Python / Machine Learning
1.[Python] ConfigParser 를 이용한 config 파싱 예제

configParser 예제
2.[Python] argparse 사용하기
argparse 로 명령행 인자 파싱하기
3.[Python] pip install 중 CERTIFICATE_VERIFY_FAILED error
인트라넷 등 사용시 인증 관련하여 발생하는 문제
4.[Python] requirements.txt 로 의존성 관리하기
requirements.txt 로 의존성 및 버전을 관리
5.[Python] POST 요청으로 이미지 데이터 업로드하기 (multipart/form-data)
* multipart/form-data 형식의 POST 요청 보내기
6.[Python] pipenv 로 패키지 의존성 관리하기
pyenv, pipenv 로 가상환경 사용 및 패키지 의존성 관리하기
7.[ML] Perceptron (with Scikit-learn)
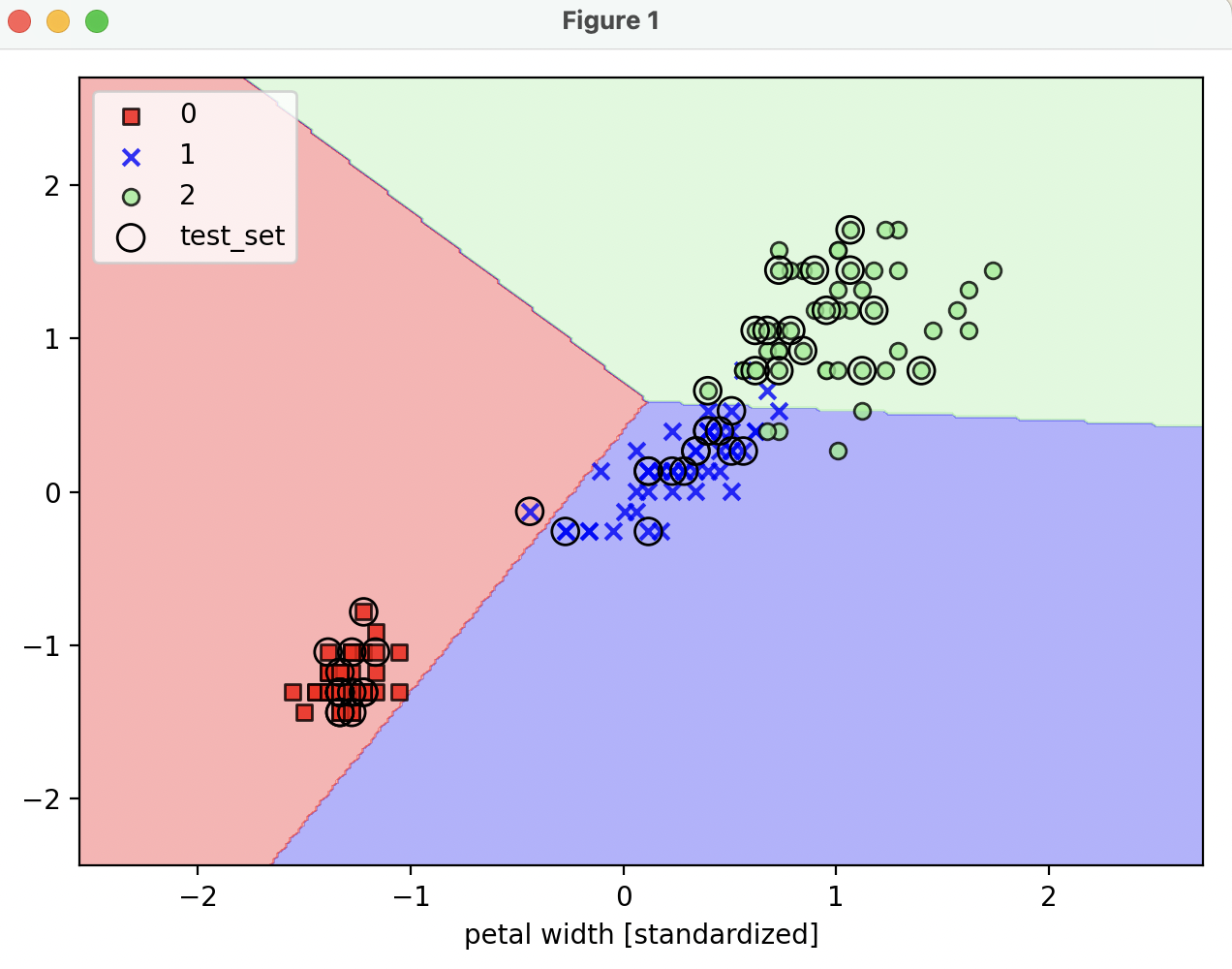
perceptron 선형 분류기 schikit-learn 구현 예제
8.[ML] Logistic regression (로지스틱 회귀)
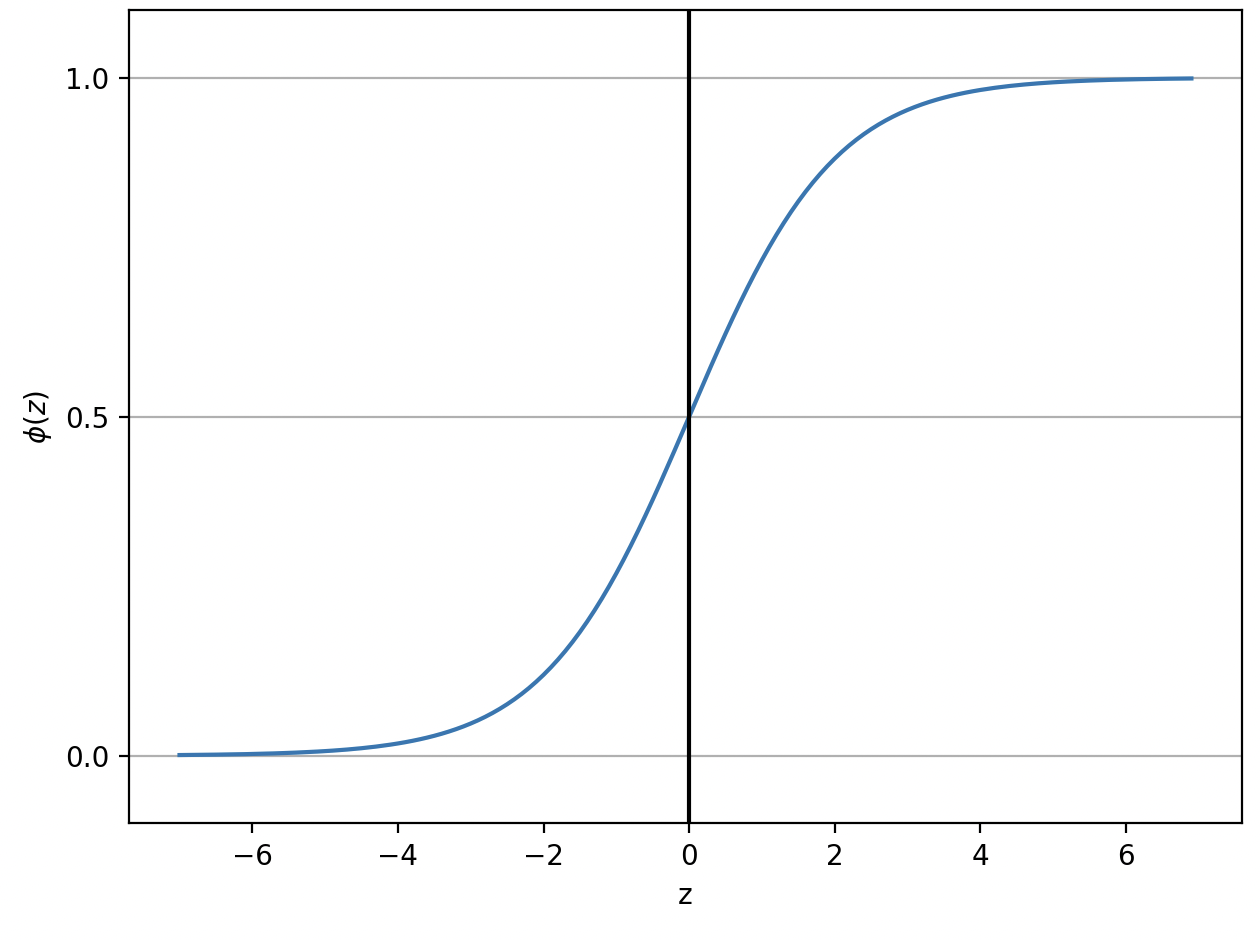
선형 분류기 logistic regression (로지스틱 회귀) 와 sigmoid 함수 개요 및 scikit learn 기반 예제
9.[ML] Support Vector Machine (SVM)
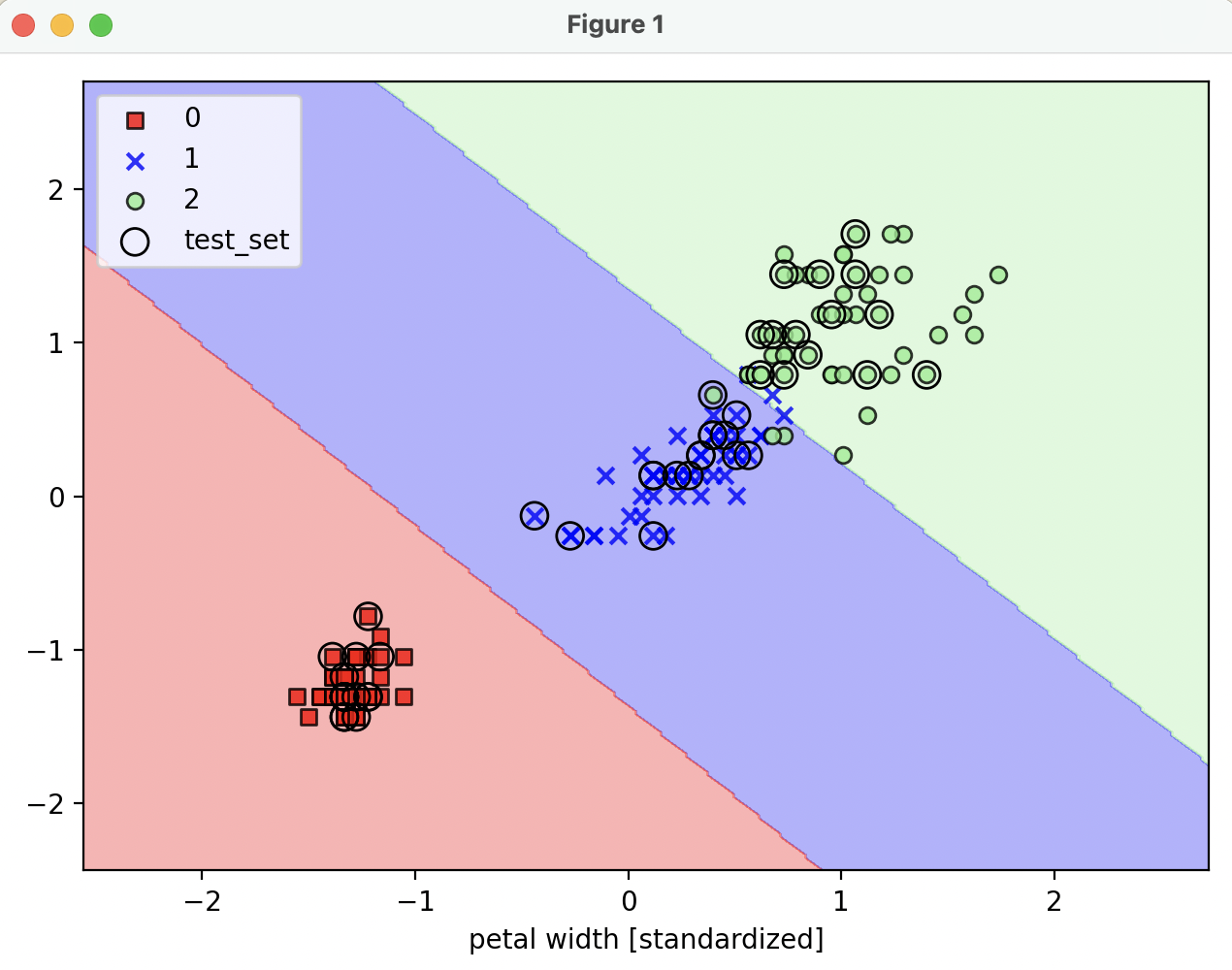
SVM 개요, soft margin SVM, scikit-learn trainning
10.[ML] feature scaling
정규화(normalization),표준화(standardization). min-max scaling, standard scaling, robust scaling, max-abs scaling
11.[ML] regularization 를 통한 모델 복잡도 제한
regularization (규제): 개별 가중치 값을 제한하여 overfitting 방지 L2, L1 regularization : cost function 에 penalty term (패널티 항) 을 추가, 가중치 값을 작게 만드는 효과
12.[ML] dimensionality reduction (차원 축소)
모델 복잡도를 줄이고 overfitting 을 방지하는 방법 중 하나 feature selection : original feature 에서 일부를 선택. feature extraction: original feature 에서 새로운 feature 생성
13.[ML] learning curve, validation curve (학습 곡선, 검증 곡선)
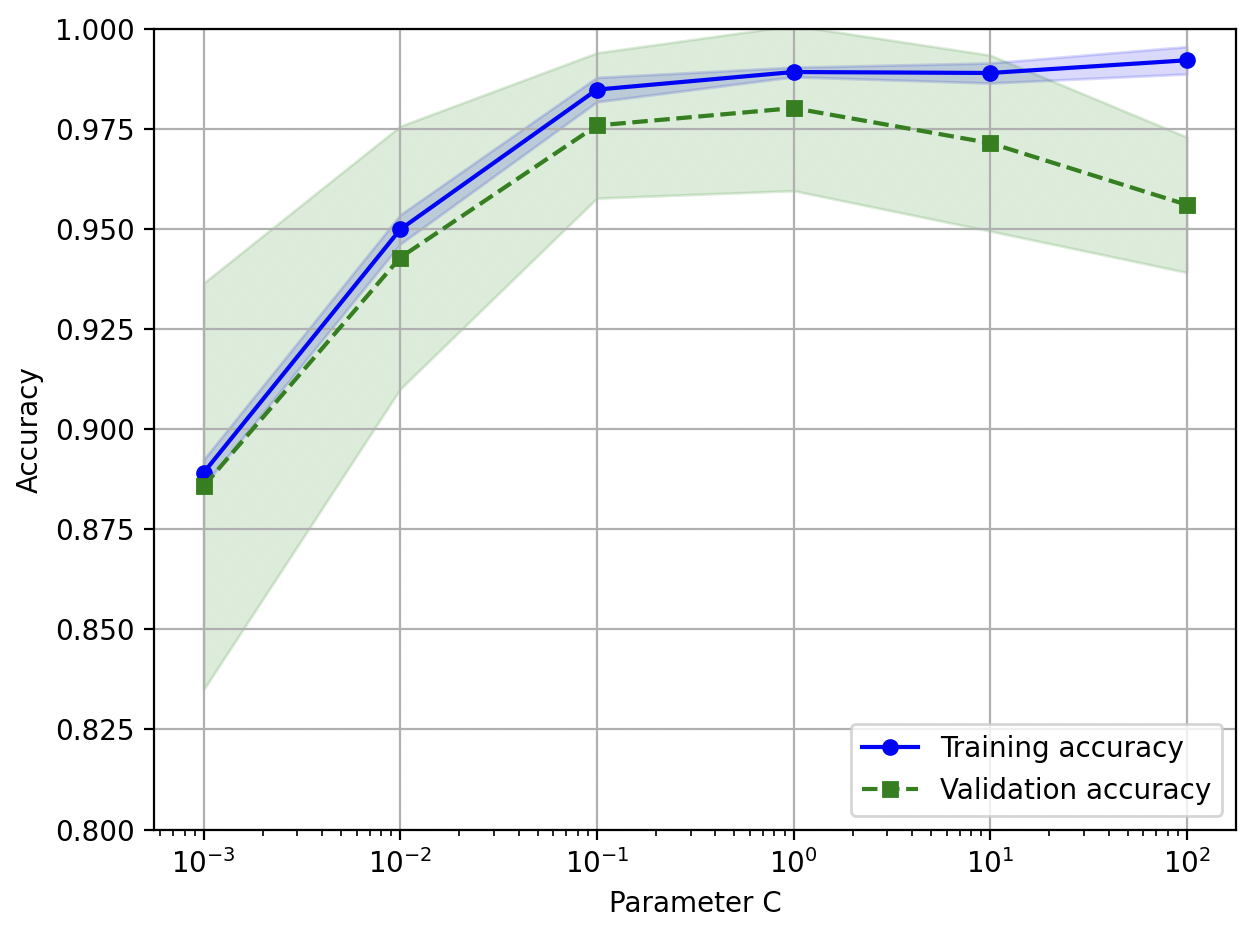
Learning Curve (학습 곡선) * 편향(bias)이 높으면 (=underfitting) 훈련 정확도, 교차 검증 정확도가 모두 낮게 나타남 분산(variance)이 높으면 (=overfitting) 훈련 정확도, 교차 검증 정확도의 차이가 크게 나타남
14. [ML] Greedy search, nested cross-validation
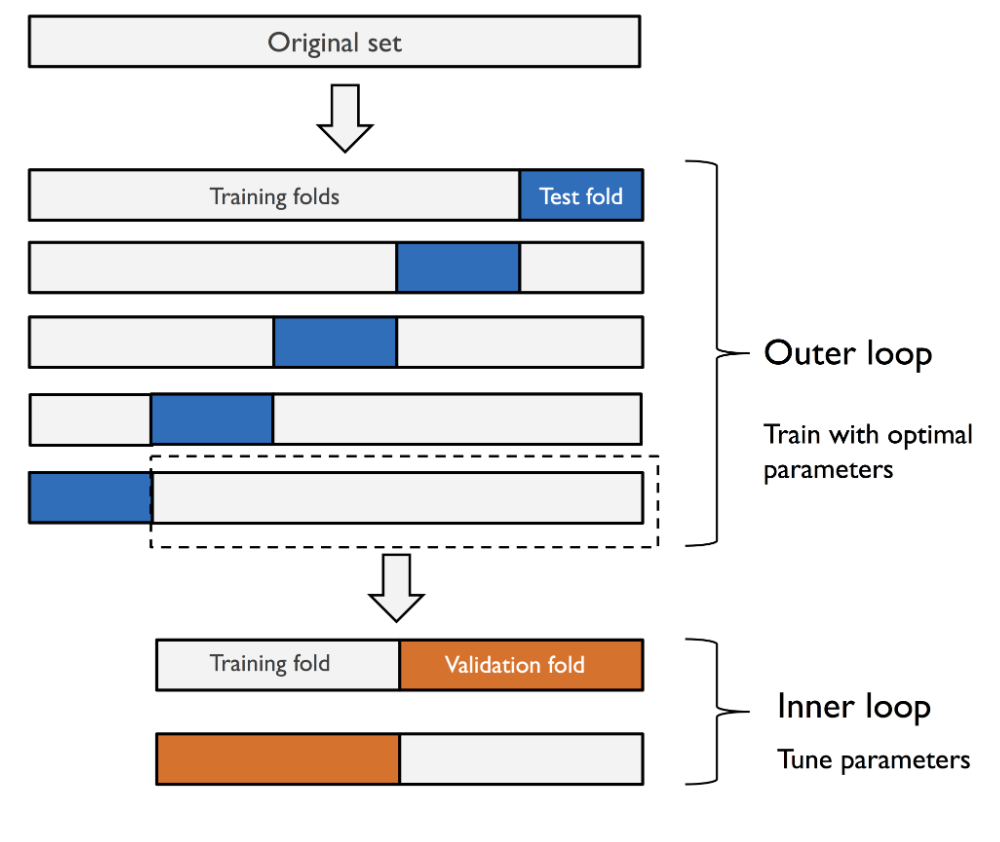
Greedy search : 하이퍼파라미터 (Hyper parameter) 최적화 기법. 하이퍼파라미터 모든 조합에 대해 모델 성능 평가. Nested cross-validation : k-fold cross validation 을 중첩. ML 모델 성능 비교
15.[ML] confusion matrix (오차 행렬), precision, recall
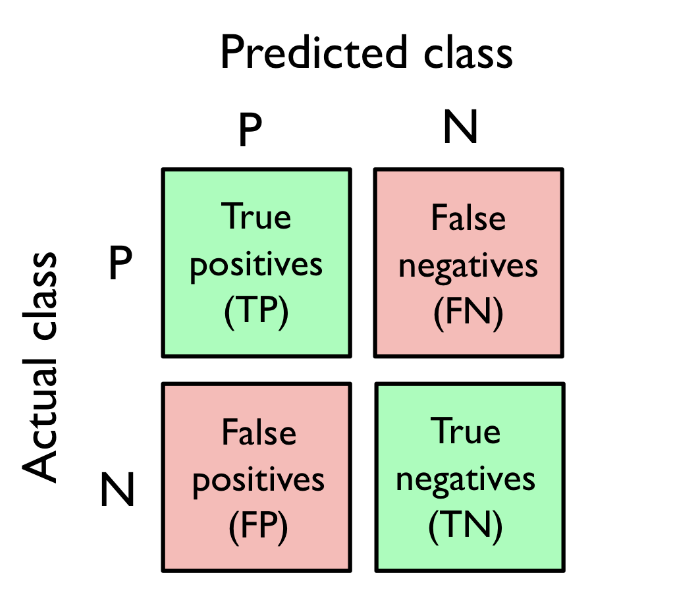
confusion_matrix : True Positive, True Negative, False Positive, False Negative 행렬
16.[ML] 클래스 불균형 해소
데이터셋의 클래스 비율이 불균형할 경우, 소수 클래스의 샘플을 늘리거나, 다수 클래스 샘플을 줄이거나, 인공 훈련 데이터 생성
17.[ML] 문서 분류를 위한 로지스틱 회귀 모델 훈련
GridSearchCV 로 하이퍼파라미터 최적값 찾기, LDA 로 문서 주제(토픽)를 추출하기
18.[ML] 선형 회귀 (linear regression)
1개 이상의 feature 와 연속적인 타깃 변수 사이의 관계를 모델링, 연속적인 output 값을 예측
19.[ML] 탐색적 데이터 분석(EDA) - 선점도 행렬, 상관관계 행렬
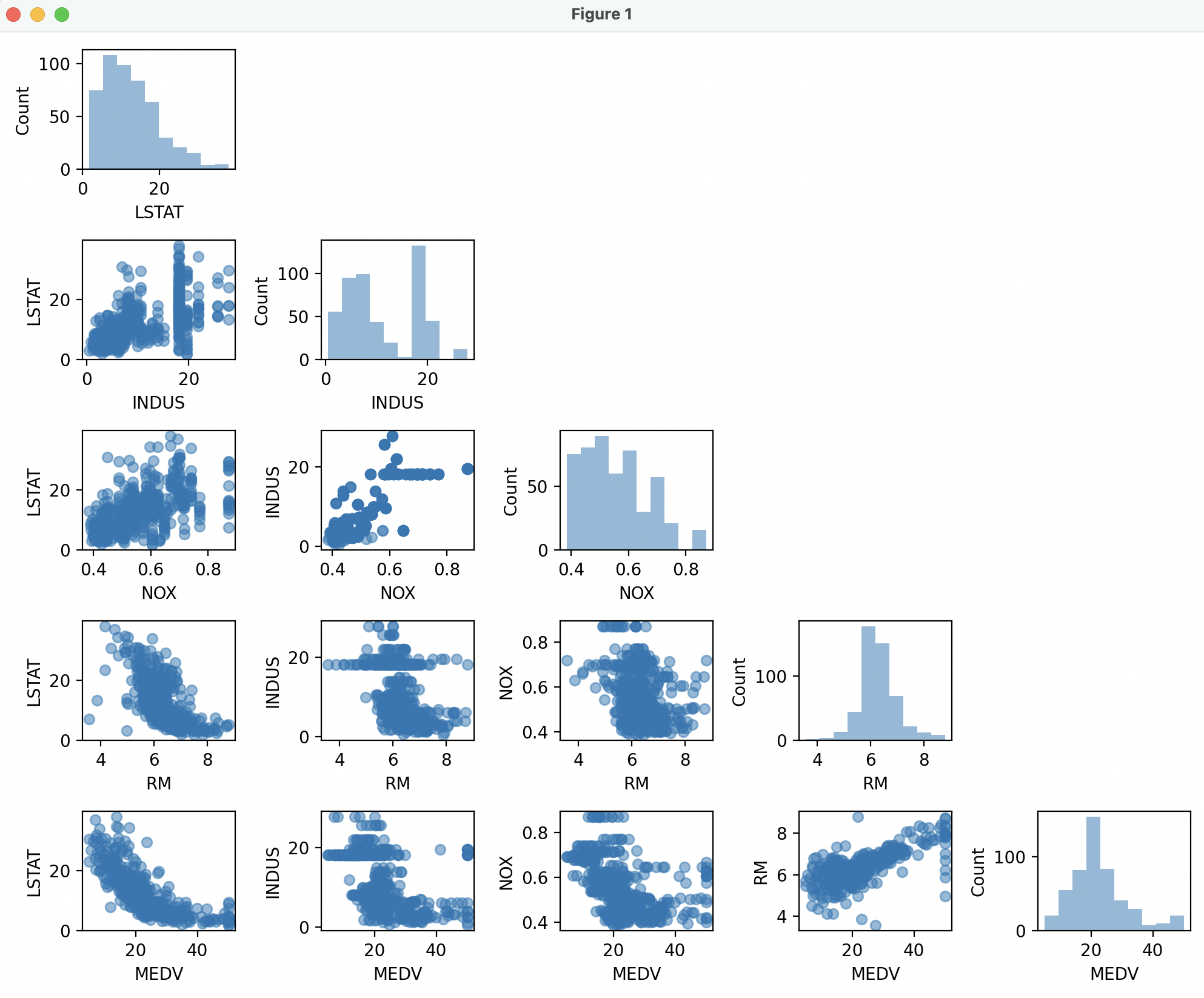
수치 요약과 시각화를 사용하여 데이터를 탐색하고 변수 간 잠재적 관계를 찾아내는 프로세스
20.[ML] 최소 제곱 선형 회귀 모델
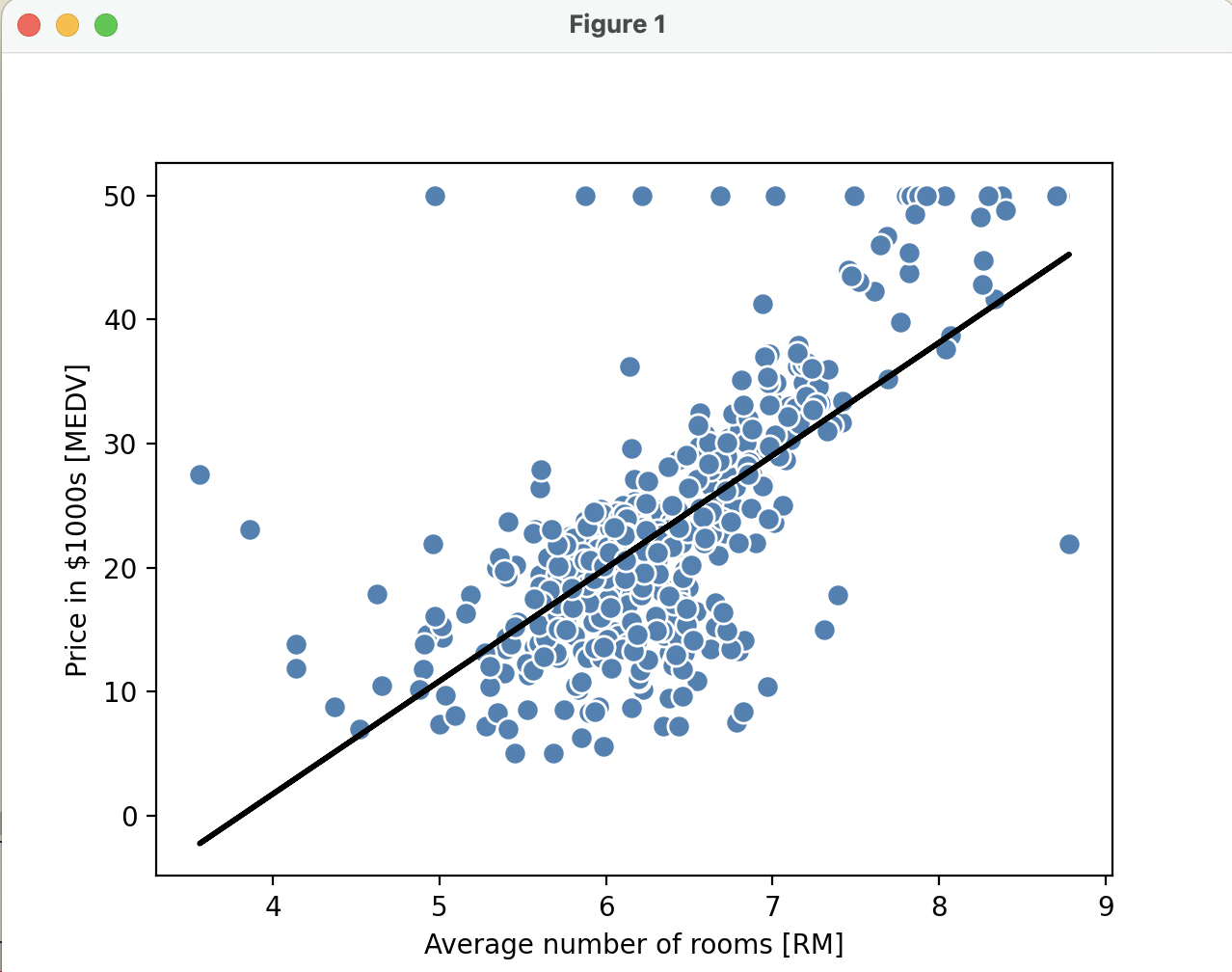
선형 회귀 직선의 모델 파라미터를 추정하는 방법. training sample 까지의 수직 거리 (=offset) 의 제곱합을 최소화. 선형 최소 제곱법 (linear least squares) 라고도 한다.
21.[ML] 모델 배포와 예측 서비스
모델 배포와 예측에 대한 통념, 기법 등
22.[ML] TDD와 BDD 개요, 확률적 속성 문제, ML 성능 평가 지표
TDD 의 규칙, BDD 개요, Randomness 문제, ML 모델의 정량적 평가 지표
23.[LangChain] 정리
rest api 연동은 langserve 로 지원https://python.langchain.com/docs/langserve/fastapi 를 내부적으로 사용.하지만 유지보수 정도만 하는 프로젝트. (langserve platform 을 쓰라고 하고 있으나,
24.[LangChain] RAG
RAGhttps://python.langchain.com/docs/tutorials/rag/document loader 를 통해 Document 타입 객체로 데이터 로딩https://python.langchain.com/docs/concepts/doc
25.[LangChain] Query To SQL
question 으로 SQL Query 하기 question를 query 로 변환 -> query 실행 -> 쿼리 결과를 answer 로 가공
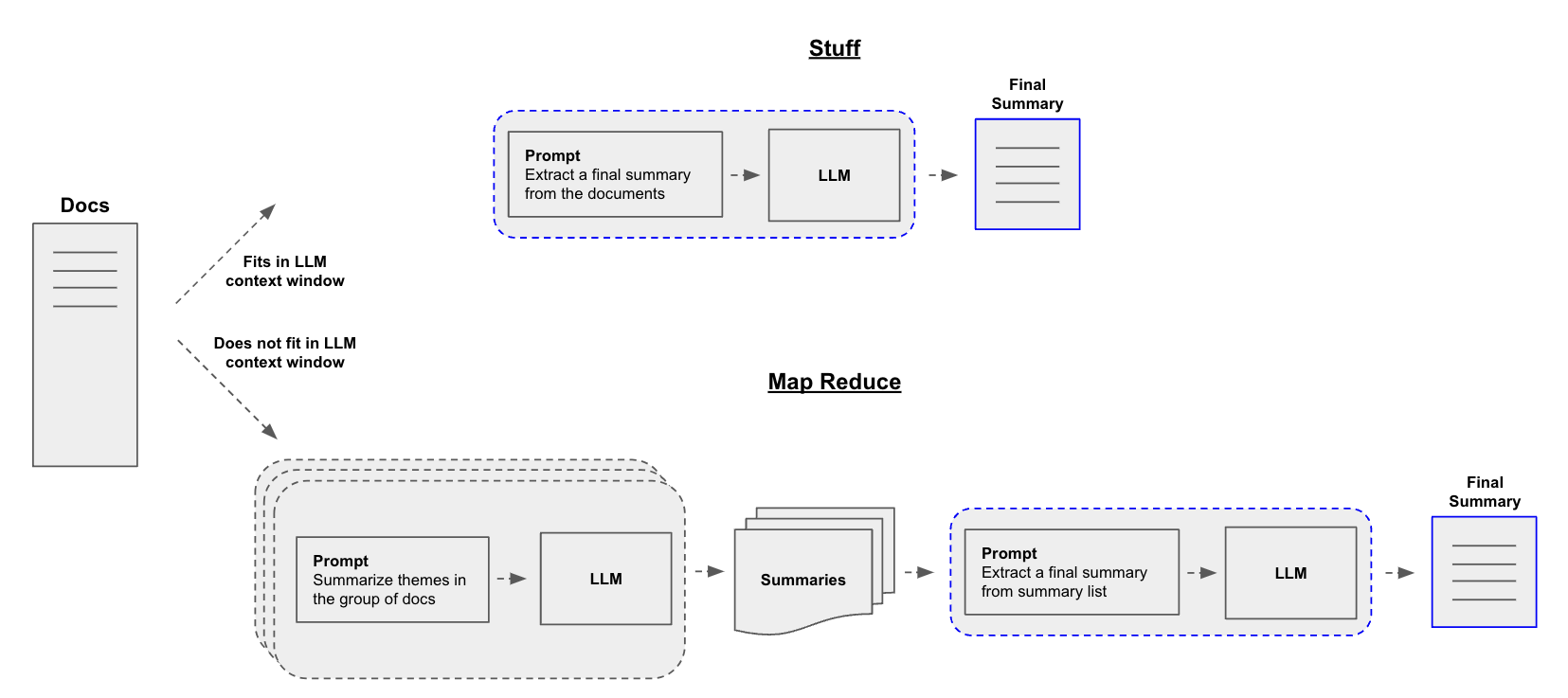
26.[LangChain] Text 요약
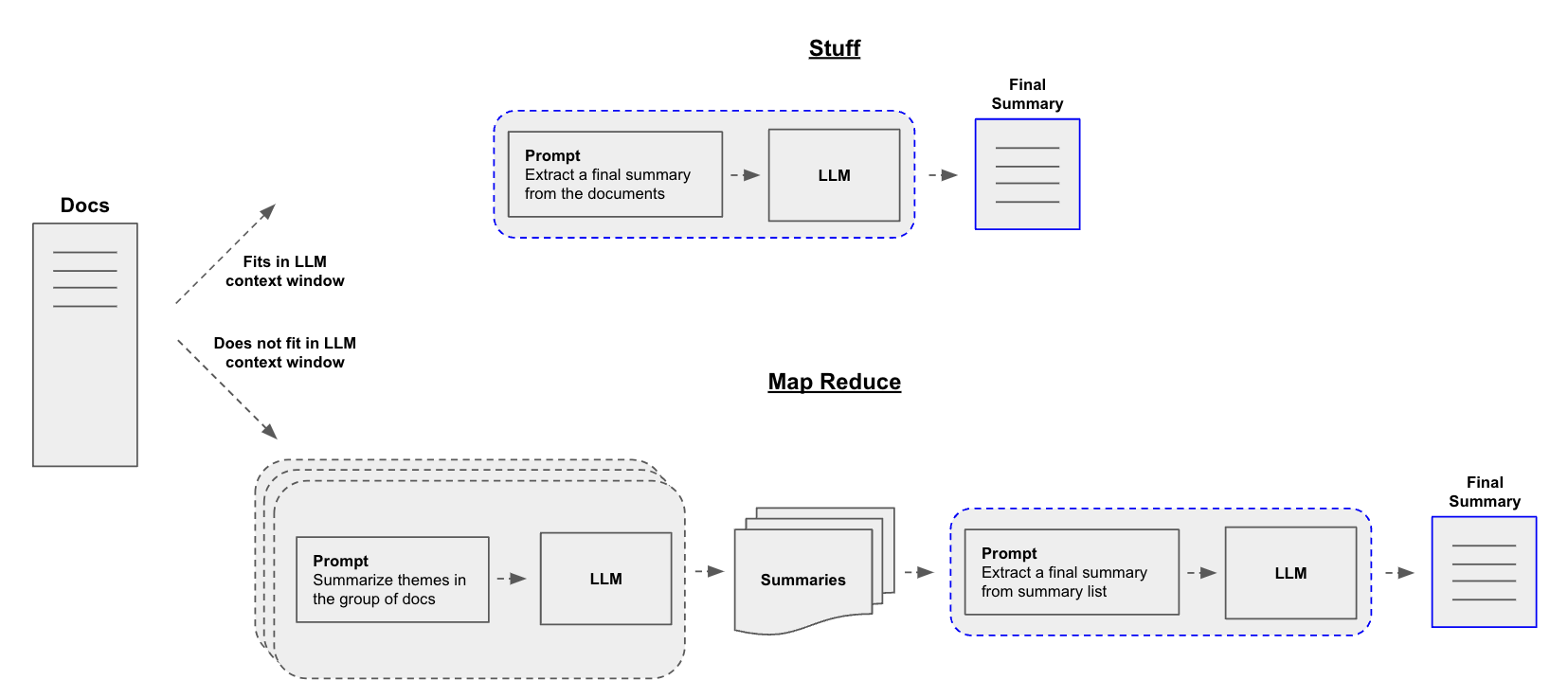
LangChain 으로 Text summarization
27.[ML] ONNX 개요
딥러닝 프레임워크 간의 호환성을 제공하기 위해 만들어진 오픈 소스 모델 교환 형식pytorch, tensorflow, scikit learn, Keras 등 여러 프레임워크에서 학습된 모델을 import, export 할 수 있도록 호환성학습과 배포가 서로 다른 프레임