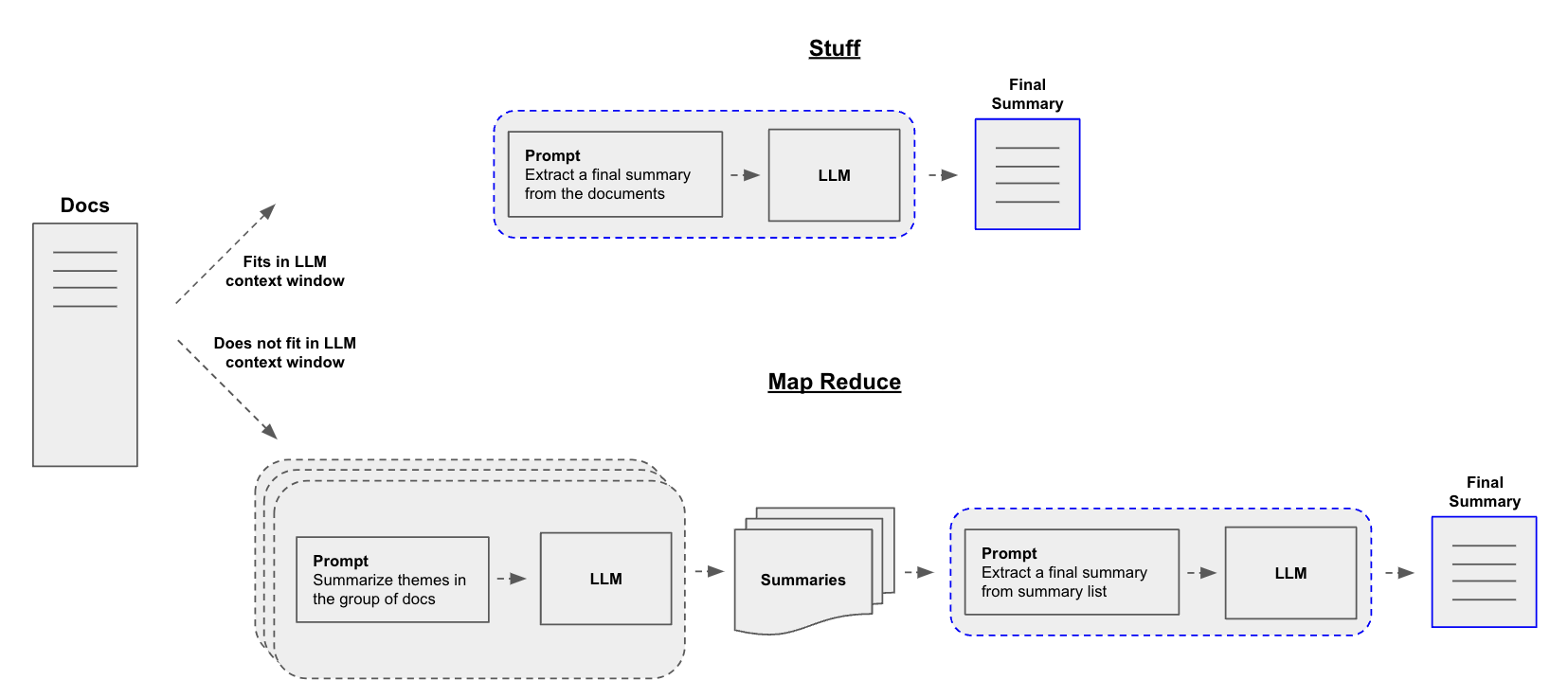
- 요약 2가지 방안
- Stuff: 문서 전체를 그대로 전달
- Map-reduce
MapReduceDocumentsChain 로 문서를 축소하여 그 다음 요약 생성
- 여기서는 map reduce 로 LLM 요청 send 해서 받아오는 구조로 소개하고 있음
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\\n\\n{context}")]
)
chain = create_stuff_documents_chain(llm, prompt)
result = chain.invoke({"context": docs})
print(result)
from langchain import hub
map_prompt = hub.pull("rlm/map-prompt")
- reduce
reduce-prompt 풀링하거나 프롬프트 작성해서 사용
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""
reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
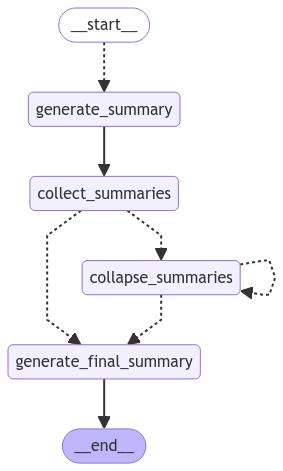
LangGraph 로 요약하기
- document 너무 클 경우 분할하고,
- llm 으로 map, reduce 반복,
- 최종적으로 다시 reduce 하여 최종 summary 생성
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
print(f"Generated {len(split_docs)} documents.")
import operator
from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import (
acollapse_docs,
split_list_of_docs,
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraph
token_max = 1000
def length_function(documents: List[Document]) -> int:
"""Get number of tokens for input contents."""
return sum(llm.get_num_tokens(doc.page_content) for doc in documents)
class OverallState(TypedDict):
contents: List[str]
summaries: Annotated[list, operator.add]
collapsed_summaries: List[Document]
final_summary: str
class SummaryState(TypedDict):
content: str
async def generate_summary(state: SummaryState):
prompt = map_prompt.invoke(state["content"])
response = await llm.ainvoke(prompt)
return {"summaries": [response.content]}
def map_summaries(state: OverallState):
return [
Send("generate_summary", {"content": content}) for content in state["contents"]
]
def collect_summaries(state: OverallState):
return {
"collapsed_summaries": [Document(summary) for summary in state["summaries"]]
}
async def _reduce(input: dict) -> str:
prompt = reduce_prompt.invoke(input)
response = await llm.ainvoke(prompt)
return response.content
async def collapse_summaries(state: OverallState):
doc_lists = split_list_of_docs(
state["collapsed_summaries"], length_function, token_max
)
results = []
for doc_list in doc_lists:
results.append(await acollapse_docs(doc_list, _reduce))
return {"collapsed_summaries": results}
def should_collapse(
state: OverallState,
) -> Literal["collapse_summaries", "generate_final_summary"]:
num_tokens = length_function(state["collapsed_summaries"])
if num_tokens > token_max:
return "collapse_summaries"
else:
return "generate_final_summary"
async def generate_final_summary(state: OverallState):
response = await _reduce(state["collapsed_summaries"])
return {"final_summary": response}
graph = StateGraph(OverallState)
graph.add_node("generate_summary", generate_summary)
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
graph.add_edge("generate_final_summary", END)
app = graph.compile()
reference
