2022.04.29
밑바닥부터 시작하는 딥러닝

https://book.naver.com/bookdb/book_detail.nhn?bid=11492334
Chapter 6 학습 관련 기술들
Optimizer
신경망 학습은 loss function을 최소화하는 parameter을 탐색하는 것으로 optimization(최적화) 문제이다. 신경망 학습에서 최적화 문제를 풀 때는 기존의 optimizer를 선택할 수 있다. SGD, Adam 등을 주로 이용하게 되지만, 상황에 따라 적합한 optimizer가 다를 수 있다.
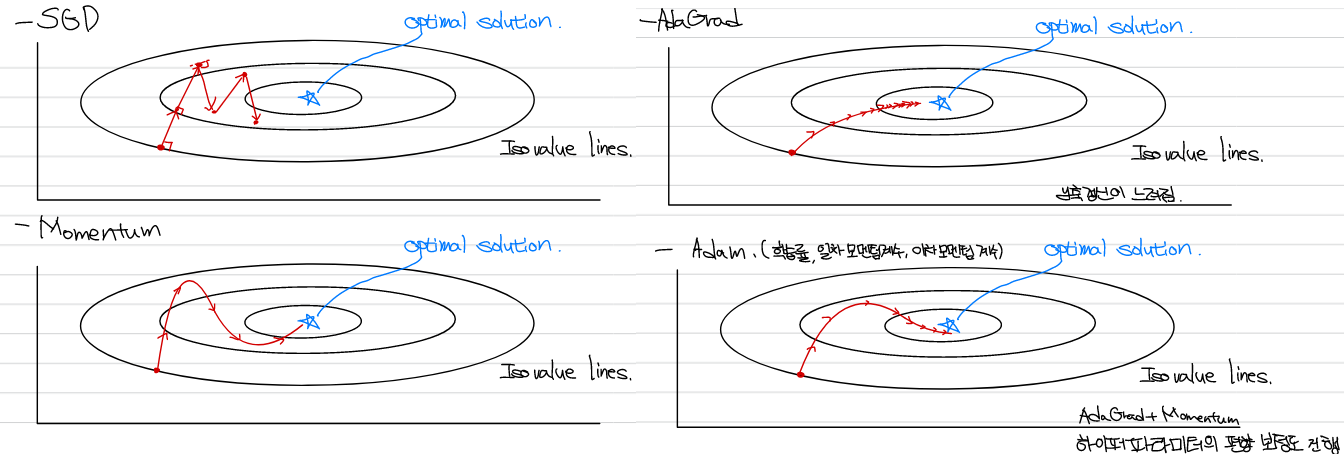
SGD(Stochastic Gradient Descent)
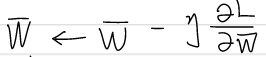
이전 chapter 4에서 볼 수 있었던 방식이다. 학습률을 설정하여 가중치를 갱신하는 방식으로, 구현이 용이하며 안정성이 높다. Anistropy(비등방성)을 가지는 함수에서는 탐색경로의 비효율성이 존재하며, 안장점 문제가 있을 수 있다.
Momentum

공이 곡면을 구르듯이 학습이 진행된다. 는 속도이며 는 값이 0에 가까울 때 진행하던 방향으로 천천히 이동시키는 역할을 하며 0.9 등의 값을 사용한다.
AdaGrad

학습률 감소에 초점을 맞춘 방식이다. 가 기존 기울기 값의 제곱을 누적하여 크게 갱신된 원소는 학습률이 낮아지는 방식으로 매개변수 원소마다 다르게 적용된다. 일정 갱신 이후에는 갱신이 안된다는 단점이 있으나, 과거 기울기의 영향을 줄이는 방식으로 지수 이동 평균(Exponential Moving Average)등을 사용할 수 있다. RMSProp은 지수 이동 평균을 이용하는 방식이다.
Adam
Adam은 AdaGrad와 Momentum을 융합한 방식으로 하이퍼 파라미터의 편향 보정도 이루어진다.
가중치의 초기값
Overfitting은 일반적으로 가중치의 값이 큰 경우에서 잘 일어난다. 이를 개선하기 위해 가중치의 값을 줄이는 방식이 고안되었다. 기본적으로는 가중치의 초기값을 표준정규분포에 0.01을 곱하는 형태로 사용했다.
※ 가중치의 초기값으로 0을 사용하지 않는 이유
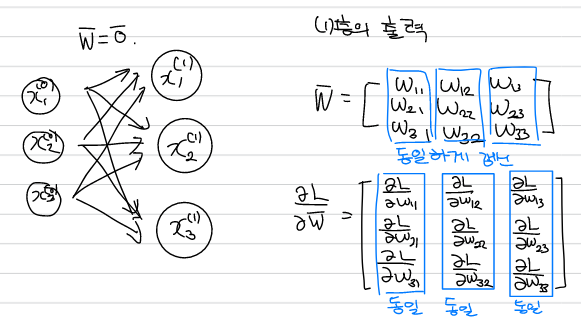
가중치가 같은 값을 가지는 경우 모든 층에 같은 값이 전달되어 층을 깊게 쌓는 의미가 없어진다. 가중치의 동일한 갱신을 막기 위해서는 초기값을 무작위로 설정해야 한다.
※ 가중치의 초기설정과 Gradient Vanishing
- 표준편차를 크게하고 sigmoid를 활성화 함수로 사용하는 경우
출력값이 0과 1에 다수 분포하게 되는데, sigmoid의 미분값이 0에 가까워져 역전파 기울기가 작아지다가 소실될 수 있다. - 표준편차를 작게하고 sigmoid를 활성화 함수로 사용하는 경우
출력값이 0.5 주변 집중되며 활성화값이 치우쳐져 표현력이 제한된다.
Xavier 초기값 (Xavier, Yoshua)
활성화 함수가 선형 함수일 때 활성화값을 광범위하게 분포 목적으로, 앞 계층의 노드가 개면 표준편차가 인 정규 분포에서 초기값을 설정하는 방식이다. Sigmoid 함수와 tanh 함수에서 사용할 수 있다.
He 초기값(Kaiming He)
활성화 함수로 ReLU를 사용할 때, 더 넓게 분포시키기 위해 앞 계층의 노드가 개면 표준편차를 의 정규 분포에서 초기값을 설정하는 방식이다. 층이 깊어져도 분포가 균일하기 때문에, 더 깊은 구조에 적합하다고 알려져있다.
Batch normalization
배치 정규화는 초기값을 균일하게 분포하는 것처럼 각 층이 활성화를 적당히 퍼뜨리도록 강제하는 방식이다.
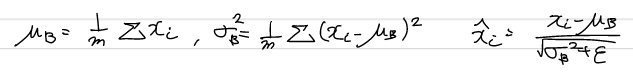
학습시 mini-batch 단위로 평균이 0, 분산이 1이 되도록 정규화를 한다. 활성화 함수 앞 혹은 뒤에 삽입함으로써 데이터 분포가 덜 치우치게 할 수 있다.
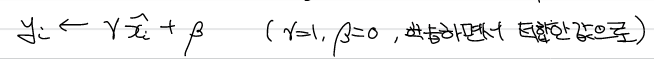
또한 배치 정규화된 데이터에 대해 고유한 확대(scale)과 이동(shift) 변환을 수행하며, 이 값들은 학습하면서 적합한 값으로 조정해 나간다.
배치 정규화는 학습 속도 개선, 초기값 의존을 낮추며, 오버피팅을 억제해 드롭아웃 등의 필요성을 감소시킨다.
가중치 감소
오버피팅은 매개변수가 많고 표현력이 높은 모델, 훈련데이터가 적은 모델에서 일어나며, 오버피팅 발생시 가중치의 값이 큰 특징이 있었다. 이를 해결하기 위해 초기값으로 가중치를 제한하는 방식이 있었다.
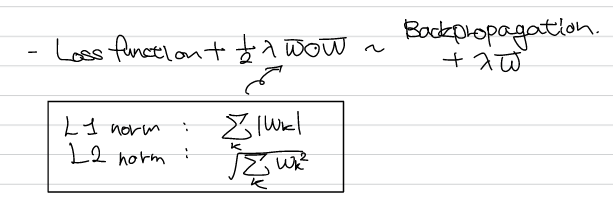
위의 방식은 손실함수에 가중치의 크기 또한 추가하는 방식으로 가중치 값이 클수록 손실함수가 증가하기 때문에 감소하는 목적을 이룰 수 있다. 이 때 는 가중치 감소를 위한 인자로 조절하는 값이다.
이 방식을 사용하는 경우 훈련데이터의 정확도가 100%에 도달하지 않는 것을 확인할 수 있다.
Dropout
신경망 모델이 깊어지면 오버피팅을 가중치 감소만으로 해결하는데에 어려움이 있다. Dropout은 뉴런을 임의로 삭제하면서 학습하는 방식이다.
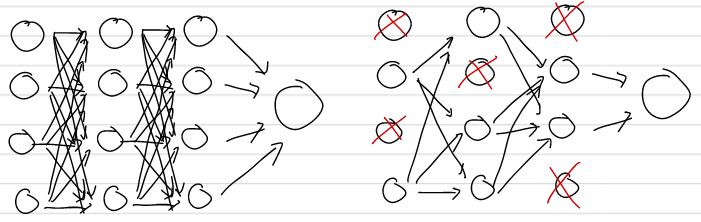
결과적으로 훈련데이터와 시험데이터의 차이가 줄게 되며, 표현력을 키우면서 오버피팅을 방지할 수 있다.
Hyperparameter 최적화
Hyperparameter 최적화를 위해서는 전용 데어터로 검증 데이터를 사용하며, 데이터의 20% 정도로 정할 수 있다. 최적화를 위해서는 범위를 줄여나가는 방식으로 진행되는데, grid search보다는 무작위로 샘플링해 탐색하는 편이 더 좋은 결과를 낸다고 알려져 있다. 최적화 시 오랜 시간이 필요하므로 epoch를 작게 설정하고 평가하는 것이 좋다.
하이퍼파라미터 최적화 과정
0. 하이퍼 파라미터 범위 설정
1. 범위 내 무작위 샘플링
2. 샘플링 값 사용해 학습. 검증 데이터로 평가.
3. 1, 2를 반복 후, 결과를 보고 범위를 수정.
위의 방식 이외에도 Bayesian optimization이 가능하다.
(Practical Bayesian Optimization of Machine Learning Algorithm 참고)
Chapter 7 CNN
이전의 fully connected layer는 전체데이터가 관여하기 때문에 이미지의 형상이 무시되는 경향이 있었다. CNN은 이미지를 3차원으로 받으며, 형상을 이해할 가능성이 있다. CNN은 이미지, 음성 분석 시에 주로 사용되는 방식이며, 입출력 데이터를 feature map이라고도 한다.
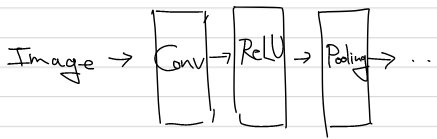
Fully Connected layer와 비교하였을 때 Convolution layer와 Pooling layer에서 차이가 있다. Pooling 계층은 생략하는 경우도 있다.
Convolution layer
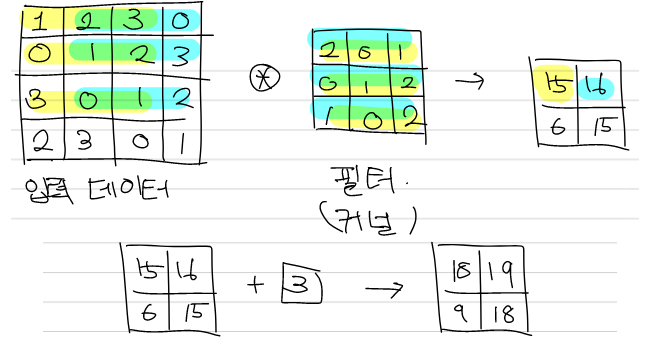
Convolution layer에서는 입력데이터에서 Window를 일정 간격(stride)만큼 이동한 뒤 각 원소끼리 곱하고 총합을 구하는 fused multiply-add를 수행한 후, 편향을 연산결과를 더하는 방식으로 이루어진다. 편향은 이때 하나만 존재한다.
Padding

Convolution layer를 거치면 출력데이터의 크기가 줄어드는데, 이는 깊은 신경망을 구성하는 것에 어려움을 줄 수 있다. Padding은 입력데이터 외부에 특정값을 채우는 것으로 출력크기 조정목적으로 주로 사용된다.
Stride
Stride는 필터를 적용하는 위치의 간격으로, stride가 커지면 출력이 작아진다.

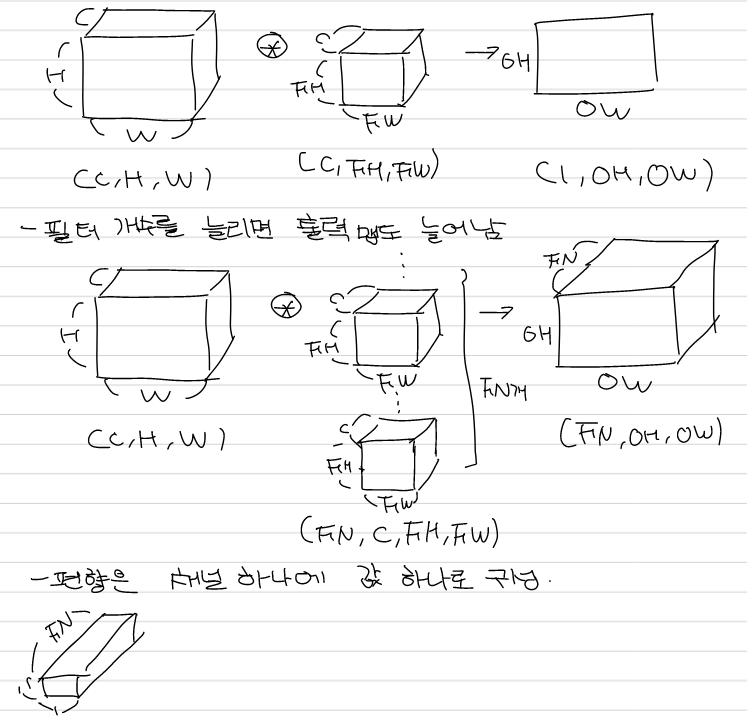
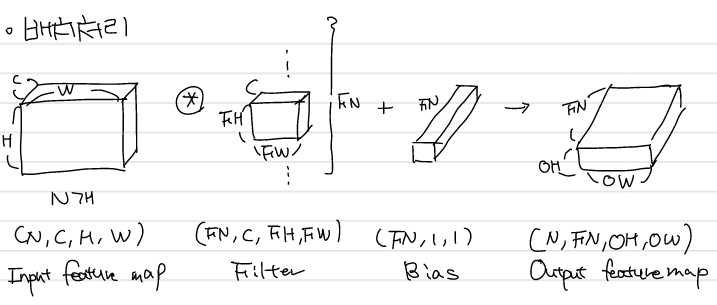
Padding과 stride, 필터의 크기를 고려한 입출력 크기의 관계는 위와 같다. 이 때 출력 크기가 정수가 아니라면 추가적으로 처리를 해주어야한다. 또한 3차원 합성곱은 channel 차원이 추가된 형태로 입력과 필터의 채널이 일치해야한다.
이를 블록 형태로 이해하면 아래와 같다.
Pooling
Pooling은 가로, 세로 방향의 공간을 줄이는 연산으로, 주로 max pooling이 사용된다.
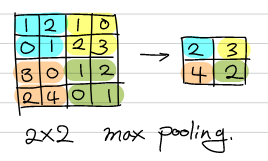
Pooling의 특징은 학습할 매개변수가 없으며, 채널 수에 변화가 없고, 입력변화에 강인한 특성을 보인다는 점이다.
im2col
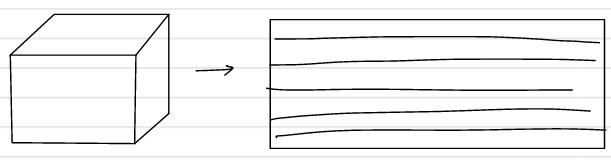
image to column이라는 뜻으로 입력하기 좋게하는 방식이다. 메모리 소비가 증가하지만, for 문을 중첩하는 것과 비교하였을 때 속도가 개선된다.
CNN의 결과

CNN을 적용했을 때 계층이 깊어질 수록 추출되는 정보는 추상화되는 특징을 가지고 있다.
대표적인 CNN
LeNet(1998): sigmoid를 활성화함수, 서브 샘플링 과정.
AlexNet(2012): ReLU, LRN(국소적 정규화). 출력계층이 fully connected layer
GPU와 빅데이터 처리의 발전에서 차이가 있으며, 내용은 크게 바뀌지는 않았다.
Chapter 8 Deep learning
Data augmentation
입력 이미지를 알고리즘을 이용해 회전, 이동, crop, flip, 밝기 조정 등을 수행하는 것으로, 데이터가 적은 상황에서 학습할 경우 효과적이다.
층을 깊게 하는 이유
학습의 효율성 측면에서 바라볼 때, CNN에서 필터를 사용해서 보게되는 영역은 필터를 두번 적용했을 때와 같은 영역이지만, 필터를 두 번 사용하는 경우가 연산양이 더 적어 매개변수 수가 더 줄었지만 넓은 수용 영역(receptive field)를 소화할 수 있다. 또한 비선형 활성화함수를 거치면서 표현력 또한 개선될 수 있다.
VGG
필터를 연속 적용하고, pooling. 출력층을 fully connected layer를 사용하는 방식으로 구현이 간단하다.
GoogLeNet
가로 방향 폭도 깊게하는 인셉션 구조로, 매개 변수 제거와 고속처리에 유리하다.
ResNet(Residual Network)
skip connection을 도입해 역전파시 신호 감쇠를 어느정도 상쇄한다.
transfer learning
전이학습은 이전에 학습된 가중치를 이용해 재학습을 하는 것으로 fine tuning 등의 목적으로 사용된다.
분산 학습
1회 학습시간 단축하고자 다수의 GPU와 컴퓨터를 이용하는 방식으로 통신, 데이터 동기화 등의 문제를 잘 처리해야한다.
소수 표현
32비트, 64비트로 소수를 표현하고 있는데, 16비트의 반정밀도도 학습에는 문제가 없다고 알려져 있으며 연산 고속화 위해 비트 줄이는 연구가 수행되고 있다. 이는 임베디드 시스템에서는 특히 적용될 가능성이 높다.
