HBase
1.HBase BlockCache
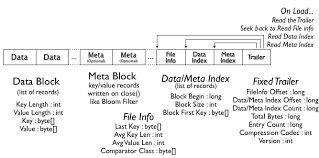
HFile의 구성 요소중 하나인 Data Block은 Key-Value의 형태로 이루어진 데이터를 저장하고 있는 block이다. 즉 Data Block은, MemStore로 부터 Flush operation이 수행되었을 때, MemStore에 저장하고 있던 Key-Va
2022년 1월 12일
2.HBase Overall Structure Part 1.
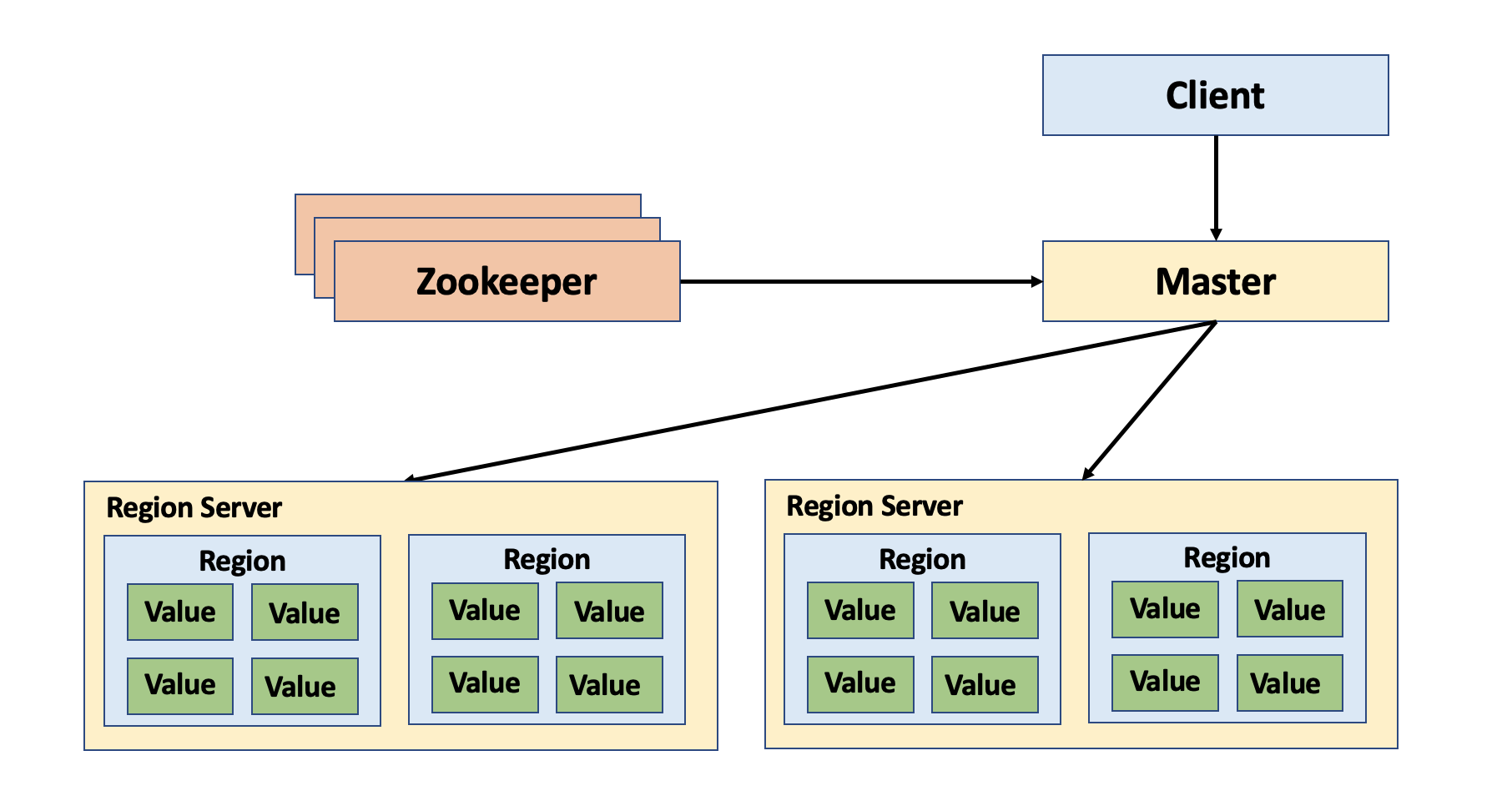
Hadoop Software Library는 간단한 프로그래밍 모델을 사용하여 여러대의 클러스터에서 대규모 데이터 세트를 분산 처리 할 수 있게 해주는 프레임워크이다. Hadoop은 대용량 데이터를 적은 비용으로 더 빠르게 분석할 수 있는 소프트웨어이며, 빅데이터 처리
2022년 1월 18일
3.HBase Overall Structure Part2.
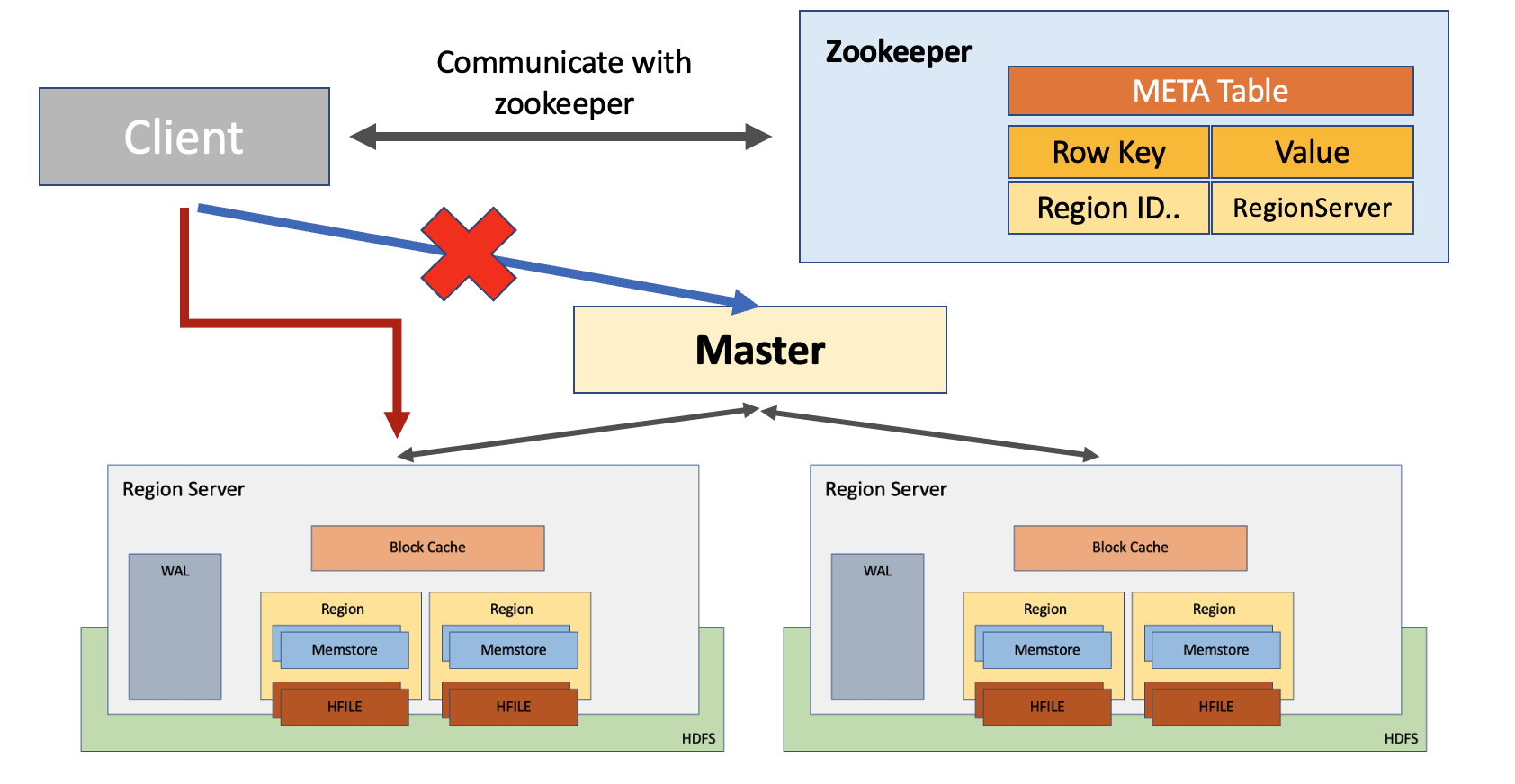
클라이언트에서 데이터를 PUT하라는 쿼리가 발생하면, 해당 데이터는 WAL에 기록된다. WAL은 Write-Ahead Log로 입력된 데이터를 append형식으로 관리한다. WAL에 쌓인 데이터는 Memstore로 copy가 된다. 이때 클라이언트에 데이터가 성공적으로
2022년 1월 18일
4.HBase Bloom Filter
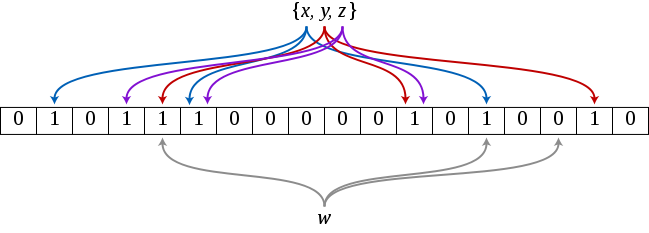
Bloom Filter는 특정 집합내에 특정 원소가 존재하는지 확인하는데 사용되는 자료구조이다. 따라서 I/O의 관점에서 봤을 때, 특정 파일내부에 원하는 데이터의 여부를 빠르게 알 수 있기 때문에 I/O 횟수를 줄일 수 있다는 장점이 있다. 하지만, Bloom Fil
2022년 2월 10일