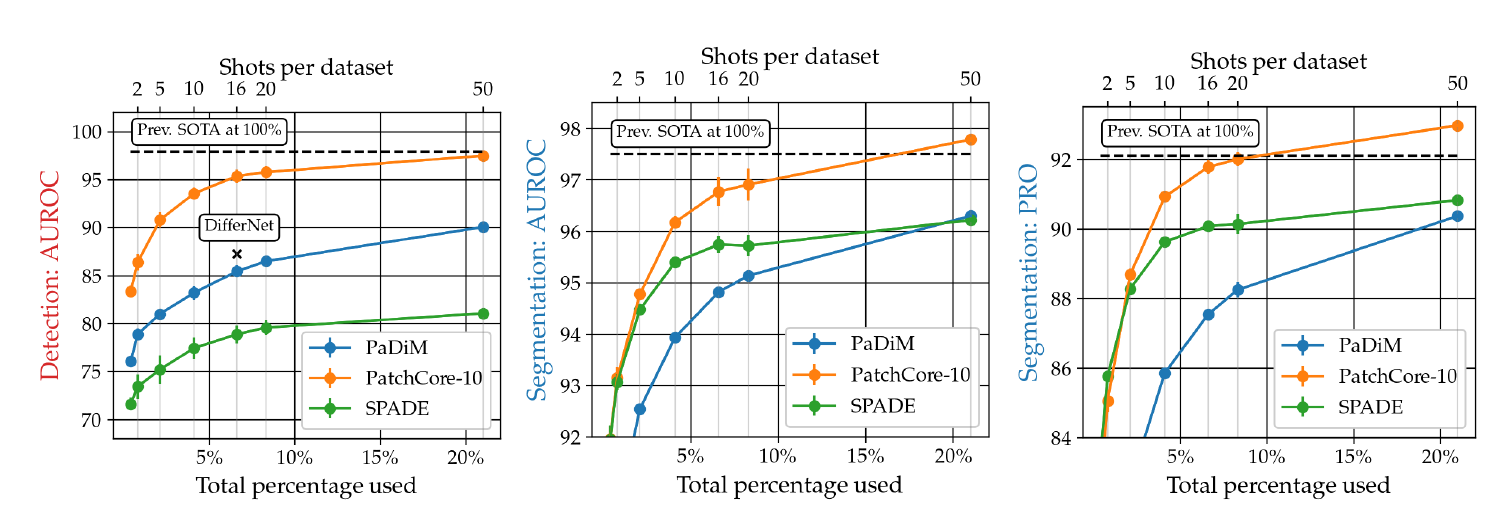
실제 nomial shot의 1/5 의 데이터만 가지고도 기존의 full data를 사용한 SOTA 성능을 달성하였다.
Evaluation on other benchmarks

다른 벤치마크 데이터에 대해서도 SOTA 성능을 보였다.
Conclusion
본 연구에서는 PatchCore 알고리즘을 통해 산업데이터의 anomaly detection을 수행하였다. 이는 다운스트림 태스크로 detection과 segmentation을 진행할 수 있었다. PatchCore는 메모리 뱅크를 활용하여 추론하는데 있어서 core set subsampling을 활용하여 최소의 자원을 활용하였으며, feature representation은 이미지넷의 미리 학습된 네트워크를 이용하였다. 이를 통해 MVTec 라는 산업현장 데이터에 SOTA 성능을 달성하였다. 그러나 한계점으로는 각 도메인에 대한 adaptation이 이루어지지 않았기 때문에 pretrained 된 feautures 가 활용될 수 있는 분야에 제한적이다.
