An adversarial transfer network with supervised metric for remaining useful life prediction of rolling bearing under multiple working conditions
2023 하계 논문세미나
Abstract
존재하는 도메인 adaptation 기반의 방법론들은 domain invariant featue를 도출하고, 도메인 shift를 다루어 다양한 작동 환경 하에서 RUL을 구하였다. 그러나, 대부분의 방법들은 distribution discrepancies를 정렬하는 과정에서 local semantics를 고려하지 않았다. 게다가, 대조학습을 이용하는 과정에서 unstable한 negative samples를 학습하는 경우가 많았다. 따라서, 본 연구에서는 metric adversarial domain adaptation approach (MADA)를 사용하여 다양한 환경에서의 베어링 RUL을 평가한다. 구체적으로, adversarial domain adaptation architecture with a supervised positive contrastive module이 구축되어 negative samples 없이도 mutual information을 고려한다. 또한 domain invariant feature를 학습하게 된다. 또한 dual self-attention 모듈을 통해 degradation features 간에 multi-scale
contextual semantics degradation features를 추출한다.
Introduction
PHM은 유지보수 plan을 효율적으로 설정하며, downtime을 줄이고, 설비의 신뢰도를 높인다. 그 중에서도 RUL 예측은 PHM에서 challenging 한 regression task이다. 베어링은 설비에 다양하게 사용되기 때문에 multiple condition 상황에서 작동한다.
RUL 예측 방법론은 모델 기반 방법론과 하이브리드 방법론, 데이터기반 방법론으로 나뉜다. 모델 기반 방법론은 RUL을 예측하는데 통계 모델을 사용한다. 이러한 방법론은 expert knowledge를 사용해야 하며, complex system에서는 잘 맞지 못한다.
HPML-based method(하이브리드) 방법론은 머신러닝과 physical degradation을 융합한다.
데이터 기반 방법론은 sensor data를 parametric model에 넣는다. 이러한 모델은 hidden feature를 추출하여 RUL을 예측한다. 하지만 이러한 방법론들은 학습과 테스트 데이터가 비슷한 distribution에 있다는 가정을 한다.
대부분의 산업 데이터에서 베어링은 load, speed, 다양한 환경하에 놓이게 된다. 따라서 degradation feature는 공간적 distribution이 다르게 된다. 이는 domain shift라고 불리며, 하나의 데이터에 학습된 모델이 다른 데이터에는 잘 perform 하지 못함을 의미한다. Domain adaptation은 이러한 상황에서 소스와 타겟 도메인에 대해 distribution discrepancies에 대한 정렬을 하여 domain invariant representation을 학습한다. 하지만 이러한 방식은 featrue extractor가 매우 복잡하기 때문에 소스 도메인과 타겟 도메인의 비슷한 arbitrary representation이 학습이 될 수 있다. 즉, target feature 들은 source feature들과 비슷하게 추출이 되며, 이는 target-specific information에 대한 contraint가 존재하지 않기 때문이다. 이는 타겟 데이터에 대한 ingherent structure를 preserve 하기 어렵다. 타겟 데이터와 타겟 element간의 mutual information을 제거할 수 있으므로, regression에 대한 representation을 잃게 된다.
현재 존재하는 방법론들은 대조학습을 통해 target-specific한 mutual information을 maximize 한다. positive samples들은 같은 class 및 semantic을 가지고 있다. 하지만 negative samples들은 다른 calss 및 semantic을 가지고 adversarial augmentation으로 생성된 데이터들이다. 이러한 방법론은 negative samples의 이용 유무가 모델의 stability에 중요하게 영향을 미친다. 또한 negative samples를 생성하는 경우에도 challenging 한 부분이 많이 남아있다.
따라서 우리는 mutual positive imformation을 maximize하는 방법을 제안하여 negative sameples의 interference를 방지한다. (MADA) approach 는 지도학습 metric 모듈 기반으로 adversarial domatin adaptation 을 수행하여 다른 working condition들 간에 전이학습을 수행한다. supervised positive contrastive (SPC) 모듈은 DA과정에서 metric target-specific mutual information을 획득하기 위해 설계하였다. SPC 모듈에서는 negative sameples를 더 이상 만들 필요가 없다. intrinsic structure of the target이 보존된다. Local semantic 에 embedded 된 domain invariant feature를 novel dual self-attention 모듈이 획득한다. 이 모듈은 multiple 스케일에서 contextual semantic 을 추출한다.
본 연구의 main contribution은 다음과 같다.
1. A metric adversarial domain adaptation approach 으로 RUL을 multiple working condition에서 수행하였다.
2. dual self-attention module 을 통해 domain invariant features 들을 multi-scale semantics에서 추출한다.
3. supervised positive contrastive module을 통해 target-specific mutual information을 추출하여 타겟의 intrinsic structure를 보존한다.
Related works
Deep DA for RUL
source and target features의 weight을 조정하면서 이 둘의 distribution discrepancy를 줄인다. statistical moment
matching 기반의 방법론은 statistical loss를 줄이며 distribution discrepancy를 줄인다. 이는 maximum mean discrepancy (MMD) 라고 한다. multi-kernel maximum mean discrepancy는 MK-MMD로 커널의 선택이 필요없다.
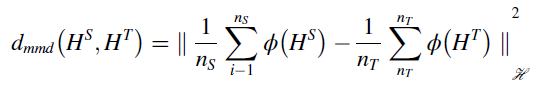
DA기반의 방법론은 global에 invariant representation을 학습함으로써 domain shift를 도출한다.
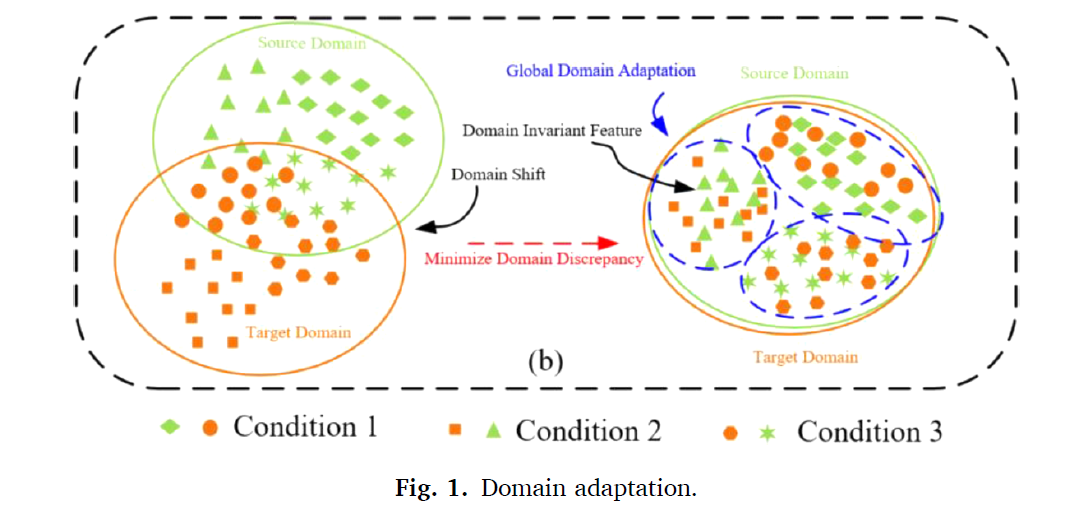
이는 타겟 도메인의 mutual information이 무시된다는 문제점이 있다.
Adversarial domain adaptation for RUL
ADA 방법론은 feature extractor와 domain discriminator 간의 adversarial 학습을 진행한다. 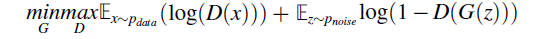
PHM에서 ADA를 통해 domain invariant feature를 획득하거나, RUL 예측을 더 잘 할수 있었다. 하지만, negative samples를 생성하는 과정에서 모델을 학습하는데 challenging 한 이슈이다.
Methodology
Problem description
본 연구에서 제시하는 MADA 는 데이터 에서의 RUL 를 mapping 한다. 이는 라벨된 소스 도메인과 라벨되지 않은 타겟 도메인의 invariant feature를 학습하고, 소스도메인과 타겟도메인의 distribtion space가 다른 상황이다. 
Overview
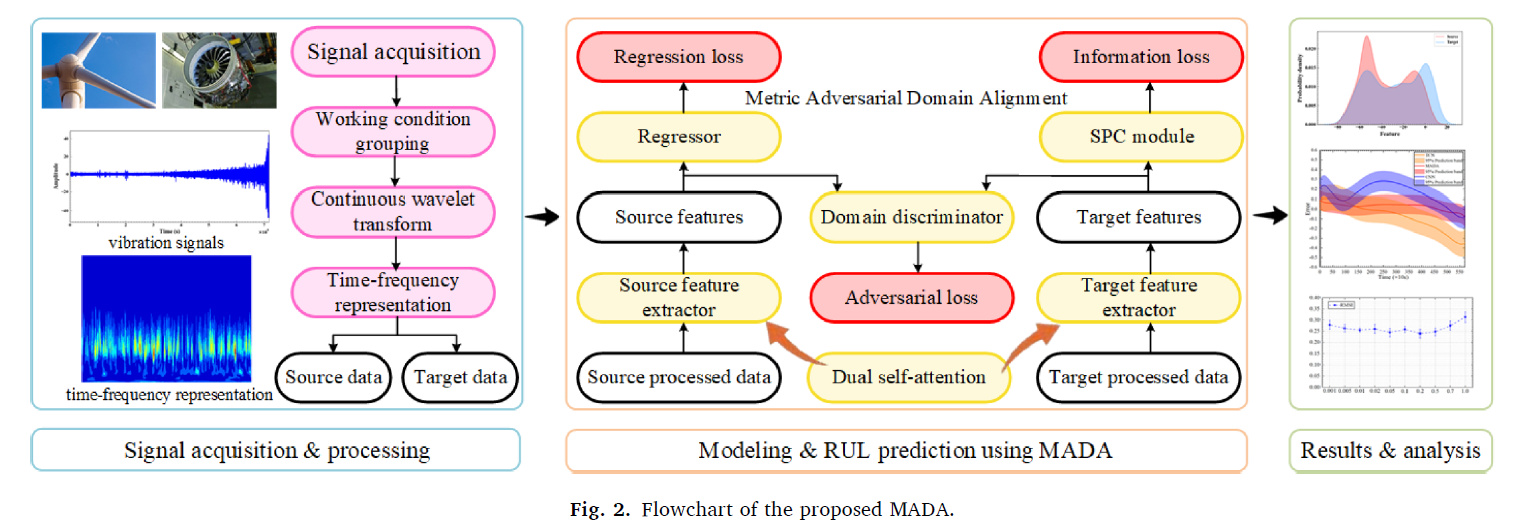
1. 소스 및 타겟 도메인에 대한 data preparation을 진행
2. feature extractor로 dual selfattention module을 쓰고, regressor를 통해 RUL을 예측함
3. adversarial domain network and SPC module 은 지도학습과 adversarial loss를 통해 최적화 됨
4. 마지막으로, 학습된 feature extractor와 regressor를 통해 테스트 데이터의 RUL을 예측한다.
Methodology for backbone network
Dual self-attention module
convoultion 알고리즘은 local feature가 global space에서 어디에 위치하는지에 대한 정보가 없어진다. 그러나, domain invariant feature는 local 정보에 더 민감한데 반해, contexture semantics degradation 정보는 그러지 못한다. 따라서, dual self-attention 모듈을 통해 이를 수행한다.
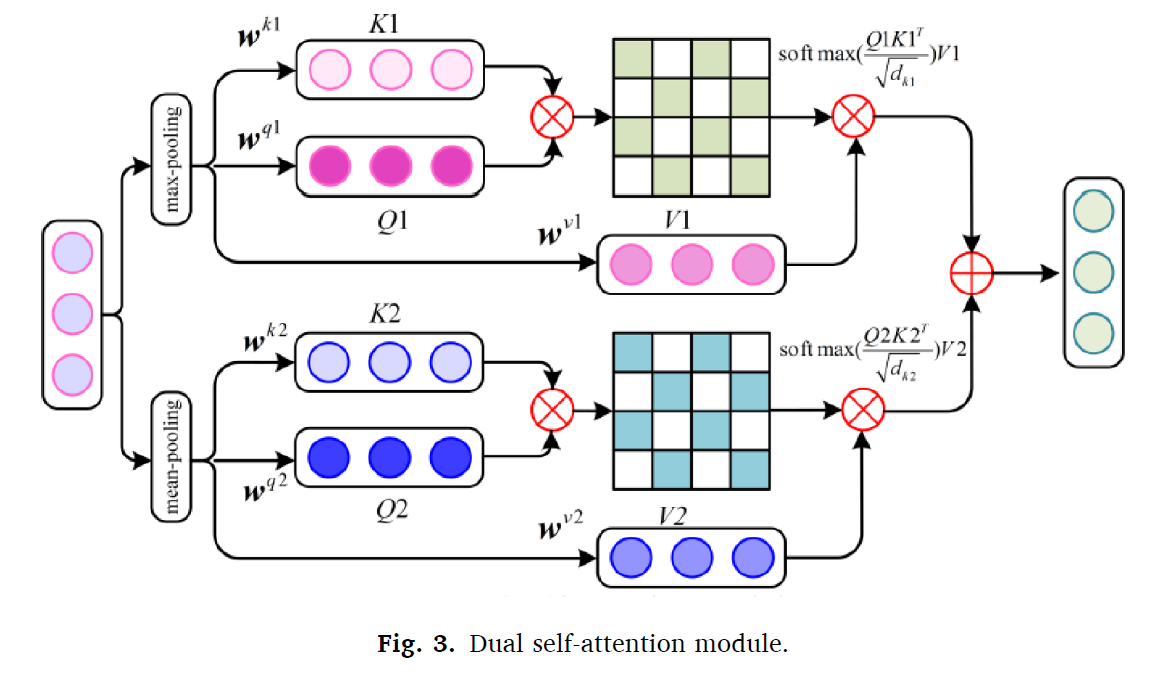
dual self-attention module은 멀티스케일의 feature maps를 fuse한다. 각각의 feature map의 patch간 semantics들은 attention matrix로 구성된다.
각 모듈의 인풋은 쿼리, 키, 밸류들을 포함하고, X는 인풋 벡터이다. dual self-attetion module은 Q 와 K를 parallel하고 2채널로 계싼한다. 이를 통해 attention matrix를 생성하고, V를 통해 global connection을 만든다. mult-scale fusion은 다음과 같이 계산된다.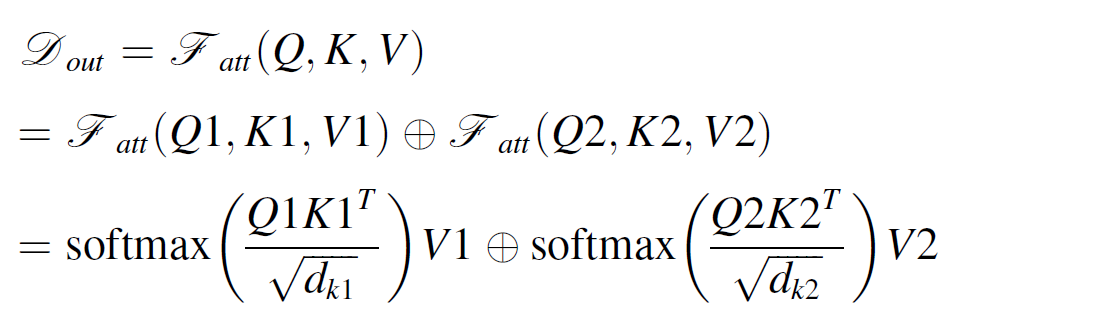
3.3.2. Temporal convolution modeling
Regression task에 Temporal Convolution Netwok (TCN)이 recurrent neural network 보다 더 좋은 성능을 보였다.
1. causal convolution이 sequence information의 leakage를 줄인다.
2. sequences를 arbitrary length로 획득하고 output sequence를 같은 length로 출력할 수 있는 flexibility
위와같은 장점에 따라서 TCN 기반의 feature extractor를 제안하였다.
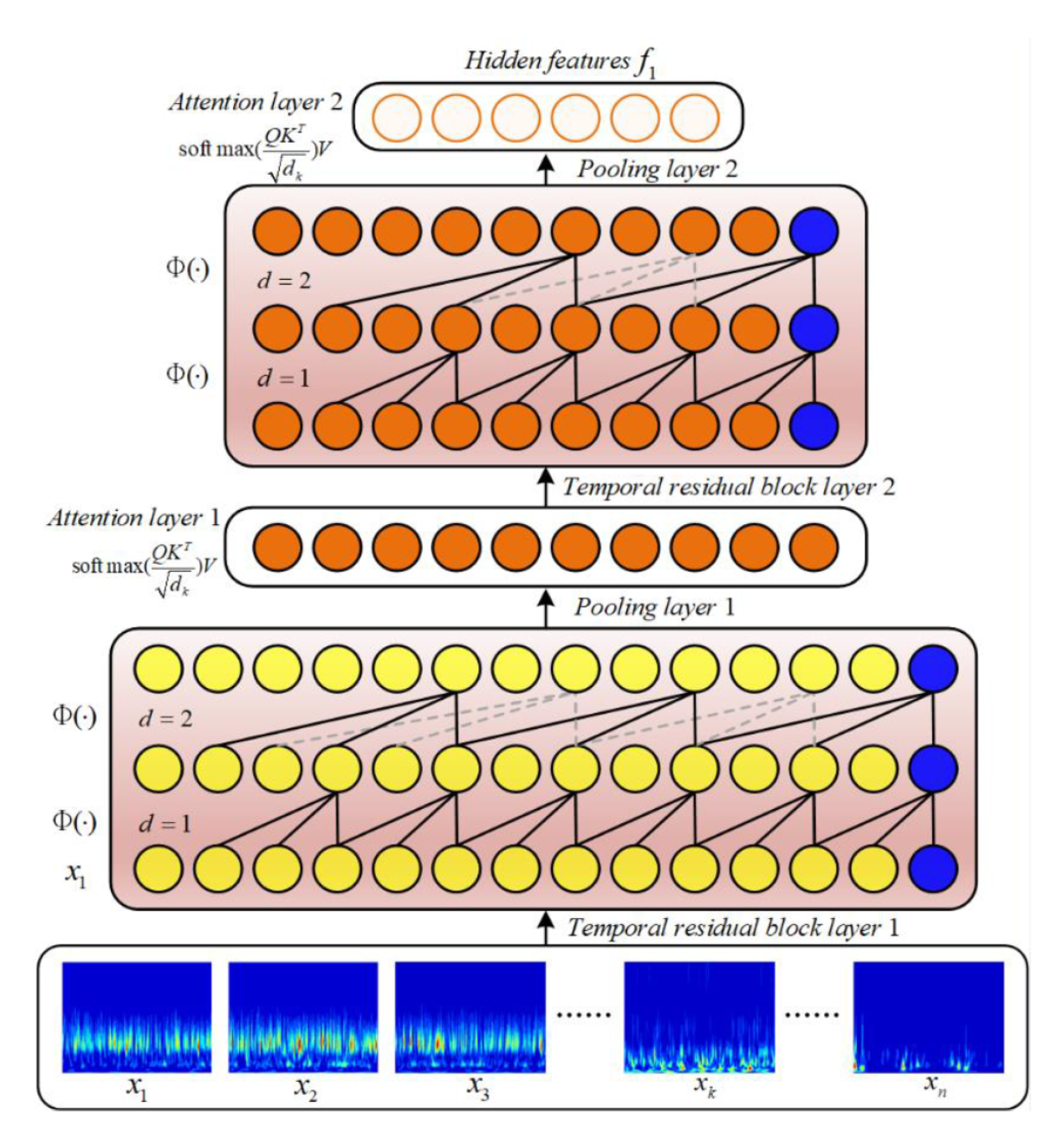
feature extractor는 temporal residual block을 사용하고, dual-self attention module을 사용한다.
local information에 embedding 되어있는 domain invarint features들은 temporal residual block 에 의해 획득된다. 또한 extracted 된 feature는 dual attention module의 인풋으로 들어가 mutliscale semantics로 인풋이 된다. dilated convolution operation또한 들어가 최종 아웃풋이 나오게 된다.
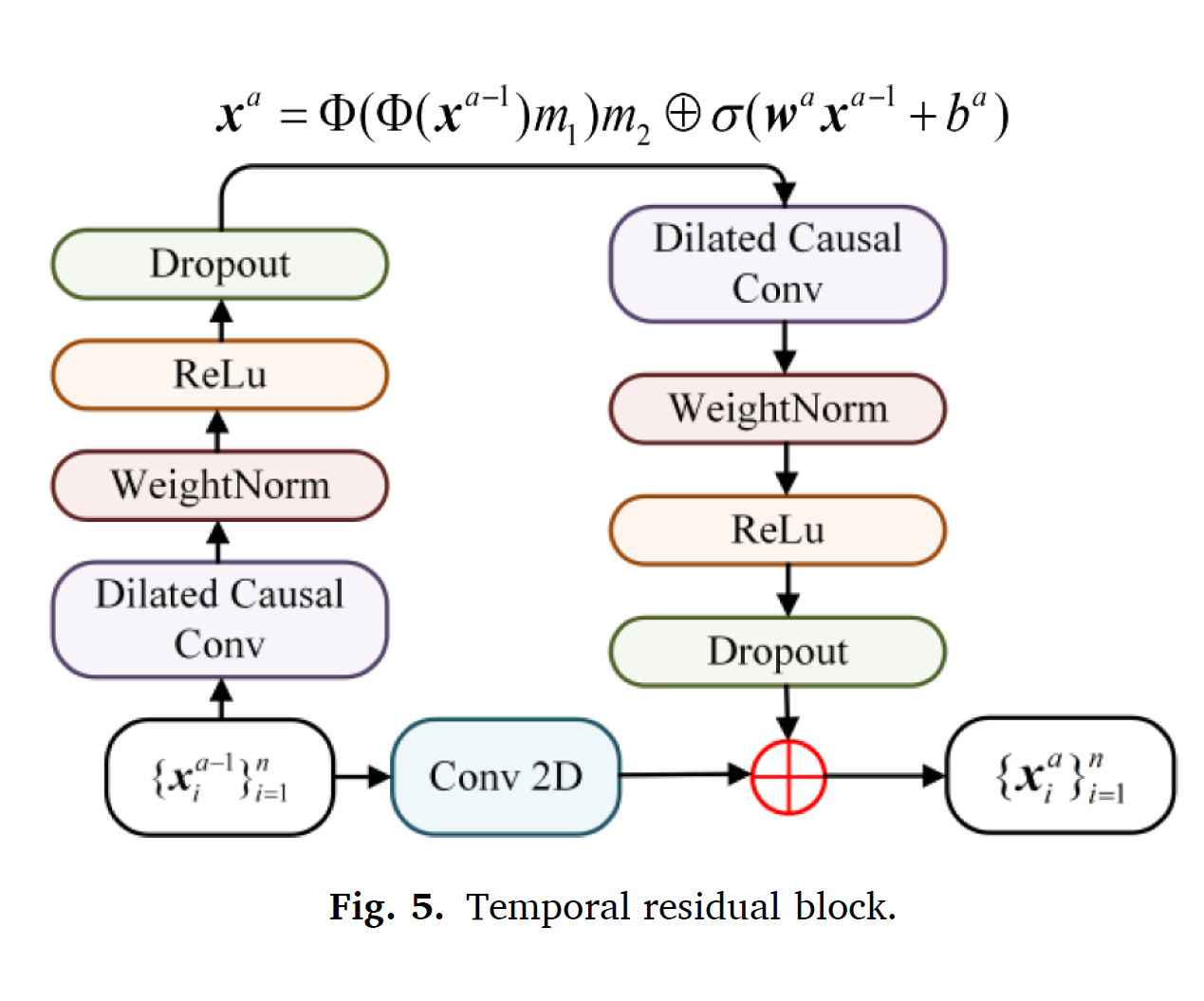
RUL prediction network
RUL 예측 regressor는 다음과 같이 디자인된다.
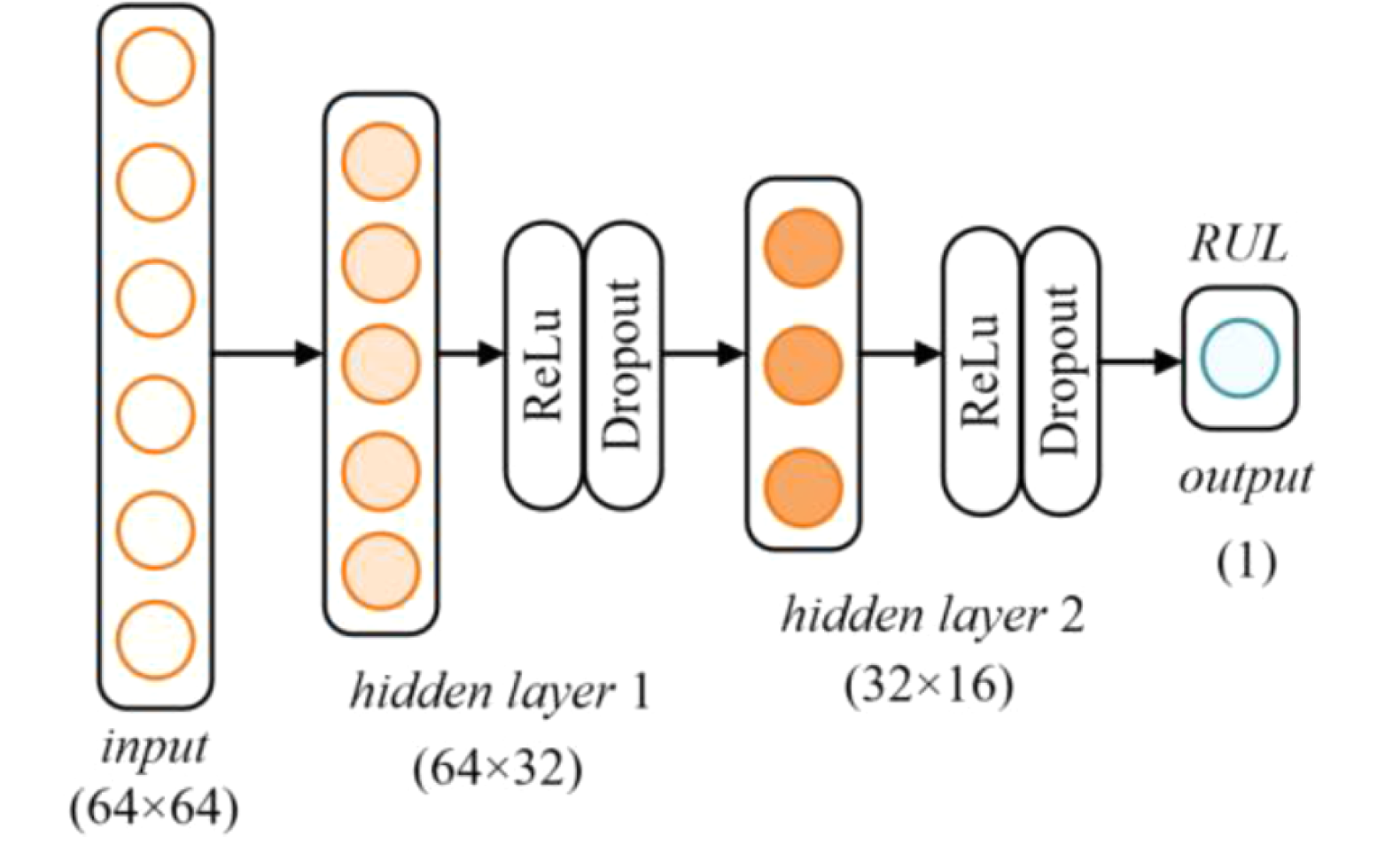
Metric adversarial domain adaptation
Adversarial domain network
target-specific mutual information을 보존하면서 domain invariant feature를 학습하기 위해서 새로운 domain adaptation 아키텍처가 필요하다.
metric adversarial domain adaptation architecture은 다음과 같다.
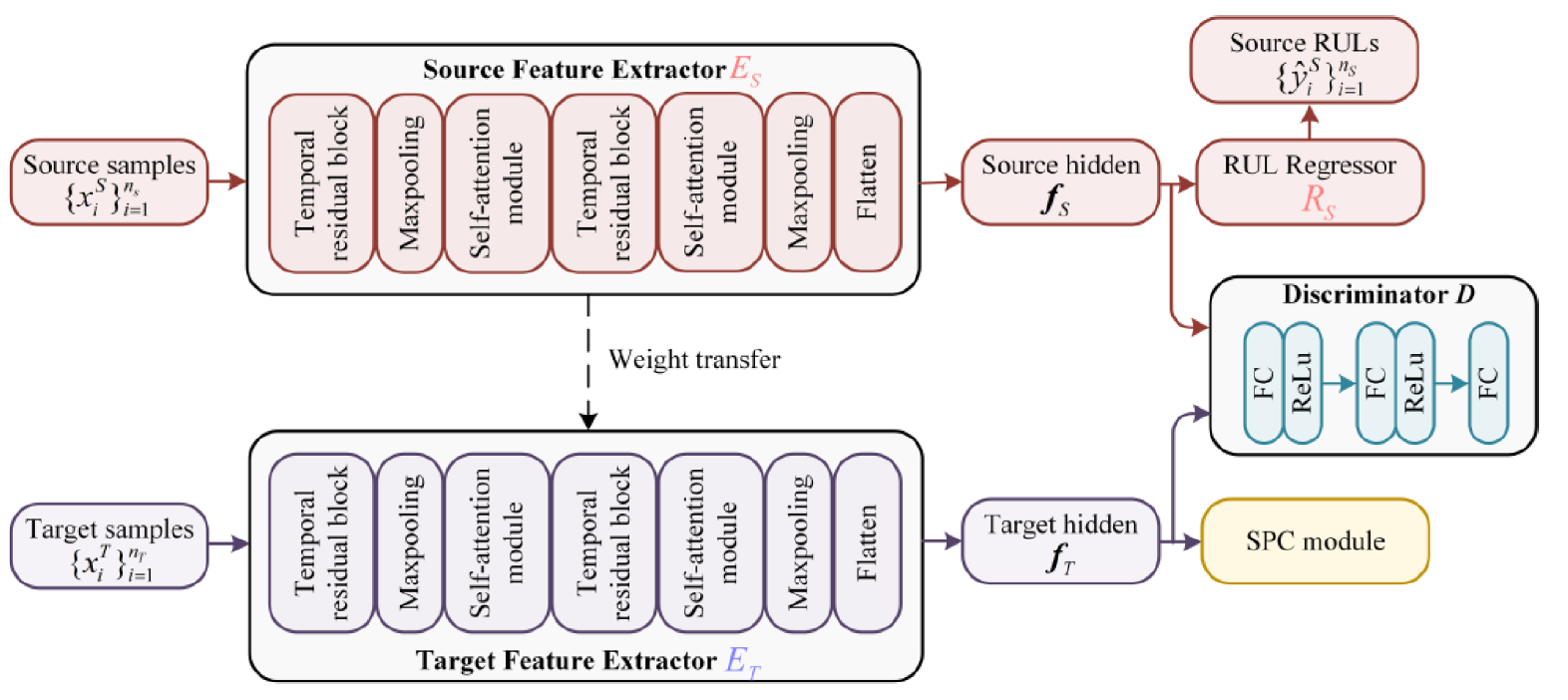
소스도메인과 타겟도메인의 feature가 Discriminator D에 들어가서 대조 loss를 최소화한다. 반면에 타겟 feature가 SPC 모듀에 들어가서 mutual information이 보존되는 방향으로 학습한다.
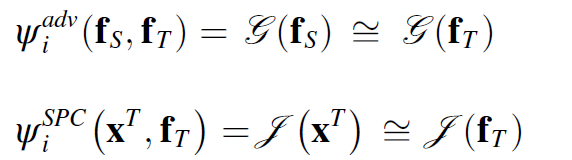
이를 joint하면 다음과 같다.
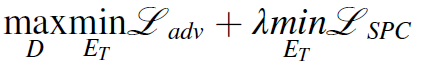
타겟 feature extractor는 weight이 소스 feature extractor로 초기화가 된다. 소스와 타겟 피처는 D에 의해 구분이 되기 힘들에 학습되며, 소스와 타겟 도메인 간의 distribution discrepancy를 줄이게 되면서 동시에 내부 구조를 보존한다.
Supervised positive contrastive module
SPC 모듈은 타겟 feature 간의 mutual information을 maximize한다.
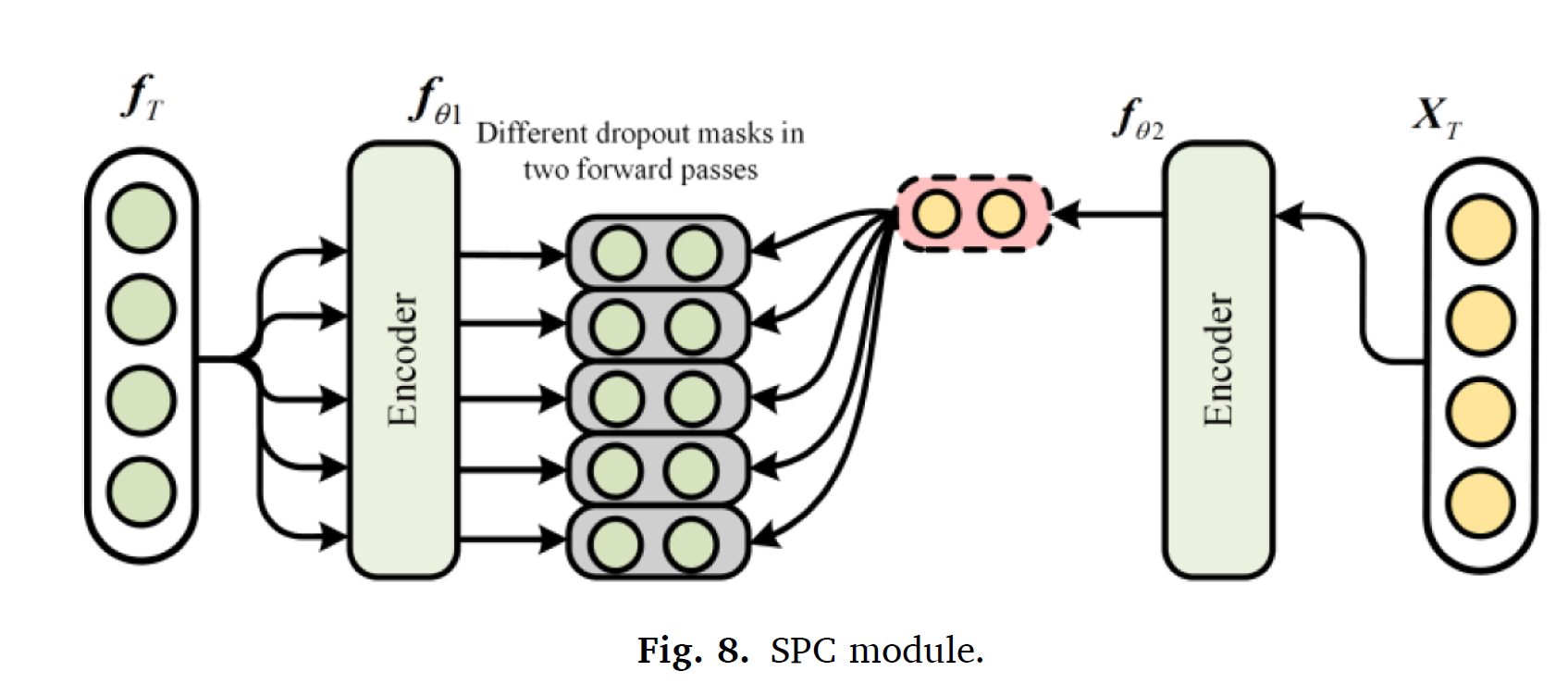
SPC 모듈의 알고리즘은, 효과적인 feature representations를 positive neighbors끼리 클러스터링하여 negative samples없이 학습하는 것이다.
크로스엔트로피 로스는 다음과 같이 이루어진다.
matched samples 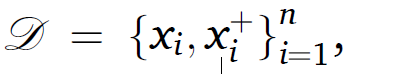
가 있다고 한다면, 크로스엔트로피는 다음과 같다.
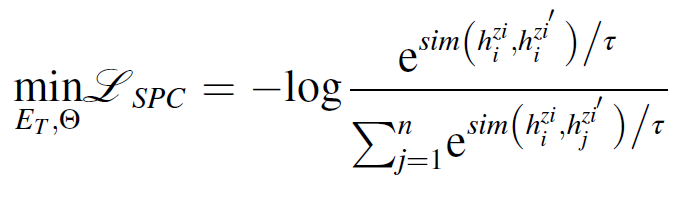
supervised metric loss는 다음과 같이 정의된다.
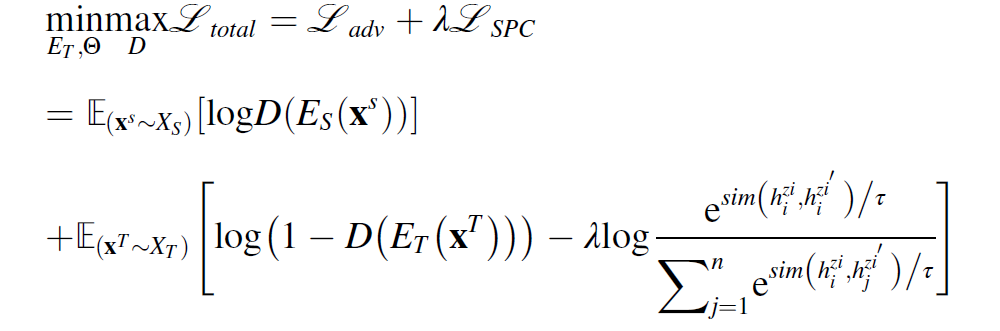
인코더 는 샘플 pair 와 를 만드는데 사용된다. 타겟 features 가 주어진다면, = {} 과, = 이다.
독립적으로 샘플된 마스크를 random dropout mask를 사용하여 비슷한 positive pair를 만든다. target feature extractor는 positive samples를 비교하며 mutual information을 최대화하는 방향으로 학습된다.
Total objective loss function
토탈 로스는 다음과 같다.

이를 학습하는 알고리즘은 다음과 같다.
Case study
Dataset description
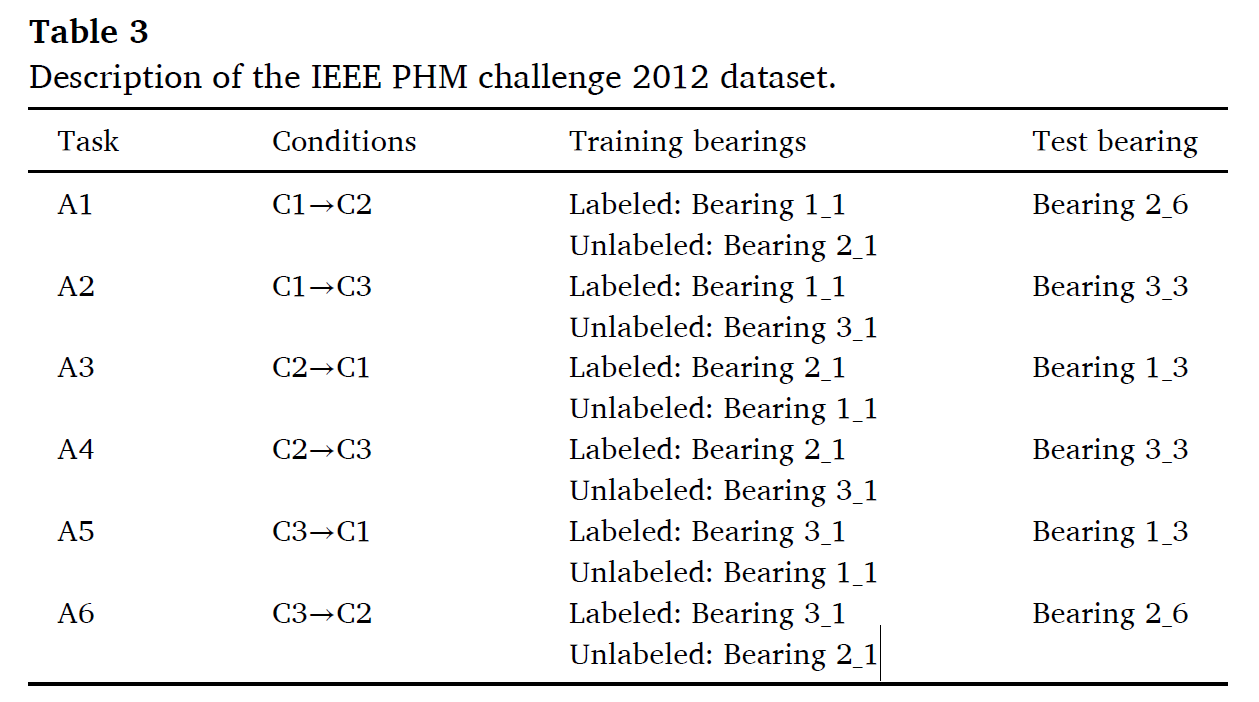
CASE1.IEEE PHM Challenge 2012
CASE2.XJTU-SY
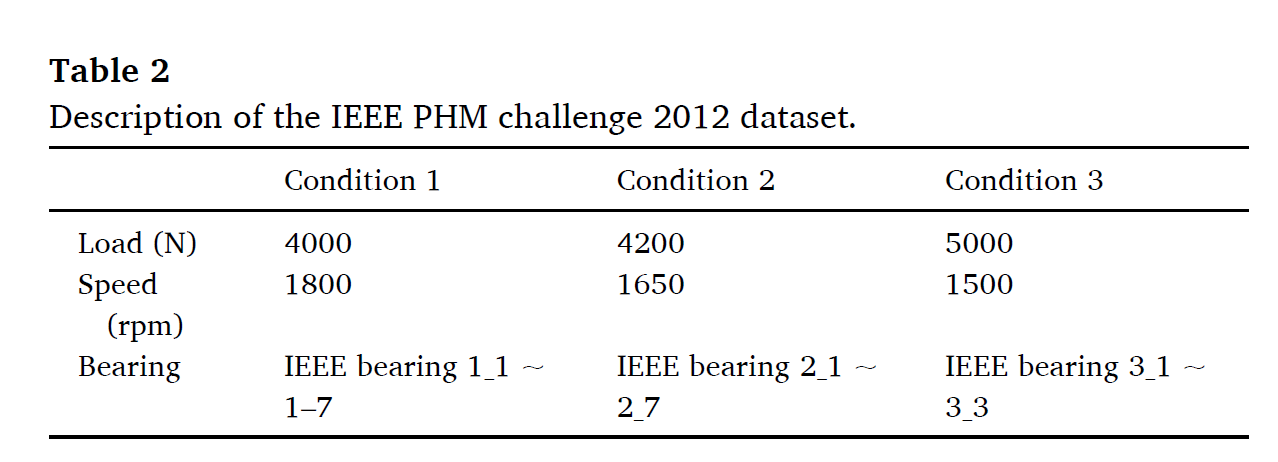
두가지를 사용
Data preprocessing
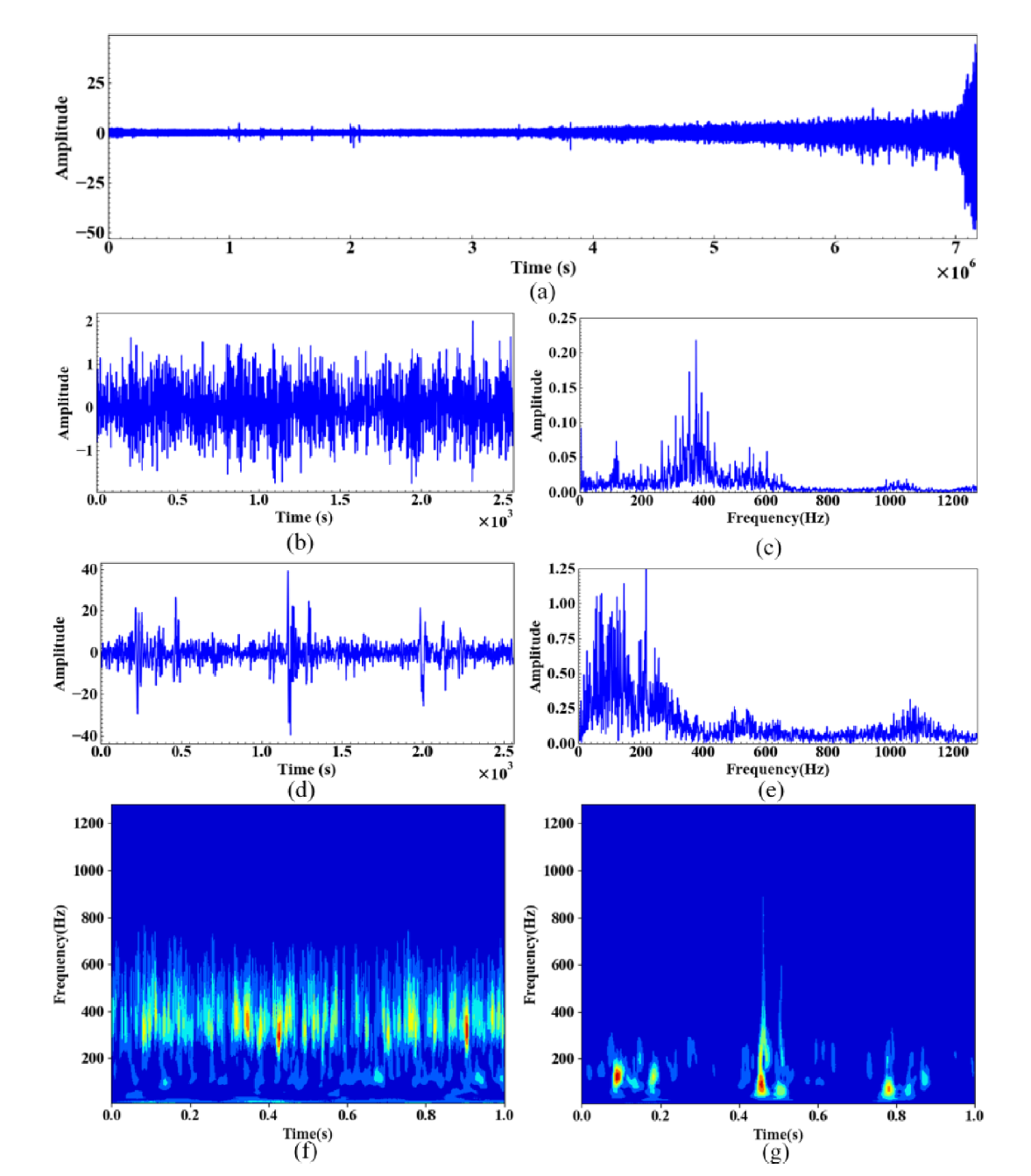
진동 원본 데이터는 DC component에 의해 noise를 함유하고 있을 수 있다. 그러나, noise reduction은 critical information을 제거할 가능성도 포함한다. 따라서, timefrequency
representation (TFR) image 가 이것을 잘 나타낼 수 있다. vibration signal은 nonlinear 하기 때문에, continuous wavelet transform을 사용하였다. CWT로 획득한 TFR이미지는 너무 크기때문에, resolution은 256X256 으로 조정된다.
Evaluation metrics
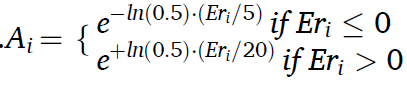
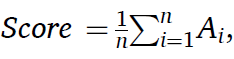
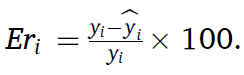
스코어 함수는 다음과 같다. 즉, early로 예측값이 더 작게나와 가 양수라면,
Ablation study
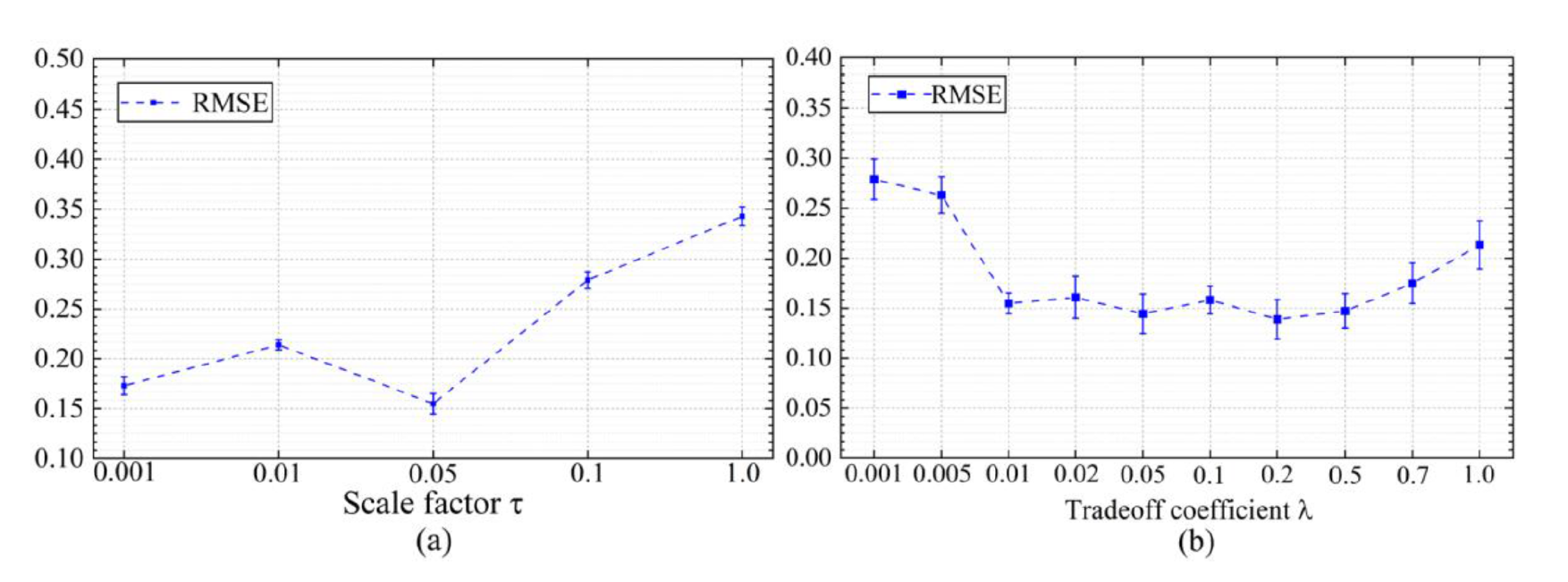
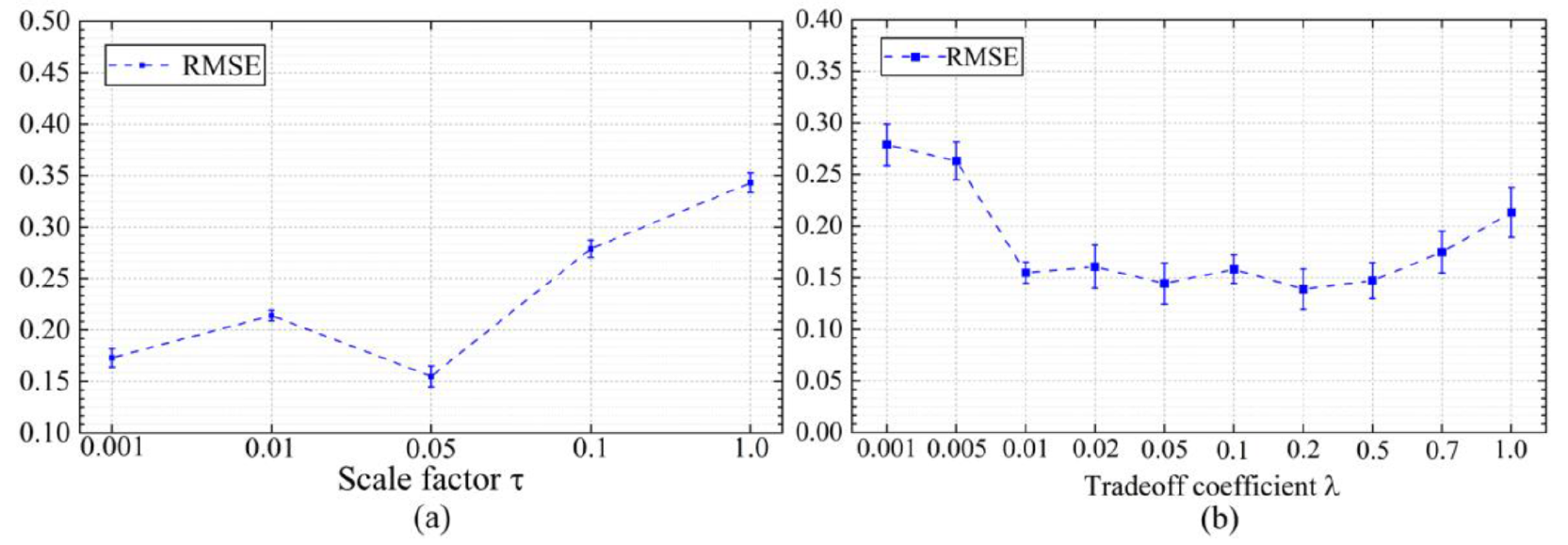
Comparison of sensitive parameters
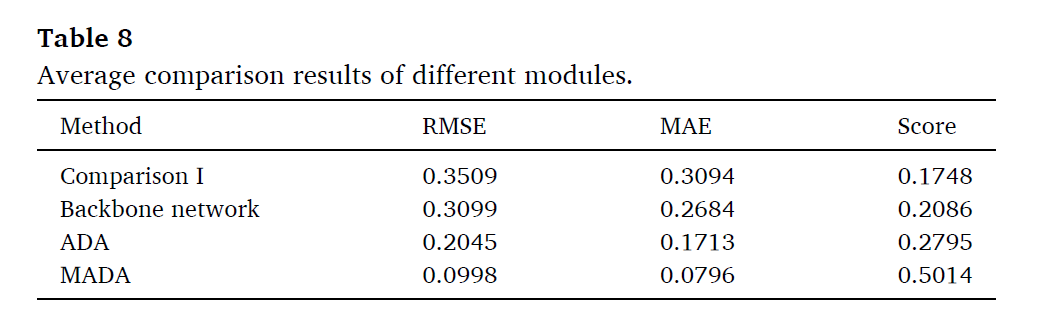
Comparison of different modules
Comparison I: the network architecture without dual self-attention
module, ADA module, and SPC module.
Backbone network: the backbone network embedded with the dual
self-attention module
ADA: the adversarial adaptation network based on the backbone and
ADA module.
MADA: the metric adversarial domain adaptation using ADA and SPC
module.
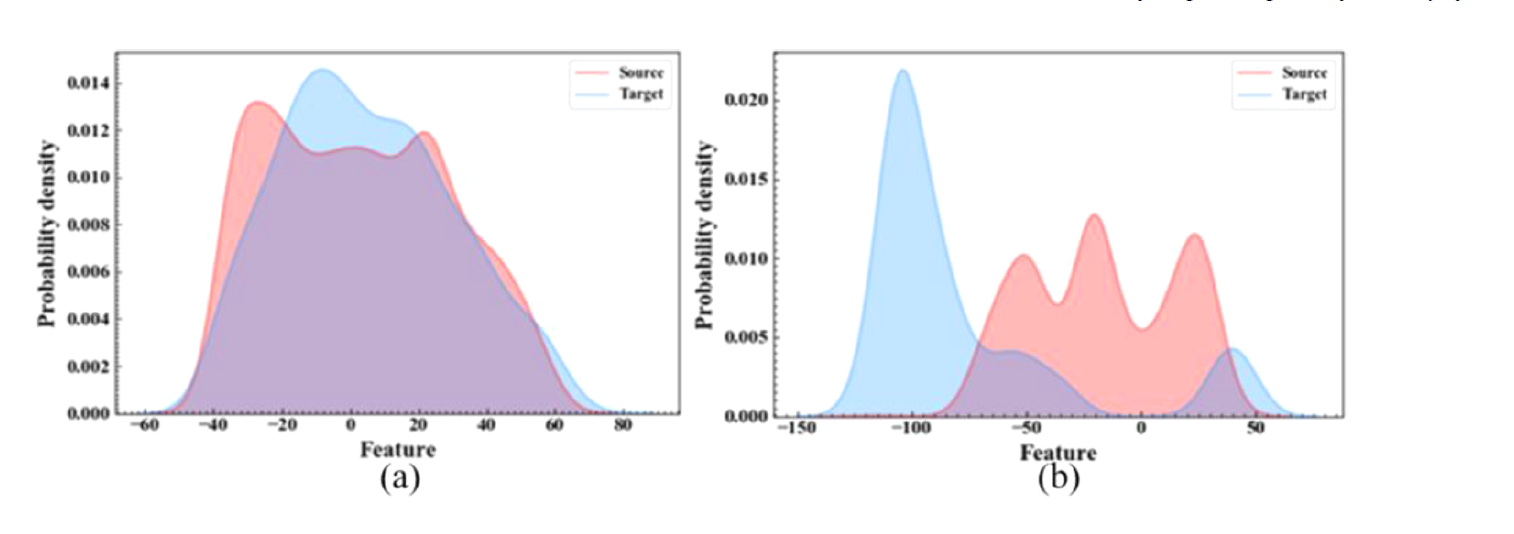
ADA와 MADA의 비교 시, 큰 사이를 보이게 되는데 이것이 SPC모듈을 통해 target-specifit한 정보를 retain하기 때문이다.
feature distribution을 시각화 하면 다음과 같다.
RUL prediction on Case I
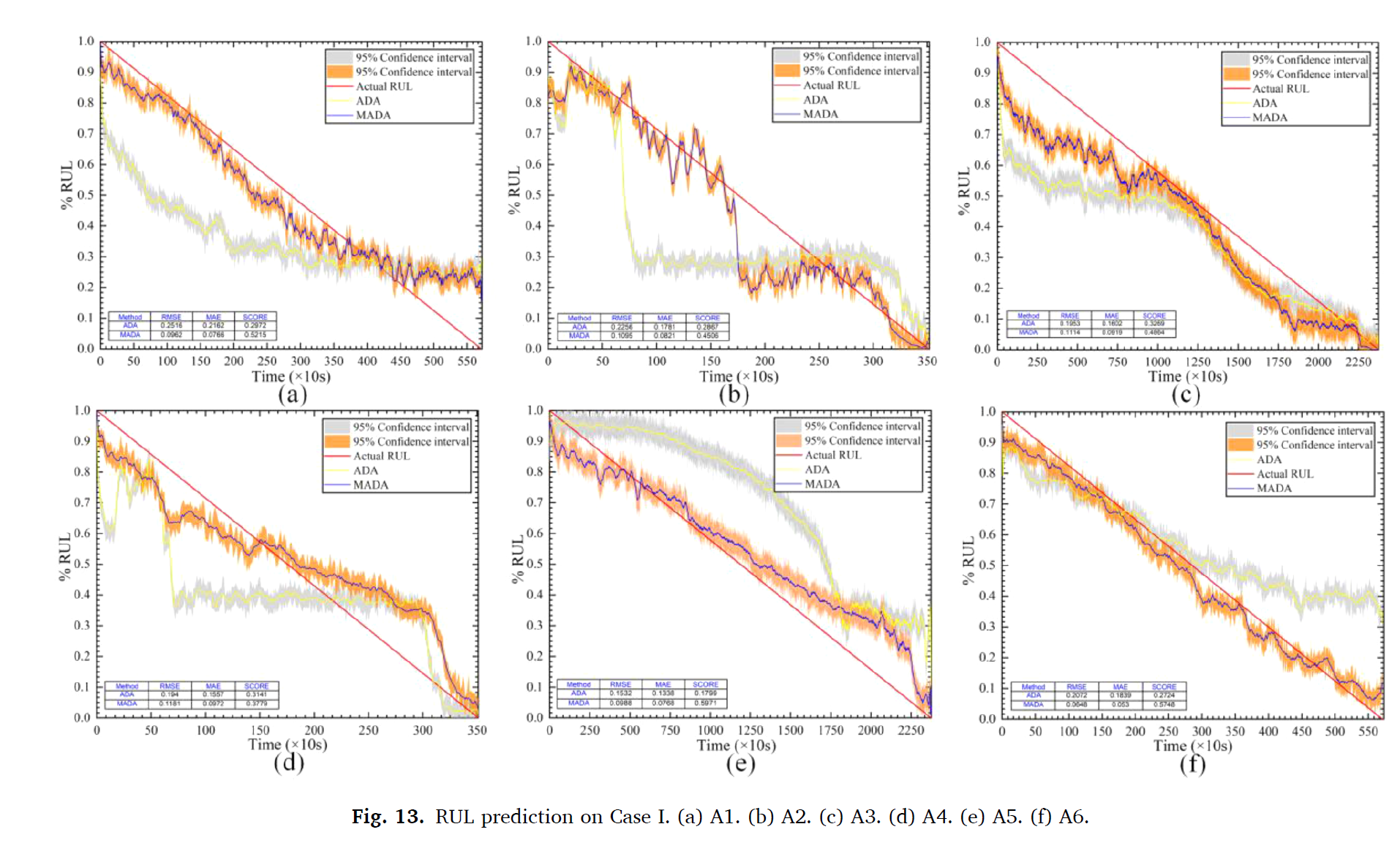
6개의 SOTA와 비교하였다.
- Wu`s: LSTM
- Wang`s: DSCN
- Mao`s: TCA
- Paulo`s: LSTM-DANN
- Ragab`s: CADA
- Zhu`s: MMD-based method
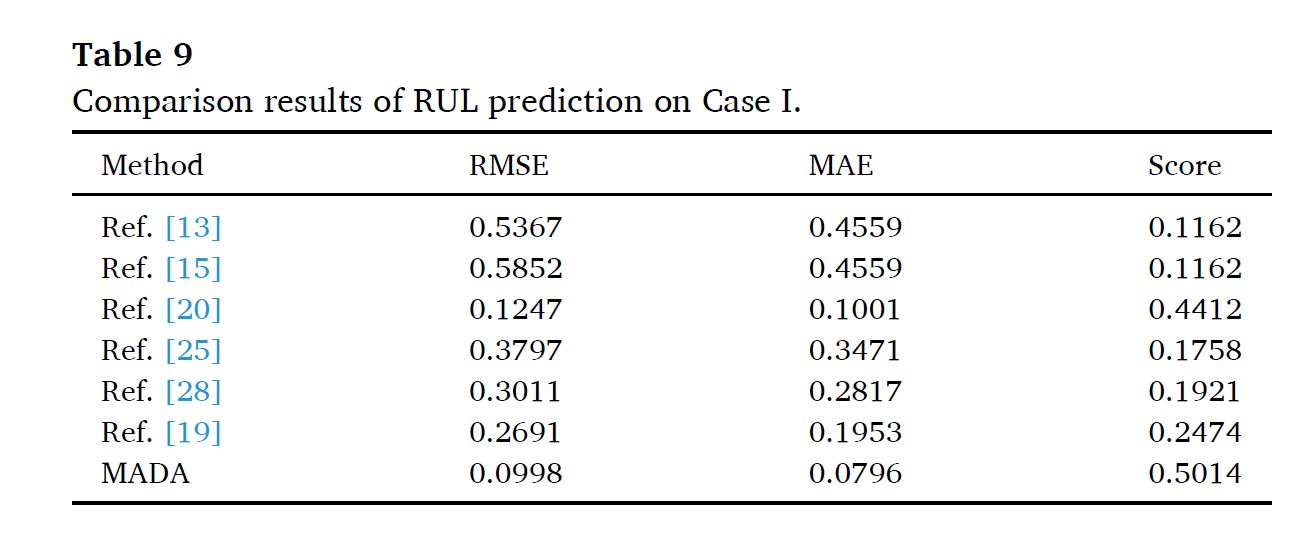
[20]에 비교하여 MADA는 mutual information을 보존하면서 전이학습을 진행하였기 때문에, model에 대한 generalizability를 획득할 수 있었다.
RUL prediction on Case II
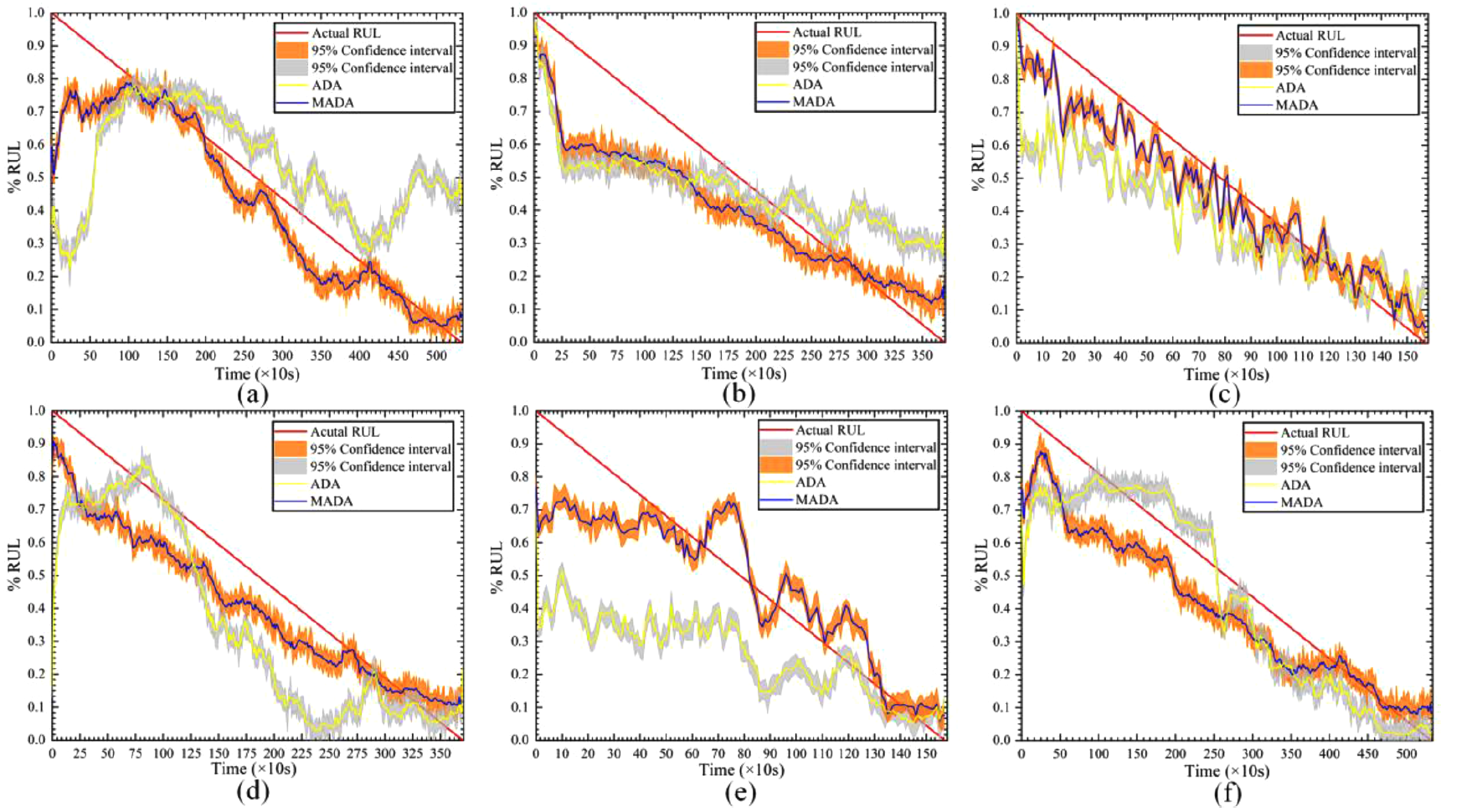
위에서 언급한것중 4개의 SOTA와 비교하였다.
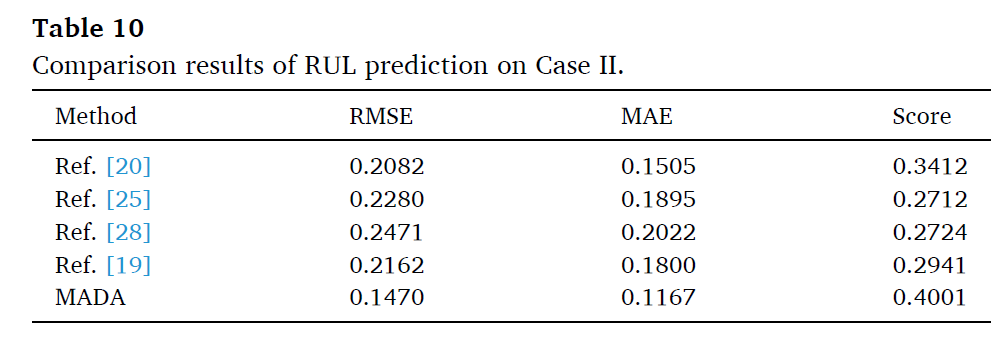
2개의 dataset을 통해서 MADA가 효과적임을 증명하였다.
Prediction error analysis
prediction error distribution을 통해 예측의 안정성을 보인다.

MADA의 error 밴드가 시간이 지남에 따라 fluctuation 하지 않고, 일정하게 유지된다. 이것은 MADA가 prediction error의 deviation을 일정하게 유지한다는 의미이고, 이를 통해서 모든 시나리오에서 일정하게 유지되므로 general하게 모델이 fitting 됨을 의미한다.
Conclusion
MADA를 통해 multiple working condition에서 베어링 RUL을 예측하였다. MADA는 transfer learing을 진행하였고, SPC모듈을 통해 타겟 도메인의 내부 구조를 허물지 않으면서 학습을 진행하였다. dual-self attention 모듈을 통해 multi-scale semantic 을 추출하였다. 또한, 적대학습을 통해 domain invariant feature를 학습하였다.
MADA는 효과적인 퍼포먼스를 보였지만, 학습을 위해서 라벨된 데이터가 많이 필요하다는 단점이 있다. 실제로는 많은 양의 데이터를 학습에 사용할 수 없으므로, 우리의 미래 research는 meta learning을 통해 limited 소스 도메인 데이터로도 학습하여 generalization 성능을 높이고자 한다.

정말 잘 정리된 내용이네요!