What is Apache Hadoop
Hadoop Software Library는 간단한 프로그래밍 모델을 사용하여 여러대의 클러스터에서 대규모 데이터 세트를 분산 처리 할 수 있게 해주는 프레임워크이다. Hadoop은 대용량 데이터를 적은 비용으로 더 빠르게 분석할 수 있는 소프트웨어이며, 빅데이터 처리와 분석을 위한 플랫폼 중 사실상 표준으로 자리 잡고 있다. 일반적으로 Hadoop File System (HDFS)과 Map Reduce 프레임워크로 시작되었으나, 여러 데이터저장, 실행엔진, 프로그래밍 및 데이터처리 같은 하둡 생태계 전반을 포함하는 의미로 확장 발전 되었다. Zookeerper (Distributed Coordinator), YARN (Distributed ResourceManager), HBase(Distributeed Database), HDFS(Distributed File System), Kudu(Column-Oriented Storage), Flume, Scribe, Kafka, Pig, Spark... 등의 프레임워크가 추가되었다.
What is Apache HBase
Hadoop platform을 위한 구글의 Big Table을 본보기로 자바를 기반으로 만들어진 분산형 데이터베이스 이다. NoSQL로 분류되며 스키마 지정 및 변경없이 데이터를 저장할 수 있으며 Hadoop의 분산 파일 시스템인 HDFS에서 동작하기 떄문에 가용성 및 확장성을 그대로 이용할 수 있다. 사용자는 HBase나 HDFS에 직접 데이터를 저장 할 수 있고, 사용자가 데이터를 일고 접근하는 것은 HBase를 통한 임의 접근을 허용한다.
What is Column Family
Hbase의 기본단위는 column이고 이 column들이 모여서 column family를 구성한다. 그리고 이 column family가 모여서 최종적으로 table을 구성한다. 각 table에 들어가는 각 row는 rowkey를 가지고 식별할 수 있다. NoSQL에서는 데이터의 유연성을 적극 활용해 유사한 column뿐만 아니라 column명이 columns라는 속성에 데이터로 저장되고 value 속성에는 해당 column값만 존재한다. 즉, 전통적인 관계형 모델에서 수평적으로 데이터를 저장하는 것과 달리 NoSQL모델에서는 데이터를 수직적으로 쌓아가는 형식이다. 즉 관계형 모델에서 유연성을 극대화 한 모델이라고 볼 수 있다. 또한 Sparse 한 데이터를 저장하는 NoSQL의 특징을 봤을때 모든 필들에 값을 채울 필요가 없기 때문에 column 단위로 데이터를 쓰고 읽는 것이 훨씬 유리하다.
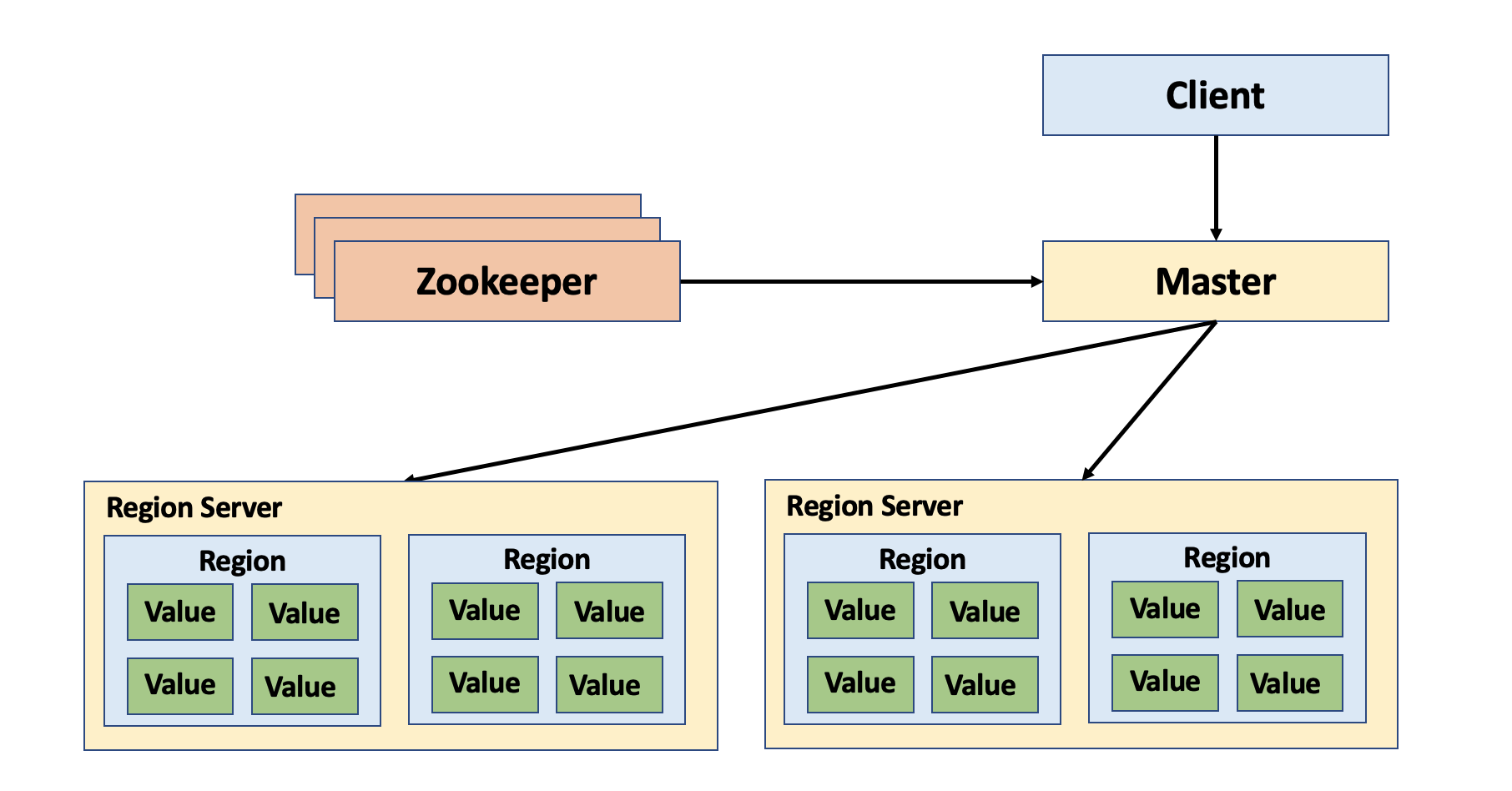
HBase Architecture
HBases는 물리적으로는 Master-Slave 구조로 3가지 서버의 구성 요소를 가집니다.
Master Server (HMaster)
Region을 RegionServer에 할당하고 할당 업무를 위한 zookeeper의 도움을 받는 작업을 수행한다. 그리고 RegionServer에 퍼져있는 region들의 load balancing 통해 클러스터의 상태 유지를 수행한다. 특정 REegi HMaster는 HDFS의 Namenode에서 실행된다. 만약 HBase Master가 fail할 경우, Backup Master가 기존 정보를 바탕으로 서비스를 제공할 수 있다.
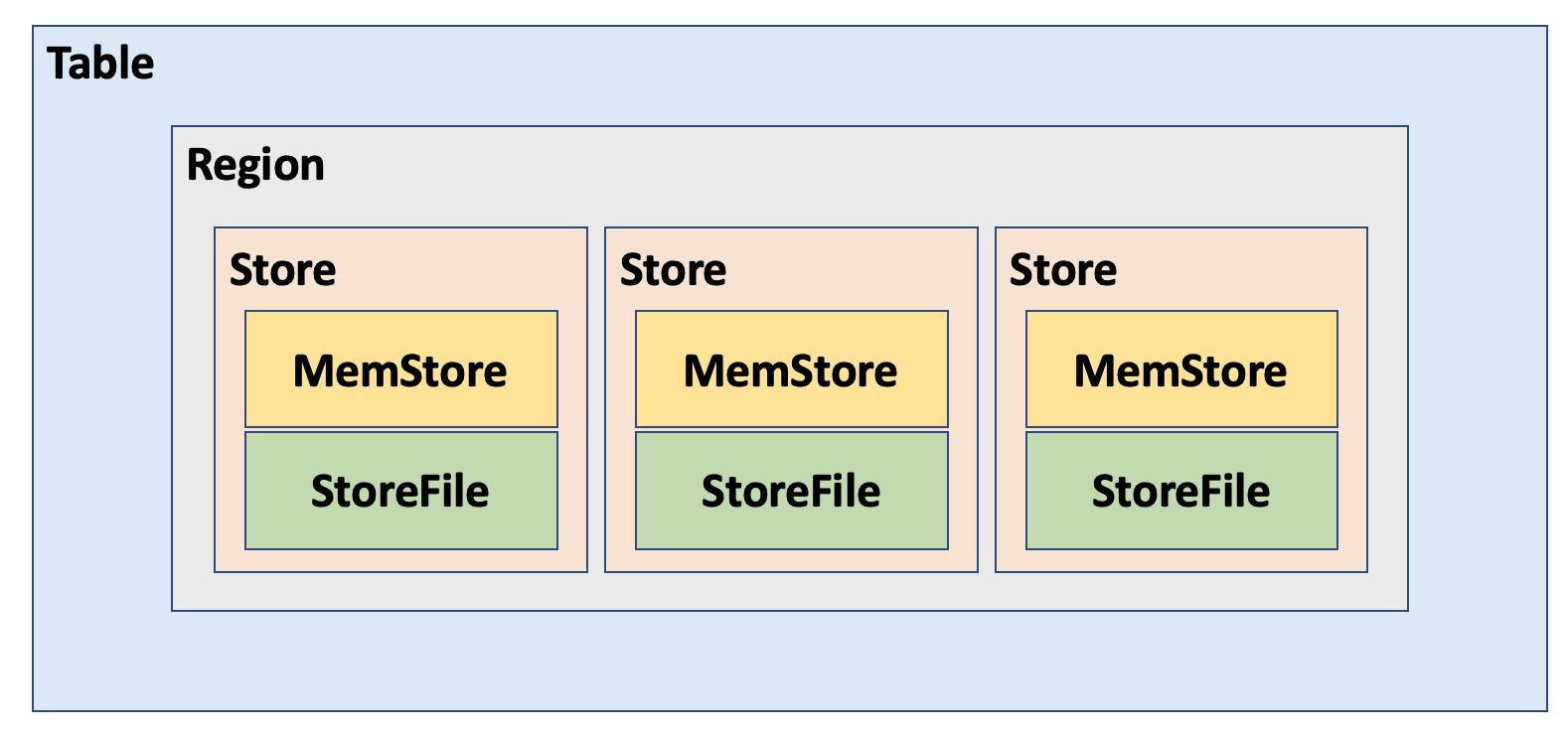
HBase Region
HBase Region이란, table을 위한 분산 및 가용성의 기본 요소 단위이다. 그리고 Column Family 마다 Store를 포함하고 있다. Region들의 집합은 Start Key와 End Key를 통해서 추출된다. 또한 Region은 HBase에서 수평확장(Scale-in/out)의 기본단위이다. 다시말해 HBase Table의 row들을 수평으로 분할하고 이것을 하나로 묶은 것이 region이다. 초기상태의 table은 오직 한개의 region에만 있다. 만약 region에 많은 row들이 추가되서 그 크기가 커지면, median key를 이용해서 region을 반으로 나눠서 저장한다.
(Auto-Sharding-시스템의 테이블이 너무 커졌을 때 동적으로 재분배 해주는 기능)Concept of Store
Region 내부에 저장되어 있는 데이터는 각 Column Family 마다 Store로 분류가 된다. 따라서 하나의 region 내부에는 column family마다 memstore가 존재하며, 각 memstore가 flush 될때 각 column family는 StoreFile(HFile)로 저장이 되게 된다.
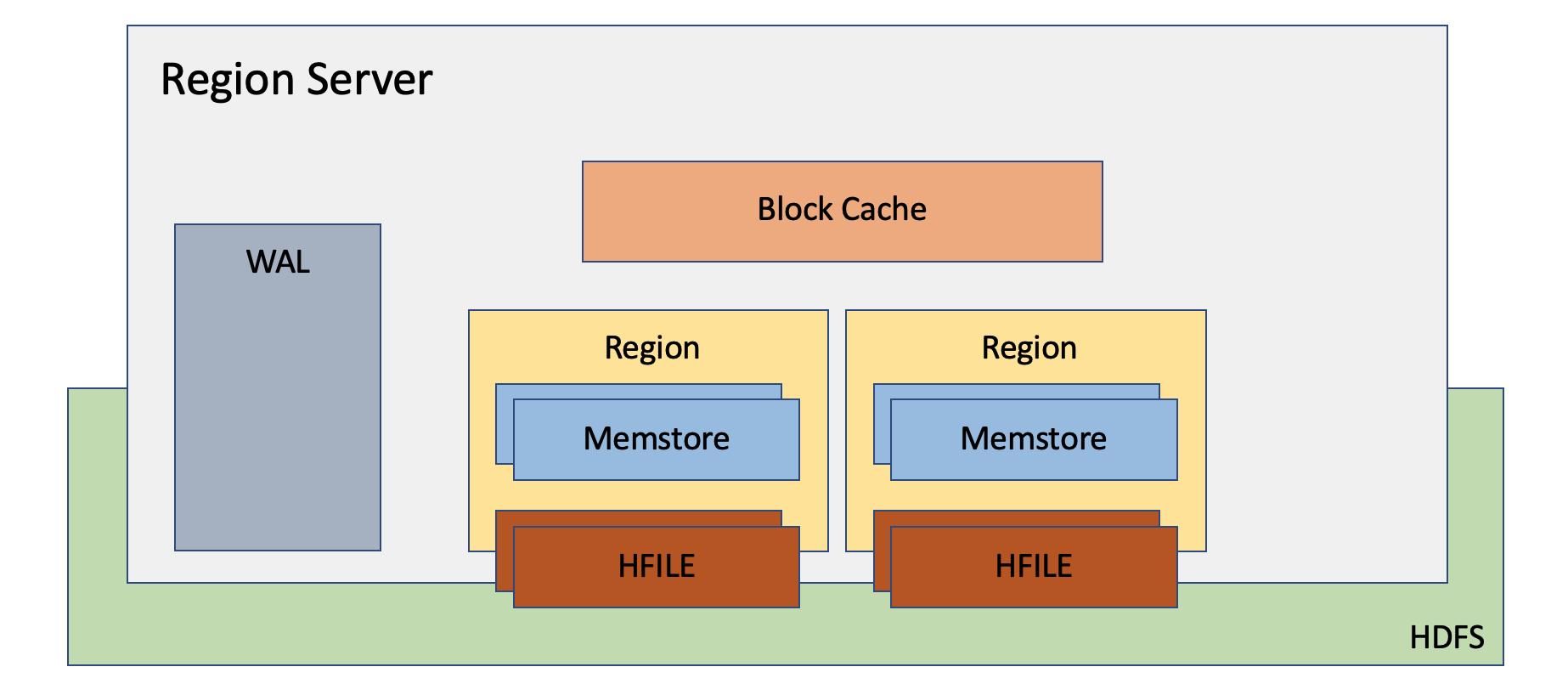
HBase RegionServer
Table의 row를 나눠서 수평 분할한 것이 region 이라면 RegionServer는 이러한 region을 가지고 있는 서버를 말한다. 따라서 regionserver는 region을 관리하는 주체를 의미한다. 이러한 regionserver는 hadoop의 datanode에서 실행된다.
RegionServer Components
1. WAL: Write Ahead Log로 Distributed File System (HDFS)에 기록된다. 데이터는 스토리지에 저장되기 전에 WAL에 먼저 저장이 된다. 이는 System Failure에 의해 발생할 수 있는 데이터 손실을 복구하기 위해서 사용된다.
2. BlockCache: Read Cache이다. 자주 접근하는 데이터는 in-memory상에 저장해서 read performance를 높인다.
3. Memstore: Write Cache이다. 아직 디스크에 기록되지 않는 데이터들이 저장된다. 데이터는 디스크에 쓰기전에 먼저 정렬이 된다. 각 region의 column family당 하나의 Memstore가 있다.