2022.04.25
밑바닥부터 시작하는 딥러닝
 https://book.naver.com/bookdb/book_detail.nhn?bid=11492334
https://book.naver.com/bookdb/book_detail.nhn?bid=11492334
Chapter 2. Perceptron
Frank Rosenblatt(1957). 다수의 신호를 입력 받아 하나의 신호를 출력함.
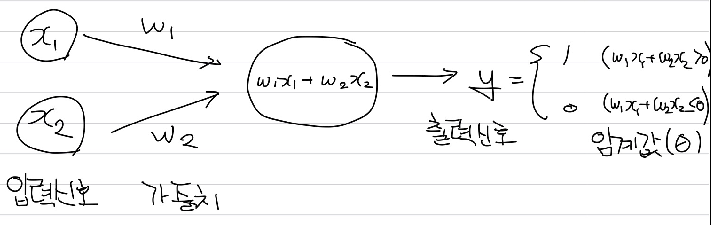
입력신호에 가중치를 곱한 값이 임계값보다 큰 경우 출력 신호를 1로, 그렇지 않은 경우에는 출력 신호가 0이 된다. 여기에 사용된 임계값 를 , bias로 해석할 수 있으며, 편향을 명시한 퍼셉트론은 아래와 같이 나타낼 수 있다.
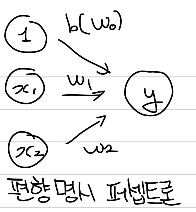
이 때 bias는 weight와는 차이가 있는데, bias가 뉴런이 얼마나 쉽게 활성화되는지 결정한다면, weight는 입력신호가 결과 신호에 주는 영향력을 결정한다.
Perceptron을 이용해서 AND, NAND, OR 등의 게이트를 구현할 수 있으며, 파이썬 코드는 아래와 같다.
def AND(x1, x2):
x = np.array([1, x1, x2])
w = np.array([-1, 1, 1])
tmp = np.sum(x*w)
if tmp > 0 : return 1
else: return 0
def NAND(x1, x2):
x = np.array([1, x1, x2])
w = np.array([1.5,-1,-1])
tmp = np.sum(x*w)
if tmp > 0 : return 1
else: return 0
def OR(x1, x2):
x = np.array([1, x1, x2])
w = np.array([0,1,1])
tmp = np.sum(x*w)
if tmp > 0 : return 1
else: return 0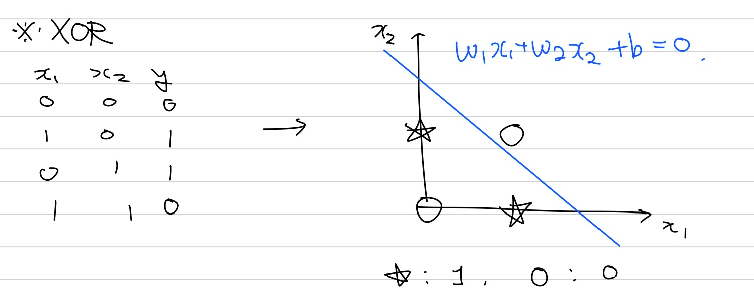
단순한 형태의 perceptron을 사용하는 경우 공간에서 직선으로 표현될 수 있다. XOR 게이트를 단순한 perceptron으로 구현하기 위해서는 하나의 직선으로 구별될 수 있어야하는데 이는 불가능하다.
이를 보완하기 위해서 여러개의 층을 쌓는 다층 퍼셉트론을 사용할 수 있다.
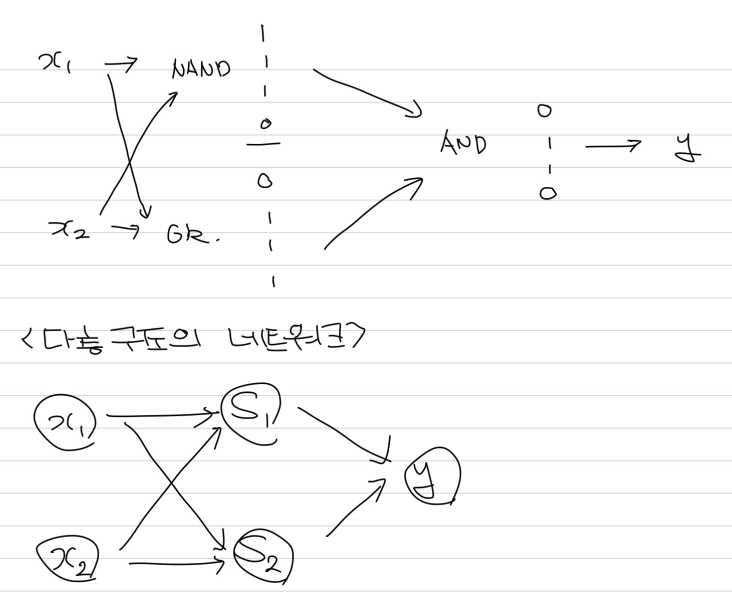
NAND 게이트와 OR 게이트를 지난 결과를 이용해 AND 게이트에 넣어주게 되면 XOR 게이트를 구현할 수 있다.
def XOR(x1, x2):
s1 = NAND(x1,x2)
s2 = OR(x1,x2)
return AND(s1, s2)여기서 얻을 수 있는 아이디어는 단층으로 표현하지 못한 것을 층을 늘려 구현할 수 있다는 것이다.
이론적으로 2층 퍼셉트론과 시그모이드 활성함수로 임의의 함수 구현이 가능하며, NAND만으로 컴퓨터와 같은 복잡한 시스템을 만들 수 있다고 한다.
Chapter 3. Neural Network
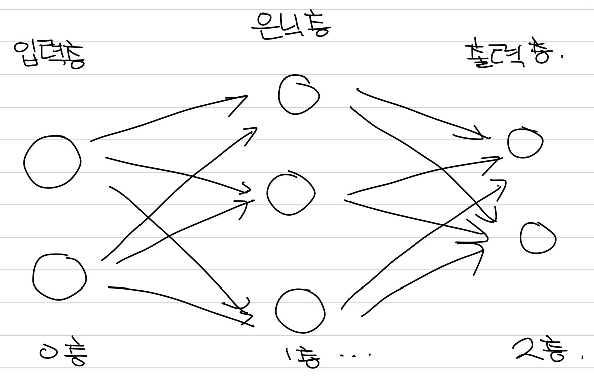
Perceptron과 neural network의 비교에서, 층을 쌓는 아이디어는 그대로 유지되며, 이 둘의 차이는 활성화 함수(Activation function) 으로 볼 수 있다.
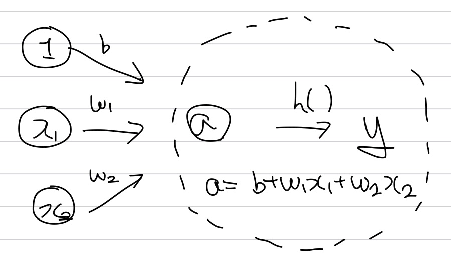
Bias와 weight, 입력값의 곱을 더해 만들어진 a라는 값을 출력 신호로 바꾸어주는 함수를 활성화 함수라고 한다. Perceptron이 0과 1의 출력을 가지는 step function을 활성화 함수로 사용한 형태라면, neural network에서 출력은 이외의 값을 출력할 수 있도록 다른 활성화 함수를 사용한다. 대표적으로는 sigmoid, ReLU(Rectified Linear Unit)이 있다.
전통적으로는 sigmoid가 신경망의 활성화 함수로 사용되었으나, 근래에는 ReLU 함수가 주로 활성화함수로 사용된다. (Vanishing Gradient)


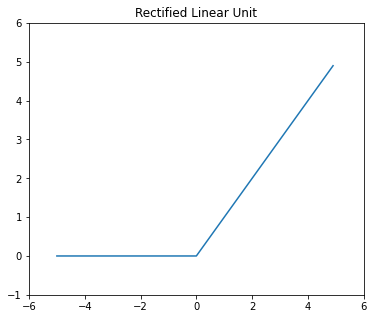

중요한 점은 신경망에서 활성화 함수로 비선형함수를 사용해야한다는 것이다. 선형 함수를 사용하면 신경망층을 깊게 하는 것의 의미가 없기 때문이다. 위의 식은 그 예시인데, 입출력이 하나만 있는 간단한 경우에서 활성화 함수로 선형함수를 사용하는 경우 3층으로 구성한 네트워크가 1층 네트워크와 동일한 결과를 낸다는 것을 확인할 수 있다.
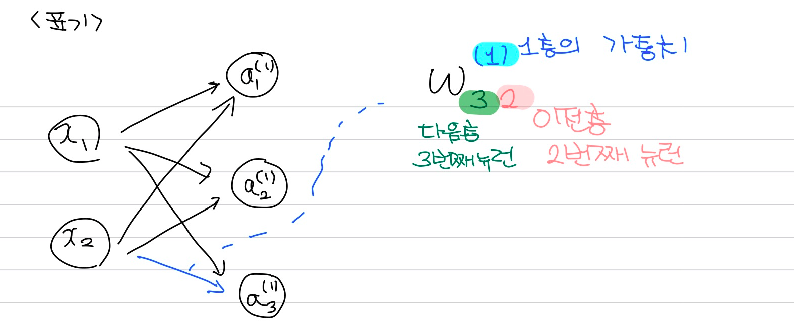
신경망에서 가중치의 표현을 위해서는 위와 같이 표기한다. 윗첨자에는 층을, 아래첨자 앞 숫자는 다음층의 뉴런 번호를, 뒤 숫자는 이전층의 뉴런을 나타낸다.
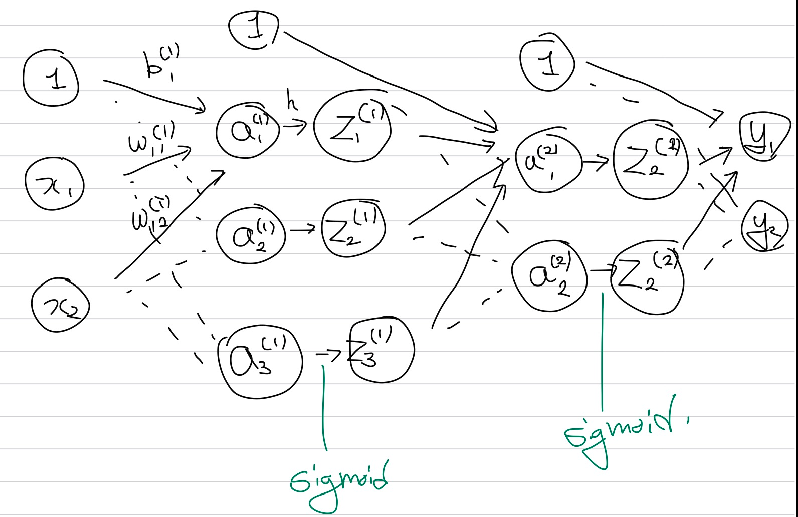
구체적으로는 위와 같은 방식으로 신경망이 구성될 수 있다.
기계학습은 크게 두가지 문제, 회귀와 분류 문제를 다루는데 각각의 함수는 최종 출력을 나타낼 때 회귀는 주로 Identity를, 분류는 softmax를 사용한다.

Softmax 함수를 사용하는 경우 overflow가 일어날 가능성이 높은데, 적절한 수를 차감하여 오버플로우 문제를 해결할 수 있다. Softmax 함수의 특징으로는 출력값이 0~1 사이에 위치하며, 모든 값의 합이 1이므로 확률로서 해석이 가능하다. 또한 대소관계가 함수의 입력값과 출력값에서 동일하다는 특징을 가지고 있다.
분류 문제의 train 과정에서는 softmax를 사용하지만, inference 과정에서는 계산 양을 줄이기 위해 생략하는 경우가 일반적이다. 분류 문제에서 출력층의 뉴런 수는 분류 클래스의 수와 동일하므로 이를 염두하여 출력층을 설계해야 한다.
신경망 학습에서는 입력 데이터에 특정 변환을 가하는 전처리(Pre-Processing) 과정을 일반적으로 수행하며, 전체 평균과 표준편차를 이용해 평균을 0으로 분포하게 하거나, 데이터 확산 범위 제한 등의 정규화 과정이나, 균일하게 분포(Whitening)하게 하는 작업 등을 수행한다.
Batch는 하나로 묶은 입력 데이터를 가르키는 말이다. 이는 컴퓨터 처리 시 이점을 가지고 있는데, 먼저 대부분의 수치계산 라이브러리가 큰 배열을 효율적 처리가 가능하게 최적화되어 있기 때문이다. 두 번째로 하나씩 데이터를 읽어 처리하는 경우와 비교하였을 때 작업 속도가 느린 I/O 데이터를 읽는 횟수에 비해 빠른 CPU/GPU 순수 계산 수행 비율이 증가하기 때문이다.
