
AIFFEL에서 공부한 list와 dictionary를 정리해보자.
다차원 리스트
1차원 리스트
a = [1,2,3,4,5]
print(a)1차원은 행 (column) 으로 만 구성
2차원 리스트
b = [[1,2], [3,4], [5,6]]
print(b)2차원은 행과 열 (row) 로 구성
Q) 1차원이 아닌 리스트의 len을 어떻게 출력될까?
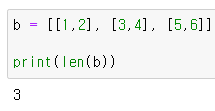
A) 무조건, 행이 출력된다.
Q) 열을 출력하는 방법은?

A) slicing 과 indexing 을 활용하여 row list로 가공한다.
3차원 리스트
3차원은 깊이 (depth), 행, 열 로 구성
c = [[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]],\
[['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i'], ['j', 'k', 'l']]]
print(c)동일하게 len으로 하면 반환값은 depth
+) 다차원 리스트의 크기를 쉽게 알아보는 법
c = [[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]],\
[['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i'], ['j', 'k', 'l']]]만약, 이런 list가 있다고 생각하고 차원의 크기를 생각해보자
-
중괄호의 개수는 차원의 개수를 의미한다.
→ 중괄호 3개 = 3차원 -
가장 안에 있는 중괄호 내부가 마지막 차원 즉, row의 차원의 크기를 의미
→ 총 3개 element -
row 중괄호 개수를 확인하면, 그것이 column의 차원의 크기를 의미
→ [1 , [4 , [7 , [10 으로 총 4개 element -
column 중괄호 개수를 확인하면, 그것이 depth 차원의 크기를 의미
→ [[1 , [['a' 으로 총 2개 element
최종적으로, | c | = { 2, 4, 3 } 의 차원의 크기를 가짐
리스트 함수 (추가)
1. min(), max()
리스트에서 각각 최대값과 최소값을 구하는 함수
리스트의 문자형과 숫자형이 혼합되지 않는다면, 둘 다 올바르게 출력됨

문자열에 경우, 아스키 코드로 비교해서 min과 max 출력
+) 아스키 코드 (American Standard Code for Information Intercharge)
미국 정보 교환 표준 코드
컴퓨터는 문자를 모르기 때문에 임의로 정한 숫자로 문자를 대체
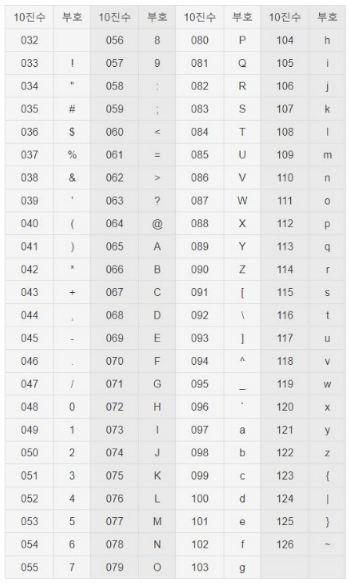
chr() : ASCII → 문자열
ord() : 문자열 → ASCII
2. sum()
리스트나 튜플의 숫자형 자료형들을 모두 더한다.
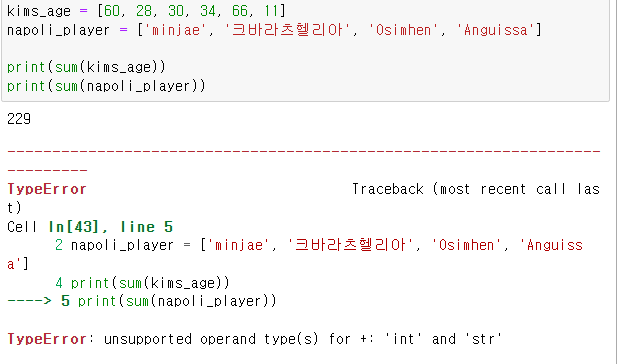 문자형은 불가능하다.
문자형은 불가능하다.
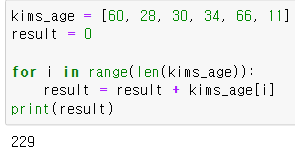 반복문으로 구현한 형태는 이러하다.
반복문으로 구현한 형태는 이러하다.
3. enumerate()
리스트의 원소에 순서값을 부여하고 묶어서 tuple로 반환

for문과 자주 사용된다.

어떤 element가 list를 구성하고 있던지 문제없다.
4. zip()
argument로 iterable 객체를 받고, 각 객체의 element에 순차적으로 접근할 iterator 반환
+) 여기서 나온 iterable과 iterator는 다음 장에서 설명할 예정이니, 여기선 함수만 보자

두 개의 리스트를 같은 index의 element끼리 묶어서 tuple로 반환

만약 두 개의 리스트의 길이가 같지 않다면, 짧은 리스트에 맞춰 실행
긴 리스트의 남은 부분은 그냥 사용되지 않음
딕셔너리 함수
1. setdefault() , update()
key와 value 추가하기
setdefault()
- key가 있다면, 그 키 값을 반환
- key가 없다면, 새로 value 값을 저장하고 저장한 value 값 반환
# 대괄호는 생략가능한 부분
dictionary명.setdefault( key값 , [집어넣을 value값] )
update()
- key가 있다면, 값을 변경
- key가 없다면, 값을 추가
dictionary명.update( key값 = value값 )
추가적으로, key값은 문자열이지만 ( 물론 숫자형도 가능하지만 문자열이 편함 ) update 사용 시에는 따옴표를 땐다.
2. pop() , popitem()
- pop()
입력한 key값을 통해 key와 value를 제거하고 value만 반환
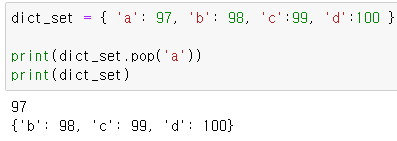
리스트와 다르게 dictionary는 pop 에서도 key값 입력 필요
- popitem()
key값 입력할 필요없이 마지막 key와 value 제거, value만 반환
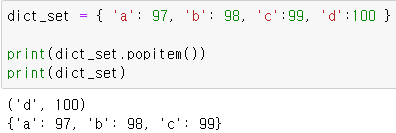
3. fromkeys()
리스트나 튜플을 argument로 입력하면, 자동으로 딕셔너리 생성
딕셔너리명.fromkeys( 리스트 or 튜플 [ , value값] )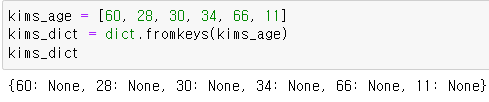
value값 생략 시, value가 모두 'None'으로 대입

value값은 중복이 되어도 상관없기 때문에, 동일한 값으로 한번에 처리
4. in / not in
element가 안에 포함되어 있는지 확인 후, bool값으로 반환
문자열에서도 문자가 안에 포함되어 있는지 확인 가능
python basic(2)에서 정리하였으니 생략
Comprehension
iterable한 객체를 생성할 수 있는 방법 중 하나
반복문을 이용한 리스트, 튜플, 딕셔너리 생성법보다 간단하게 생성 가능
1. List Comprehension (LC)
1) 반복문
# 이때 반복문에는 element 변수로 iterable한 객체 읽기
[ (element 변수) for 반복문 ]반복문을 통해 먼저 리스트를 구현해보면,

이걸 list comprehension으로 구현하면 간단하게 구현 가능하다.
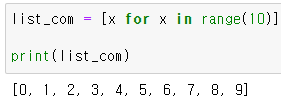
이 형태가 제일 간단한 구조이고 추가 가능
2) 반복문 + 조건문
[ (element 변수) for 반복문 if 조건문 ]동일하게 반복문 우선 구현

Comprehension 구현

3) 중복 표현
# 반복문 중복
[ (element 변수) for 반복문 for 반복문 ]
# if 문 중복
[ (element 변수) if 조건문 if 조건문 ]먼저, 중복 반복문
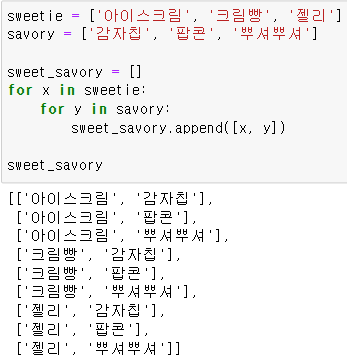
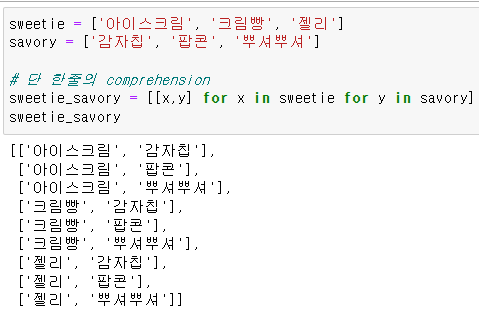
중복 if 문


2. Set Comprehension (SC)
그냥 list에서 대괄호가 중괄호로 바뀐 것으로 생각하면 된다.
나머지는 동일
{ (element 변수) for 반복문 }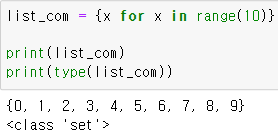
3. Dictionary Comprehension (DC)
두 개의 element 요소를 설정
zip 함수를 이용해서 tuple 형태로 가공해서 element 요소로 반환
# zip은 두 개의 리스트를 같은 index의 element끼리 묶어서 tuple로 반환하는 역할
{ element1 : element2 for element1,element2 in zip() }
zip(napoli_num , napoli_player)의 반환값을 보면
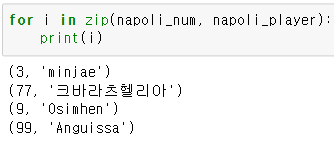
이런 형태를 띈다.
