What is Bloom Filter
Bloom Filter는 특정 집합내에 특정 원소가 존재하는지 확인하는데 사용되는 자료구조이다. 따라서 I/O의 관점에서 봤을 때, 특정 파일내부에 원하는 데이터의 여부를 빠르게 알 수 있기 때문에 I/O 횟수를 줄일 수 있다는 장점이 있다.
하지만, Bloom Filter는 확률형 자료구조이기 때문에, 올바른 정보만을 확인할 수 없다 (Bloom Filter는 false positive[실제 데이터가 없는데 있다고 판단하는 경우]한 자료구조이다). 하지만 false positive가 발생하는 경우 데이터베이스를 조회하여 데이터의 존재여부를 판단할 수 있기 때문에, 데이터베이스 시스템의 전반적으로는 항상 정해를 도출할 수 있다. 또한 실제로는 데이터가 있는데, 없다고 잘못 판단하는 (false negative)의 경우는 발생하지 않기 때문에 시스템의 입장에서는 사용했을 때 이점이 충분히 존재하는 자료구조이다.
How Bloom Filter Works
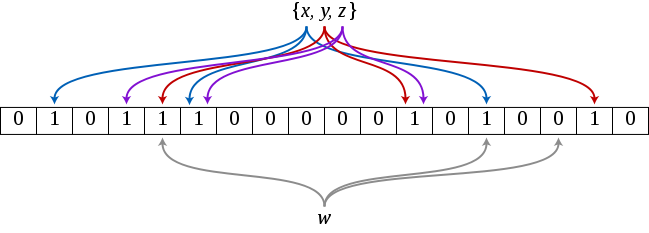
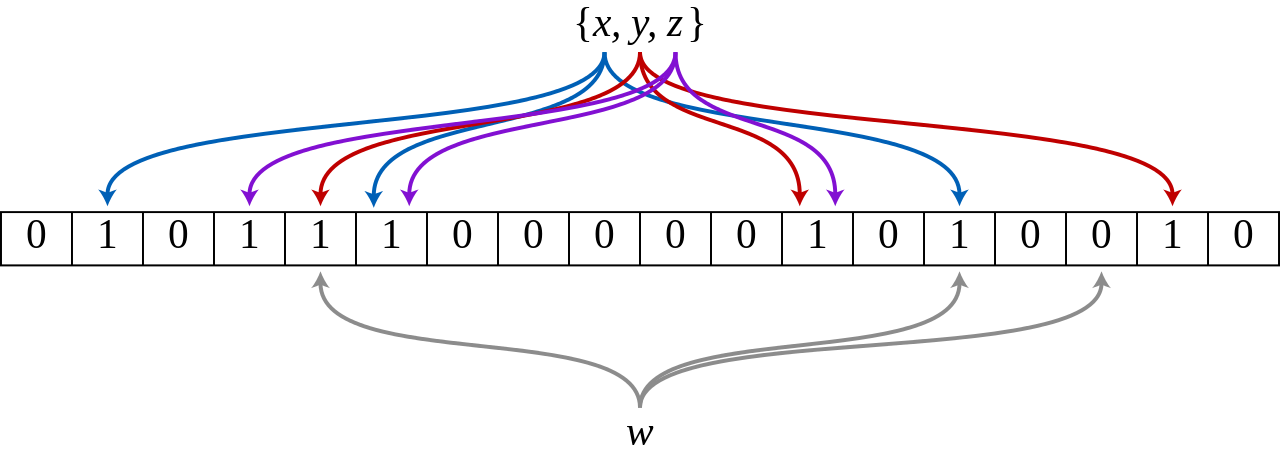
BloomFilter는 앞에서 언급했듯이, 확률성 자료구조이다. 따라서 bloomfilter는 실제 값을 저장하지 않고, 특정 값의 유무를 나타내는 bool type vector를 사용한다. 즉, 특정 원소가 데이터베이스에 삽입될 경우, 3개 이상의 hash function의 결과값에 해당하는 bit에 true(1)을 표시한다. 이후, query가 수행되었을 때, bloomfilter에서 사용하는 모든 hash 함수 값을 계산하고, 이에 대응되는 위치의 bit값이 true(1)로 설정되어 있는지를 검사한다. 만약, 검사한 모든 bit가 1이면 true를 반환하고, 그렇지 않다면 false를 반환하여 해당 집합에 특정 원소가 존재하지 않음을 표시한다.
Bloom Filter는 컨테이너에 실제 데이터를 저장하지 않기 때문에 다양한 타입의 데이터에 대해서도 사용할 수 있고, hash 함수를 잘 구성했다면, 하나의 bloom filter에 interger, string, float등의 데이터를 섞어서 삽입할 수 도 있다.
HBase Bloom Filter
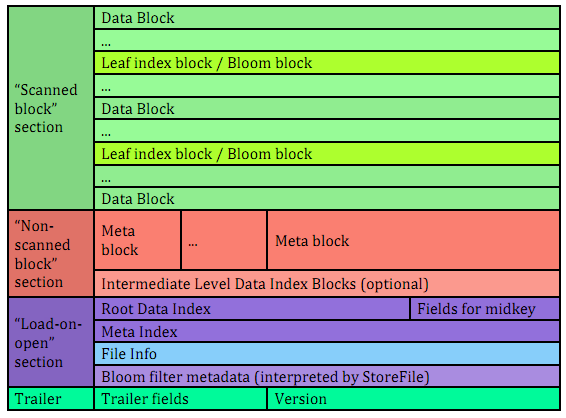
HBase는 Key-Value를 Memstore (In-Memory)에 저장했다가, 일정 크기(Threshold)에 도달하게 되면 HDFS에 flush하여 column-family별로 HFile형태로 저장하게 된다. 각 HFile은 여러개의 datablock으로 저장되어 있으며, 하나의 datablock내부에 여러개의 Key-Value가 존재한다. Datablock의 크기는 configuration으로 설정할 수 있고, default 크기는 64KB이다.
HBase에 get 또는 scan query가 들어오게 되면, 우선적으로 read cache를 순회하면서 찾게 되고, read cache에 없으면 memstore, HFile순으로 순회하며 query를 수행한다. HBase major compation이 수행되지 않으면, 여러개의 ?HFile은 overlap key range를 가지게 되고, 이는 검색과정에 있어서 여러개의 HFile을 open해야 하는 I/O amplification이 동반되게 된다.
이를 방지하기 위해, 각각의 HFile내부에는 Bloom Filter metadata와 Bloom Chunk가 존재한다. Bloom Filter metadata는 각각의 Bloom Chunk의 index를 저장하는 역할을 하고, HFile을 open하기 전, Bloom Filter metadata를 prefetching하여, query에서 요구하는 Bloom Chunk를 positioning하게 된다. 따라서 특정 Bloom Chunk만 읽어서, 해당 Bloom Chunk가 관리하는 datablock 내부에 원하는 데이터가 있는지 검사하게 된다. 만약, bloom filter의 결과로 false가 도출되게 된다면 HFile을 open하여 datablock을 순회할 필요가 없다는 것이고, true를 도출하게 된다면 HFile을 open하여 datablock을 순회하며 데이터를 return 하면 된다. 이로서, HBase의 I/O amplification을 해결할 수 있다.