
(Ubuntu 18.04.6 LTS)
2022.05.04
프로그래머스 자율주행 데브코스 3기
Labeling
Labeling(Annotation, Tagging)은 raw data를 유의미한 작업에 사용하도록 데이터를 만드는 작업입니다. 컴퓨터 비전에서는 이미지에 필요한 작업, 결과를 미리 입력하는 형태로 이루어집니다.
딥러닝, 머신러닝은 모델링하는 것보다 데이터와 관련된 작업을 하는데 더 많은 시간을 씁니다. 검증된 데이터를 사용하면 labeling 관련 오류는 없을 수 있는데, 현실에서는 직접 데이터를 만들어야만 하는 경우가 많습니다. 풀어야 하는 문제가 다를 수 있고, 같다고 해도 환경 요소들이 다르기 때문입니다.
데이터를 다루는 작업을 위임하기 위해서는 데이터 구축 프로세스를 명확히 할 필요가 있으며, labeling 과정을 경험해보는 것도 도움이 될 수 있습니다.
이미지 데이터를 labeling하는 툴 중 CVAT를 이용해 labeling을 해보았습니다. 설치 관련 내용은 CVAT 설치 가이드를 참고하면 됩니다. 리눅스에서 잘 따라 갔는데 안 된 것 같다면 재부팅이 도움이 될 수도 있습니다 :)
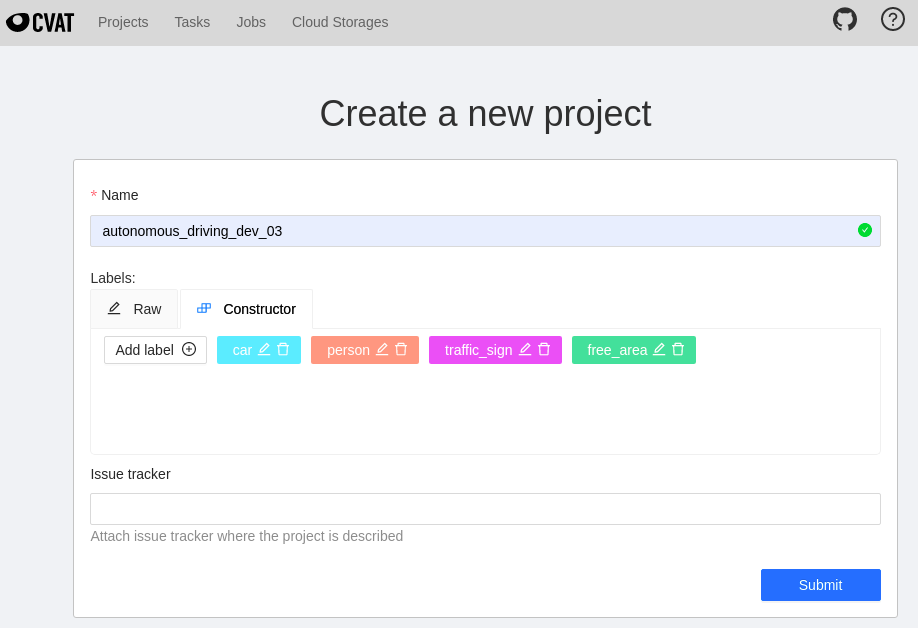
설치 절차를 따른 후, chrome에서 localhost:8080에 접속해 로그인한 뒤, 프로젝트를 만들어줍니다. constructor를 이용하면 쉽게 만들어 줄 수 있습니다. Submit을 눌러주면 프로젝트가 생성됩니다.
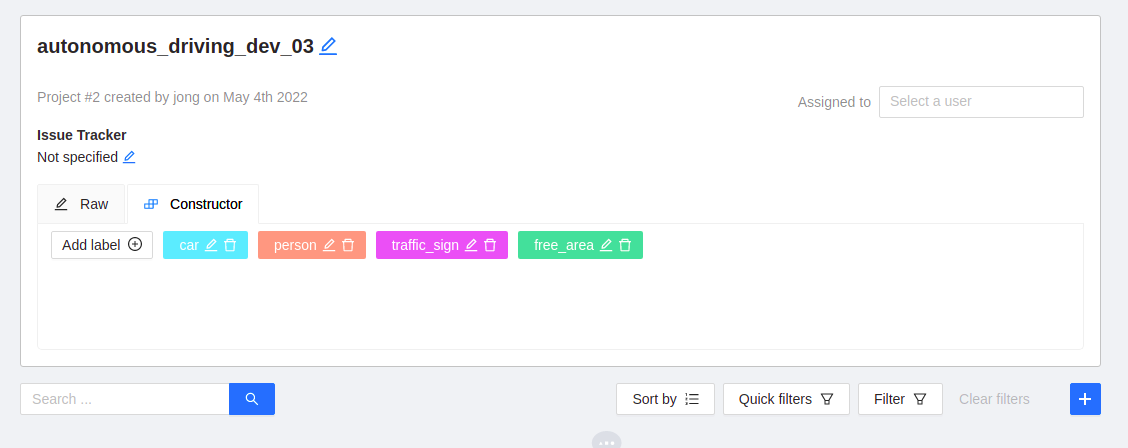
해당 프로젝트로 이동 뒤 우측 하단의 + 모양을 눌러 task를 추가합니다.
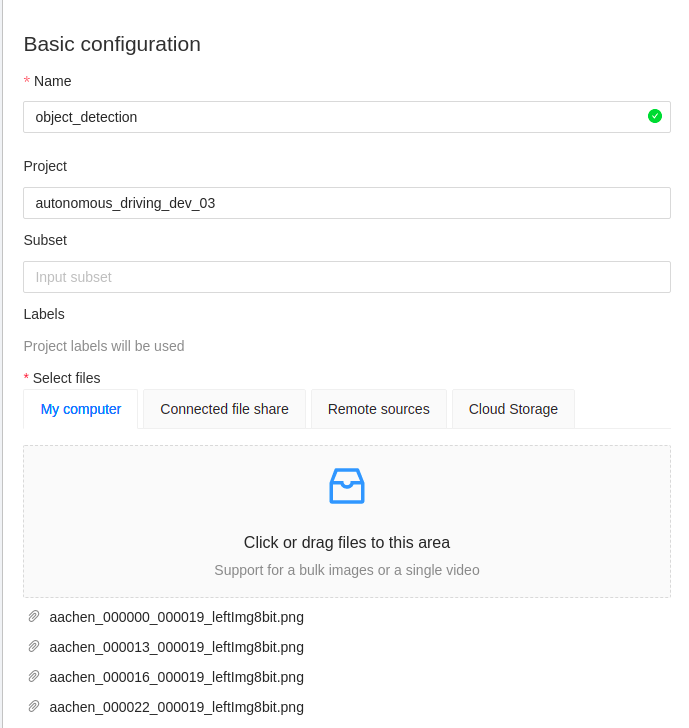
Task의 이름을 설정하고, 파일을 선택해줍니다.
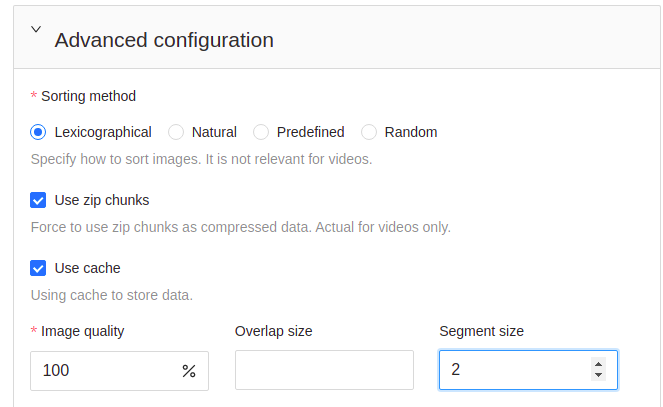
아래쪽에서 image quality는 이미지 압축 여부(기본값 70%)를 정하고, segment size는 나눌 개수를 정합니다. 이후 submit을 눌러 task를 생성할 수 있습니다.
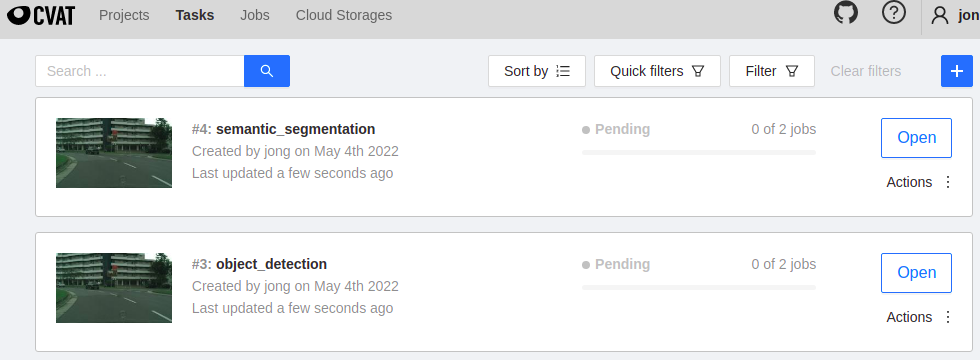
이후 task로 이동하면 위와 같이 나오게 됩니다. 해당 task 중 하나를 선택해 들어갑니다.
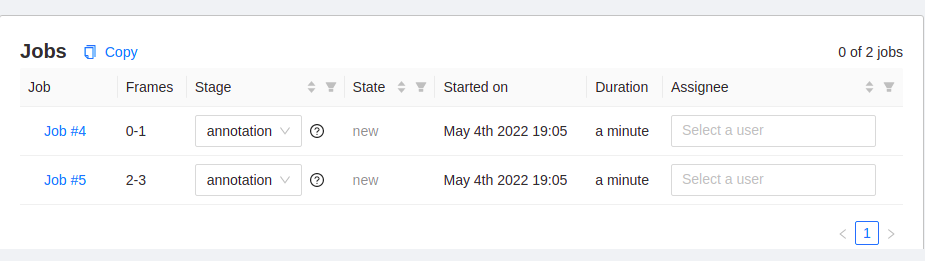
위와 같은 화면이 나오게 되는데, segment size가 2였기 때문에 2개로 나누어진 것을 확인할 수 있습니다. Assignee에 user를 선택하고, job#4와 같은 항목을 눌러 이동합니다.
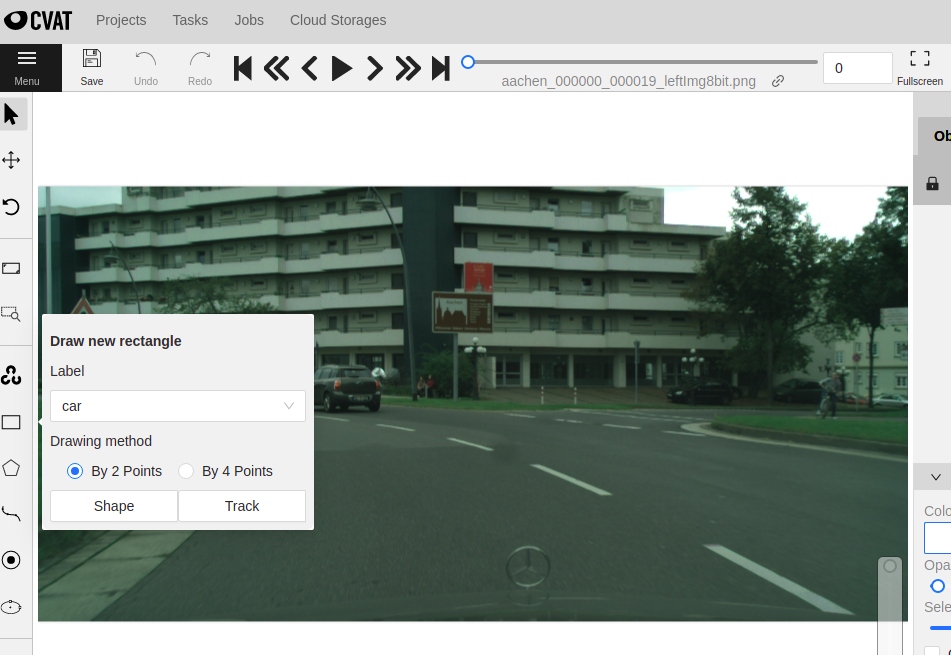
labeling 화면이 나오게 되는데, 스크롤로 확대 축소, 드래그로 이동 등을 할 수 있습니다. 왼쪽의 사각형을 고르고 shape을 누릅니다.
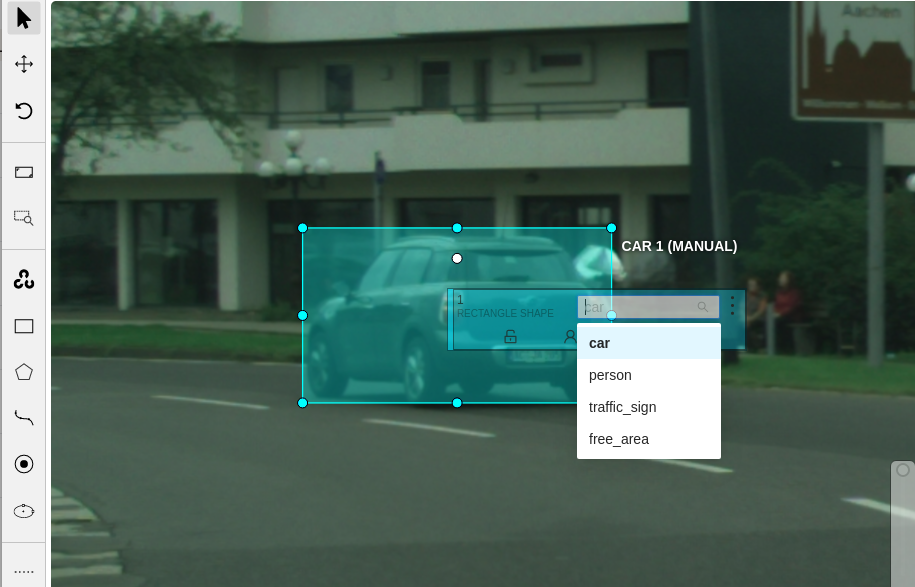
좌클릭 한번으로 시작점, 한번 더 좌클릭으로 사각형을 만듭니다. 우클릭을 해서 나오는 화면에서 project에서 설정했던 label 중 선택합니다.

위와 같은 방식으로 학습에 필요한 데이터를 만들 수 있습니다.
Finish the job을 누르면 task 창에서 해당 segment가 완료처리가 됩니다. Save를 눌러서 현재까지의 진행을 저장할 수 있고, Export를 이용해서 외부로 라벨링된 데이터를 내보낼 수 있습니다.
Segmentation을 위해서는 영역을 더 정확하게 선택하는 것이 필요하며, 다각형을 눌러 Shape을 골라줍니다.

점들을 이어 나가면 되며, 이전을 취소하고 싶으면 우클릭하면 됩니다. 완료시에는 n을 눌러 마무리할 수 있습니다. 그려진 상태에서 shift를 누른 상태로 점을 클릭하면 해당 점에서 부터 추가할 부분을 그릴 수 있습니다. alt를 누른 상태로 점을 클릭하면 해당 점이 사라집니다.

segmentation을 위한 라벨링을 한 결과입니다.
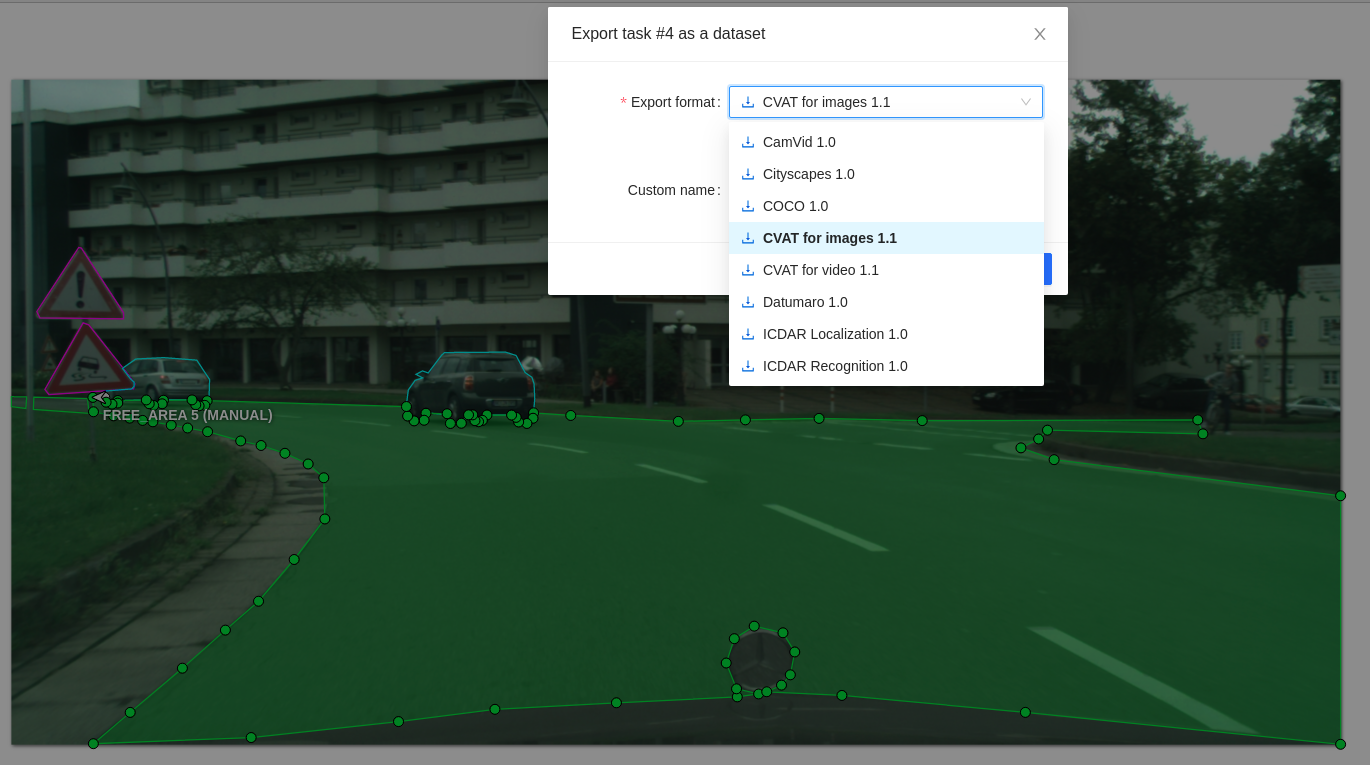
export 방식에는 여러가지 방식이 있는데, cityscapes 1.0을 이용해서 일단 진행하였고, 이미지 데이터 저장에 체크를 눌러주었습니다.
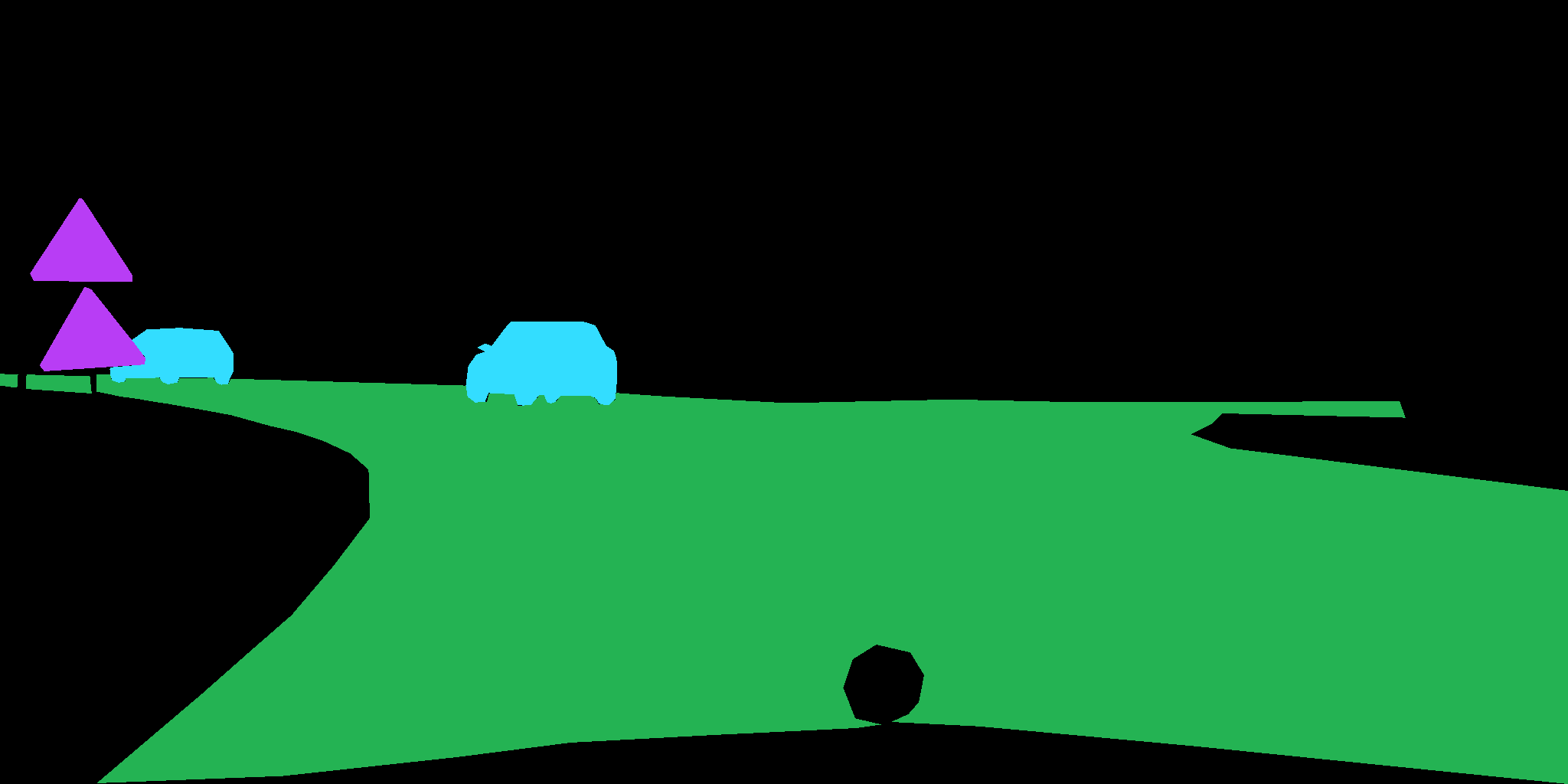

그 결과 이미지와 라벨링한 데이터가 포맷에 맞게 나타나는 것을 볼 수 있었습니다.

3D 인식을 위해서 cuboid를 활용할 수 있습니다. 다만, 데이터 라벨링과 검증 모두 어려움이 있다는 것을 확인할 수 있었습니다.
Augmentation
Data Augmentation은 이미지를 여러 처리를 하여 학습 이미지를 증강하는 방식입니다. Data labeling은 중요하지만, 많은 비용과 노력이 듭니다. 데이터는 많을수록 좋고, 환경은 변화하기 때문에 언제나 새로운 데이터가 필요하지만, data labeling만으로 해결할 수는 없기 때문에, 증강 방식을 고려할 수 있습니다.
1만장 데이터가 최소 필요하다면, 5천 장을 labeling을 통해 만들고 augmentation을 활용해보는 것도 고려해볼 수 있습니다. 증강 방식에는 색공간을 변형하는 방식, 기하학적 대칭 등을 사용하는 방식, 왜곡을 넣는 방식, 노이즈를 추가하는 방식들이 있을 수 있습니다. 증강한 데이터는 데이터로 가지고 있기 보다는 랜덤하게 생성하여 학습 중에만 사용하는 것이 디스크 낭비를 줄일 수 있습니다.
주의할 점은 데이터 증강 시, 상황에 따라 적절하지 못한 데이터를 만들 수 있다는 점입니다. 신호등과 같이 색상 정보를 활용하는 데이터에 색공간의 변형이 적용되면 오류를 만들어 낼 수 있습니다. 또한 라벨링한 값들도 조정을 해주어야 합니다.
유용한 데이터 증강 라이브러리로는 imgaug와 albumentation이 있습니다. 이 중 albumentation을 사용한 예제를 보았습니다.
예제 1 Image augmentation
import albumentations as A
import cv2
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
'''
Compose를 이용하여 여러가지 변환을 한번에 수행할 수 있음.
'''
image = cv2.imread("/path/to/image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
transformed = transform(image=image)
transformed_image = transformed["image"]
another_transformed_image = transform(image=another_image)["image"]
'''
albumentation을 활용한 경우에 dictionary 형태로 나오게됩니다.
["image"]를 뒤에 붙여줌으로써 해당 데이터만 사용할 수 있습니다.
{'image': array([[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
...
'''예제 2 Bounding box for object detection

Bounding box를 표현하는 방식은 여러가지가 있습니다. 이미지 변환 과정을 거치고 나서 해당 값들을 계산하기 위해서는 어떤 형식인지를 알아야 합니다.
import albumentations as A
import cv2
transform = A.Compose([
A.RandomCrop(width=450, height=450),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
], bbox_params=A.BboxParams(format='coco'))
'''
bbox_parmas 부분이 추가되었습니다. 여기서는 format을 coco를 사용하였으며,
[x_min, y_min, width, height]를 사용합니다.
'''
image = cv2.imread("/path/to/image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
bboxes = [
[23, 74, 295, 388],
[377, 294, 252, 161],
[333, 421, 49, 49],
]
class_labels = ['cat', 'dog', 'parrot']
transformed = transform(image=image, bboxes=bboxes, class_labels=class_labels)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
transformed_class_labels = transformed['class_labels']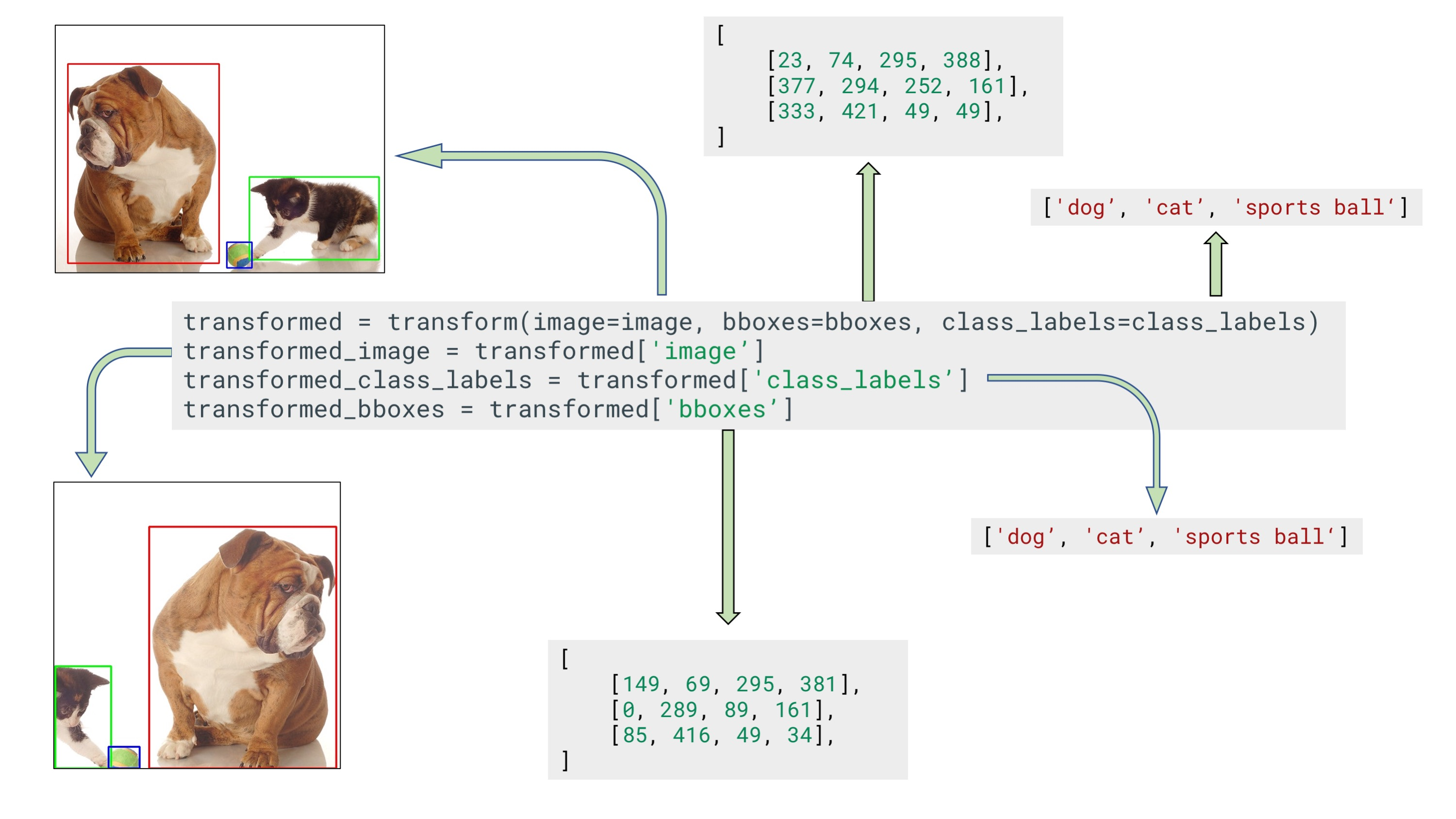
예제 3 Mask augmentation for segmentation
import albumentations as A
import cv2
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
image = cv2.imread("/path/to/image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread("/path/to/mask.png")
mask_1 = cv2.imread("/path/to/mask_1.png")
mask_2 = cv2.imread("/path/to/mask_2.png")
mask_3 = cv2.imread("/path/to/mask_3.png")
masks = [mask_1, mask_2, mask_3]
transformed = transform(image=image, mask=mask)
'''
mask=mask 부분만 추가하면 똑같이 변형됩니다.
'''
transformed_image = transformed['image']
transformed_mask = transformed['mask']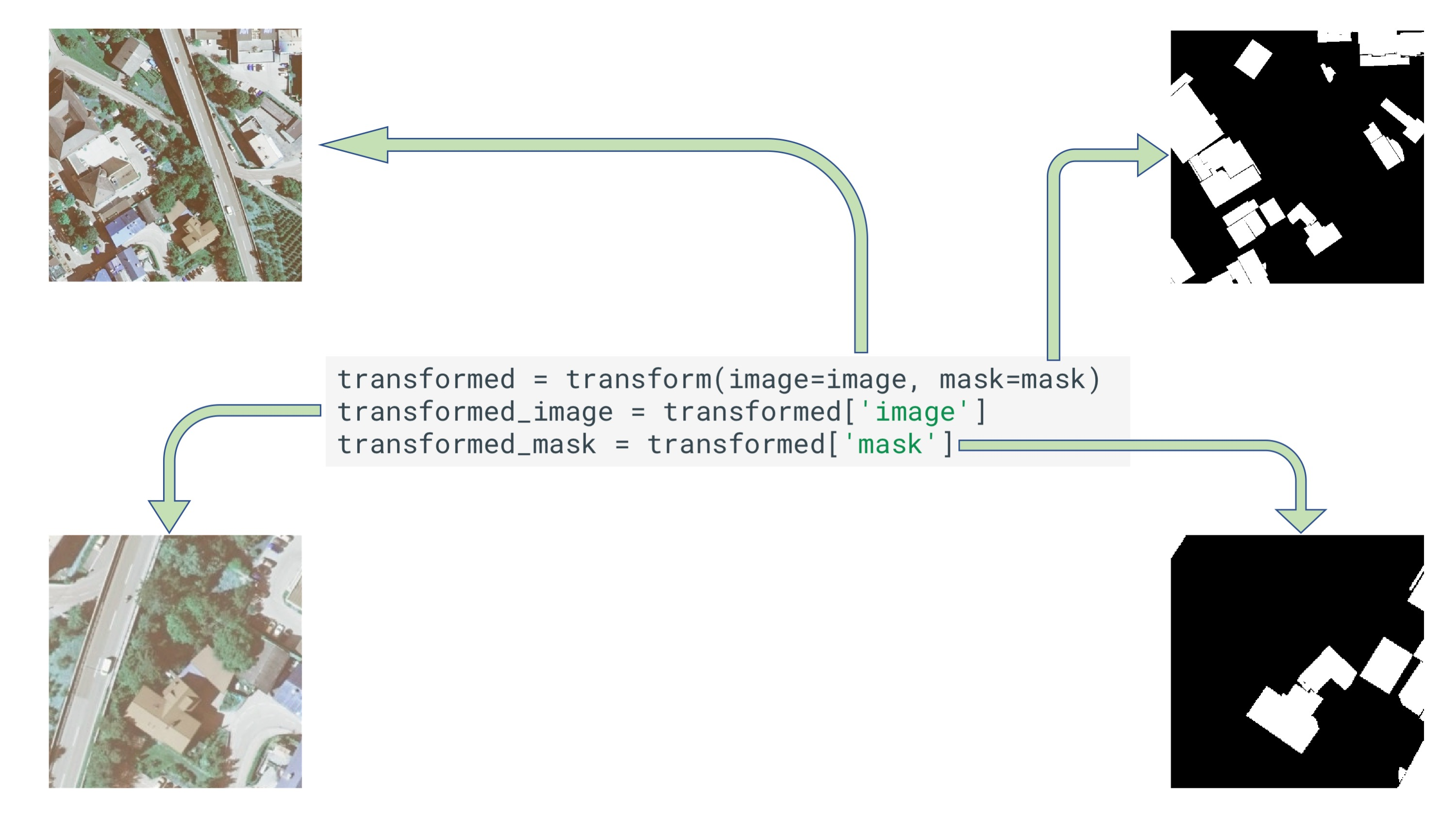
transform부분에 mask=mask만 추가하면 동일하게 변환됩니다.
기타 어디에 적을지 모르겠는 것들
Docker
1. 환경구축이 간단함. -> 개발 시 OK, 첨부를 같이 해야함.
2. 개발단계, 2~3명 개발자가 있을 때. (container)
Linux와 Window의 가장 큰 차이점: File system
WSL2를 사용하는 경우 Windows 환경에서도 GPU 사용도 가능.
Main OS는 20.04를 많이 사용. Docker로 18.04 사용 가능.
-d : daemon, background 동작
labeling 처리 명확하게 해야 분업 가능해 보인다. augmentation 다양하게 잘 뽑아내면 좋을 것 같다.
