2022.04.28
밑바닥부터 시작하는 딥러닝

https://book.naver.com/bookdb/book_detail.nhn?bid=11492334
Chapter 4 신경망 학습
학습 : 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것. 학습의 지표로는 손실함수를 사용한다.
※ Perceptron convergence theorem: 선형 분리 가능한 문제는 유한번의 학습을 통해 해결할 수 있다.
※ Chapter 2에서 AND, NAND 등을 만들기 위해 수작업으로 매개변수를 설정했으나, 실제 신경망에서는 매개변수가 매우 많아 불가능하다.
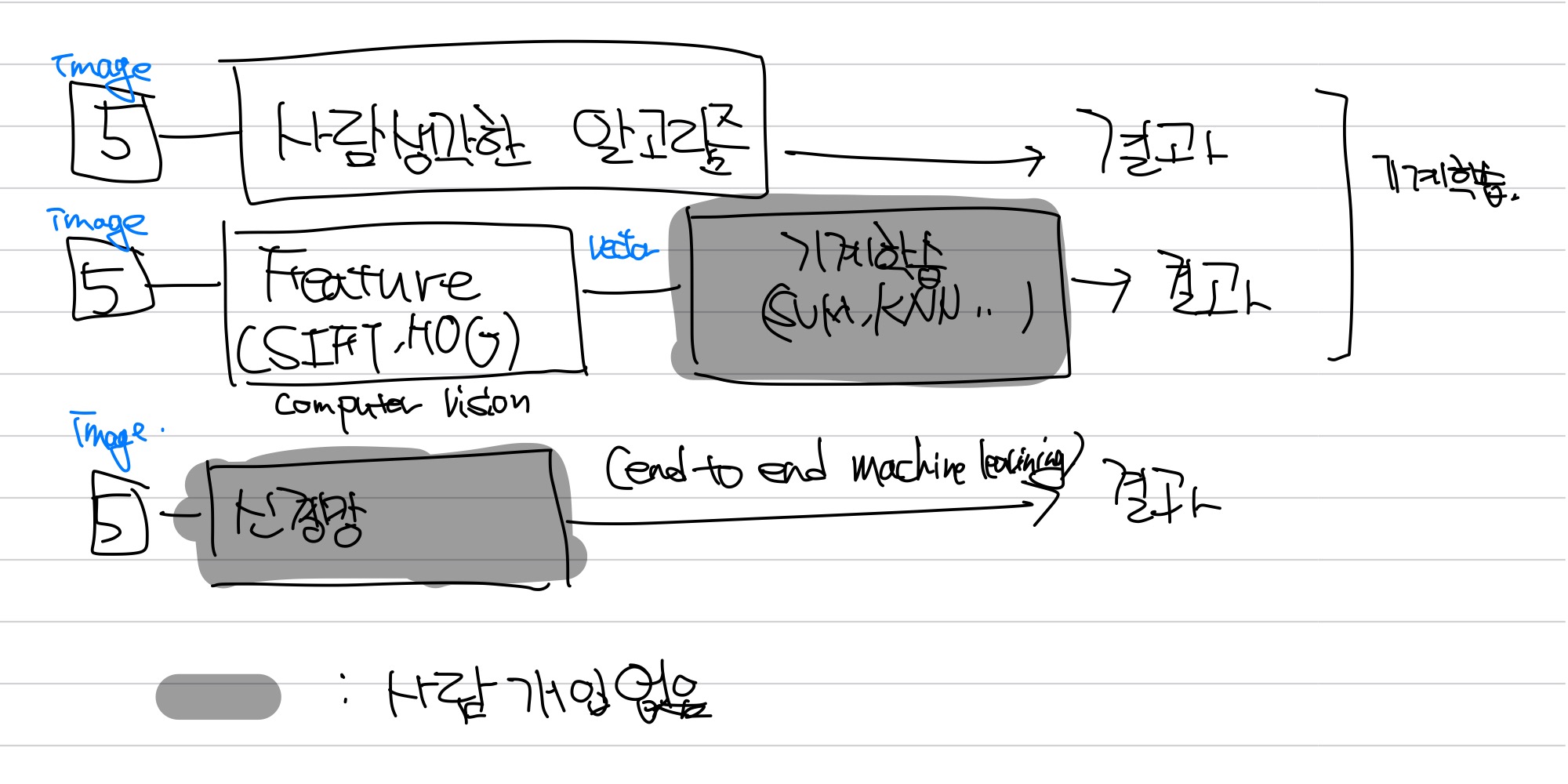
기계학습은 사람의 개입 방식에 따라 위와 같이 나눌 수 있다.
- Image에서 사람이 직접 알고리즘을 고안해 하는 방식
- Computer Vision에서 SIFT, SURF, HOG 등의 알고리즘을 이용해 특징을 추출하고 SVM, KNN 등으로 기계학습을 하는 방식
- 신경망을 이용하는 방식
2번째 방식은 학습 속도는 빠를 수 있는 장점이 있지만 특징 추출에 사람의 아이디어가 필요하며, 부정확할 수 있다.
신경망을 이용하는 방식은 end to end machine learning이라고도 한다.
데이터의 종류
- Training data
매개변수 학습에 사용되는 데이터 - Validation data
하이퍼 파라미터 성능 평가에 사용되는 데이터 - Test data
신경망의 범용 성능을 평가하는 데이터
손실함수
신경망의 성능을 평가하는 지표로, ‘나쁨’의 정도를 평가한다. 손실함수의 최적화는 손실함수의 극소점을 찾는 과정이다.
※ 성능을 평가하기 위해 사용할 수 있는 지표 중 정확도(Accuracy)도 존재한다. 하지만 정확도는 매개변수의 미분이 대부분의 장소에서 0이 되므로 가중치 개선에 어려움이 있다. 정확도는 매개변수의 미세한 변화에 반응이 적으며 불연속적 변화한다. 신경망에서 step function 대신 ReLU, sigmoid 등의 활성화함수를 사용하는 이유도 이와 같은 맥락에서 볼 수 있다.
MSE(Mean Square Error)

가장 많이 사용되는 손실함수로 신경망 출력과 정답 레이블의 차이를 제곱하여 얻을 수 있다.
CEE(Cross Entropy Error)

자주 사용되는 손실함수로 분류 문제일 경우 실질적으로는 정답 레이블의 값으로 볼 수 있다.
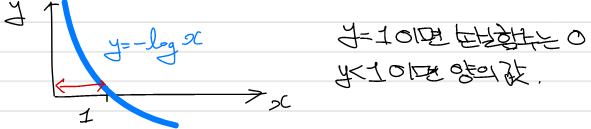
분류 문제로 보았을 때, 확률이 높을수록 0에 가까워지며 낮을수록 1에 가까워짐을 알 수 있다.
Mini-batch
훈련데이터에 대한 손실함수를 구하고, 그 값을 줄이는 과정이 학습이다. 모든 데이터에 대해서 손실함수를 구하고 가중치를 갱신하기에는 훈련 데이터의 크기가 크고 손실함수 계산에 시간이 많이 필요하게 된다. 이를 개선 하기 위해 훈련 데이터 중 일부를 추린 mini-batch를 전체의 근사치로 보고, 가중치를 mini-batch 단위로 갱신하게 된다.
Gradient
Gradient(기울기)는 모든 변수에 대한 편미분한 것으로 하나의 출력을 가지는 함수를 미분하는 경우 벡터로 주어진다. Gradient의 방향은 함수가 지역적으로 가장 크게 증가하는 방향이며, 크기는 함수가 지역적으로 변하는 크기를 나타낸다.

또한 gradient는 isovalue line과 직교하는 성질을 가지고 있다.

Gradient의 방향이 지역적으로 가장 크게 증가하는 방향이므로, 손실함수의 -gradient 방향으로 weight 값을 갱신한다면 손실함수가 줄어드는 것을 기대할 수 있다. 모든 점에서 gradient가 가르키는 방향이 global minimum을 가르키는 것은 아니며, gradient가 0인 지점에서는 갱신이 중단될 수 있다.(극소, 극대, 안장점)
Gradient descent method

위의 아이디어를 구체화한것이 gradient descent method(경사하강법)이며 learning rate로는 0.001, 0.01 등의 값을 사용한다. 학습률이 너무 작으면 학습속도가 지나치게 느려지며, 학습률이 크면 발산 가능성이 있다.
※ 이전의 가중치, 편향은 학습을 통해 획득되는 매개변수였다. 학습률은 사람이 직접 설정하는 매개변수로, 이러한 매개변수들은 hyperparameter이라고 부른다.
Stochastic gradient descent(SGD)
확률적으로 무작위로 선정된 mini-batch에 대해 Gradient descent method를 수행하는 것을 SGD라고 한다.
※ epoch: 학습에서 소진한 훈련데이터 횟수
Chapter 5. Backpropagation
손실함수의 미분값을 이용하기 위해서, 가장 먼저 수치 미분을 떠올릴 수 있지만 계산시간이 오래 걸린다는 단점이 있다. Backpropagation을 사용하는 경우 미분값 계산에 걸리는 시간을 단축할 수 있다.
Computational graph(계산그래프)
계산 그래프는 계산 과정을 시각적으로 파악하기에 유리하며, 연쇄 법칙에 기반한 backpropagation을 시각적으로 쉽게 확인할 수 있다.
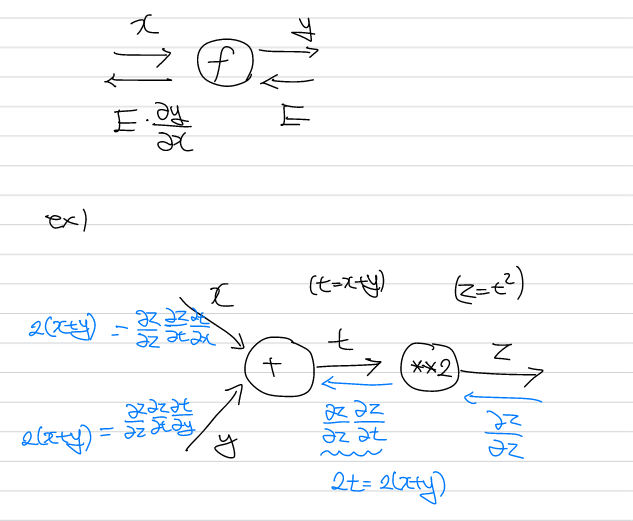
계산 방향으로 값을 구하는 것을 순전파(forward propagation), 역으로 가면서 미분값을 구하는 것을 역전파(backpropagation)이라고 한다. n+1층에서 n층으로 미분 값을 구하는 경우 이전의 값에 현재의 미분값을 곱하는 형태로 표현된다.

덧셈 노드의 역전파는 입력값을 그대로 흘려보내며, 곱셈 노드의 역전파는 서로 바꾼 값을 보낸다. 이전의 신경망 구조는 덧셈과 곱셈으로만 이루어진 선형 결합 형태였으므로, 이것만으로 해당 계층을 표현할 수 있다.
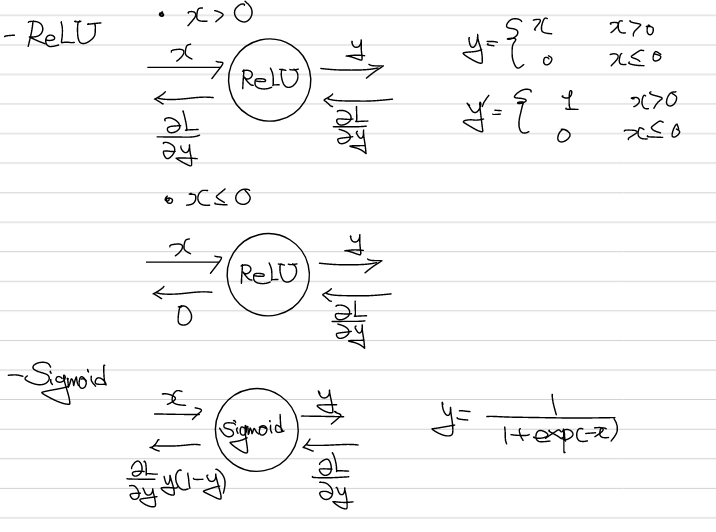
활성화 함수의 역전파 또한 위와 같이 나타낼 수 있다.
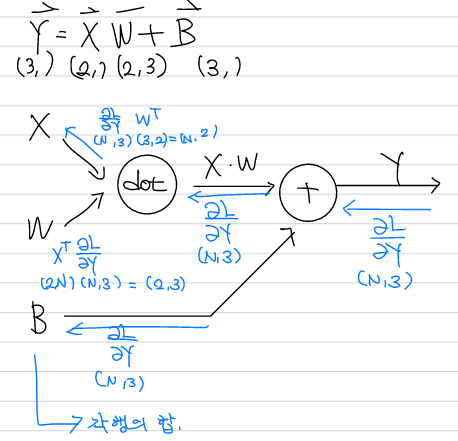
신경망의 순전파 시 수행되는 행렬의 내적은 기하학의 affine transform으로 볼 수 있으며, 신경망 계층에서 역전파는 위와 같은 방식으로 수행된다.
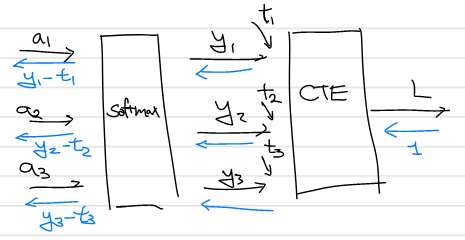
Softmax 함수를 거친 값을 loss function으로 CEE를 사용하는 경우 역전파는 신경망의 출력에서 레이블 값의 차이로 주어진다.
