DHH2020을 진행하기 위해선 기본 지식부터 다른 팀원의 수준까진 아니더라도 이해는 할 수 있을 정도까지 학습이 필요하다고 생각이 됩니다.
내 멘토이자 같은 학교 과선배가 간단한 실행 결과 코드를 보여주며 설명을 해주었는데 역시나 이해하기 위해 필요한 지식이 부족한 것을 느꼈습니다. 따라서, 먼저 선배의 코드의 관련된 기초 지식부터 공부를 하면서 서서히 다른 부분까지 공부를 해보려고 합니다.
학습 순서가 말이 안되도록 뒤죽박죽이니 그려려니하고 봐주셨으면 합니다 :)
학습 요소
1. K-fold Cross Validation
2. ML Model Evaluation
3. 지도학습
4. 비지도학습
5. Ensemble, Stacking
6. numpy methods
7. pandas methods
8. +@학습 진행
1. K-fold Cross Validation
Reference
Geol Choi - [Artificial Intelligence / Posts] 교차검증 (Cross-validation)
Deep Play - 딥러닝 모델의 K-겹 교차검증
nonmeyet - K-Fold Cross Validation(교차검증) 정의 및 설명
일반적으로, 소위 Held-out validation이라 불리는 전체 데이터의 일부를 validation set으로 사용하여 모델의 성능을 평가하는 것은 데이터셋의 크기가 작은 경우 테스트셋에 대한 성능 평가의 신뢰도가 떨어진다는 것입니다.
모델을 평가하기 위해 데이터셋을 Train, Validation으로 분리하였을 때 Train Set에 대하여 학습 시킨 후, Train Set에 대해서는 매우 적합하나 Validation Set에 대해서는 적합하지 않는 경우가 발생할 수 있습니다. 이것을 Overfitting이라고 하는데, 해당 문제가 일어나지 않도록하는 방법 중 다양하게 Train Set과 Validation Set을 지정하여 간접적으로 모델을 효과적으로 검증하는 방법이 Cross Validation입니다.
K-fold Cross Validation은 Train 데이터셋을 균등하게 K개의 그룹(Fold)로 나누고 (K-1)개의 Train Fold와 1개의 Validation Fold를 이용하여 각 검증마다 Validation Fold를 바꿔가며 총 K회 검증을 합니다.
예를 들어 K=5인 K-fold Cross Validation를 진행할 때 다음과 같이
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 |
|---|---|---|---|---|
| Train | Train | Train | Train | Validation |
| Train | Train | Train | Validation | Train |
| Train | Train | Validation | Train | Train |
| Train | Validation | Train | Train | Train |
| Validation | Train | Train | Train | Train |
데이터셋을 5개의 fold로 나누고 각 검증마다 Validation set을 변경해가며 검증을 진행합니다.
해당 검증을 진행하면서 F-1 Score, ROC Curve, AUC등의 모델 평가지표를 통해 적절한 모델을 찾아내면 좋을 것 같습니다.
2. ML Model Evaluation
Reference
우주먼지의 하루 - 모델 성능 평가 지표(회귀 모델, 분류 모델)
EVS : Go Lab - 결정계수(R2)와 설명분산점수(EVS)
[stata] 회귀분석 결과에서 SST, SSE, SSR, R-squared의 의미
예측을 위한 적합한 모델을 선택하기 위해 모델 평가 지표를 통해 모델의 성능을 평가합니다.
또한, 모델에 따른 평가 지표를 다르게 하여 보다 적합한 모델을 선택해야 합니다.
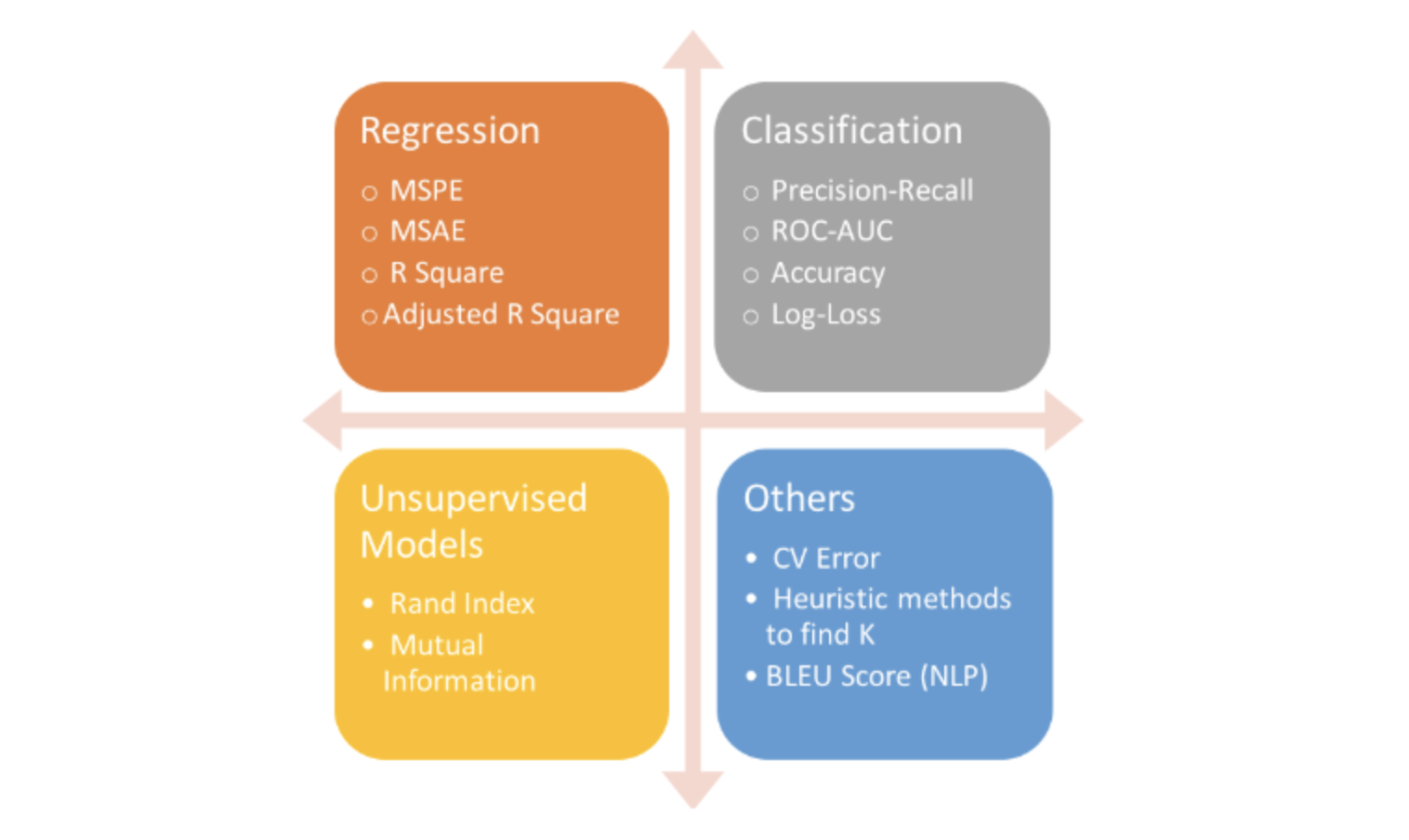
2.1 Regression Model(회귀 모델)
2.1.1 MAE : Mean Absolute Error
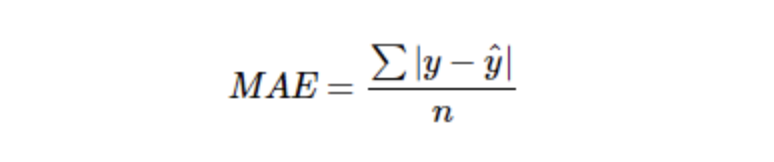
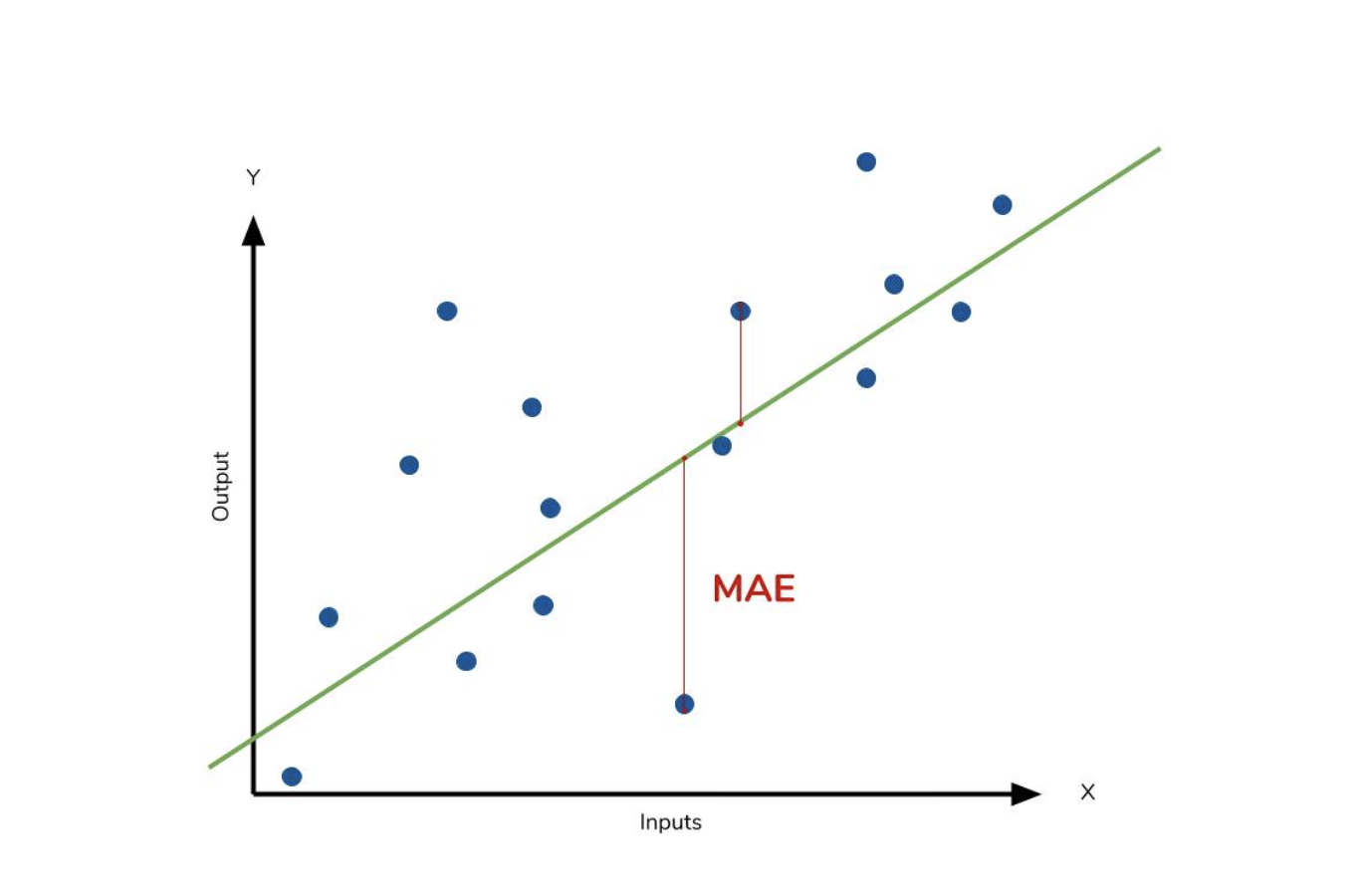
모델의 예측값과 실제값 차를 모두 더한다는 개념입니다.
수식에서 값의 차를 절대값으로 취하기 때문에 가장 직관적으로 알 수 있는 지표이지만 오히려 절대값을 취하기 떄문에 모델이 underperformance인지 overperformance인지 알 수가 없습니다.
- underperformance : 모델이 실제보다 낮은 값으로 예측되는 것
- overperformance : 모델이 실제보다 높은 값으로 예측되는 것
MSE보다 특이치에 대해 robust합니다.
2.1.2 MSE : Mean Squered Error
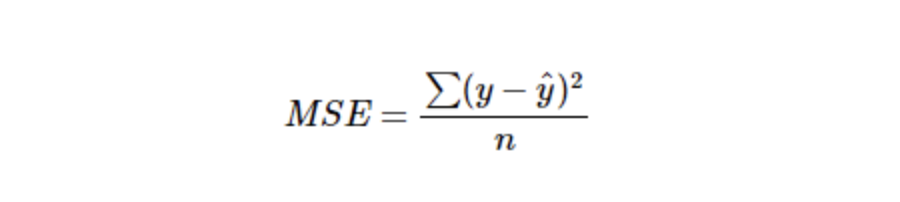
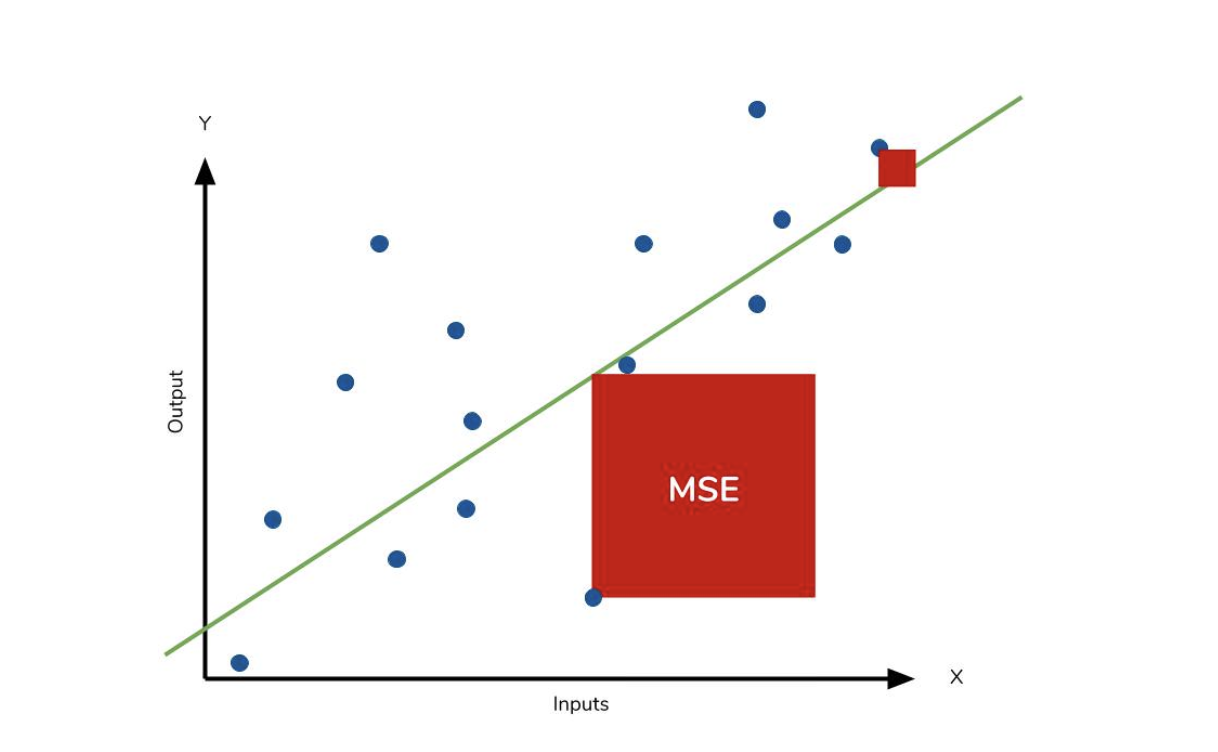
예측값과 실제값의 차를 한변으로 하는 정사각형의 면적의 합입니다. 특이치에 민감한 지표입니다.
2.1.3 RMSE : Root Mean Squared Error
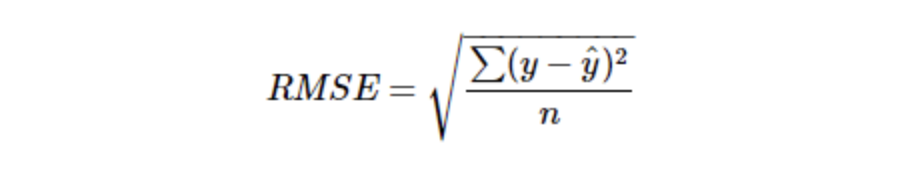
2.1.5의 MSE 값에 Root를 씌운 것입니다.
2.1.4 MAPE : Mean Absolute Percentage Error
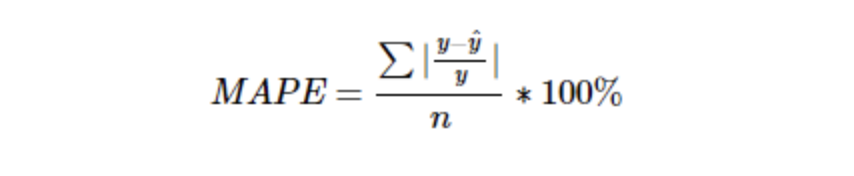
2.1.1의 MAE를 퍼센트로 변환한 것 입니다. 따라서 MAE와 같은 단점을 가지지만 특이치에 MSE보다 robust한 장점을 가지고 있습니다.
실제 값이 0 근처(실제 값이 |실제값-예측값| 보다 작을 경우) 값에 대해서는 사용하기가 어렵습니다.
2.1.5 RMSLE : Root Mean Squere Logarithmic Error)
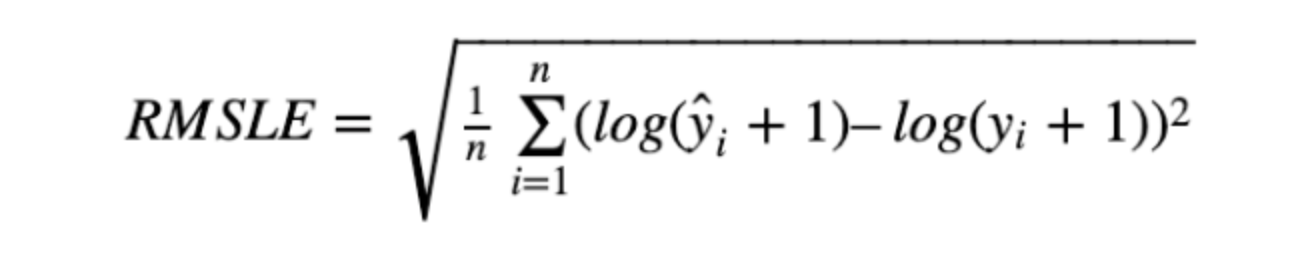
RMSE에 로그를 취해준 것입니다.
아웃라이어에 robust합니다. RMSLE는 아웃라이어가 있더라도 값의 변동폭이 크지 않기 때문이죠.
RMSE와 달리 RMSLE는 예측값과 실제값의 상대적 Error를 측정해줍니다.
예측값이 실제값보다 작을 때 패널티를 부여합니다.
2.1.6 R2-Score : Coefficient of Determination, 결정계수
SST(Sum of Square Total) = SSR(Sum of Square Residual) + SSE(Sum of Square Explained)
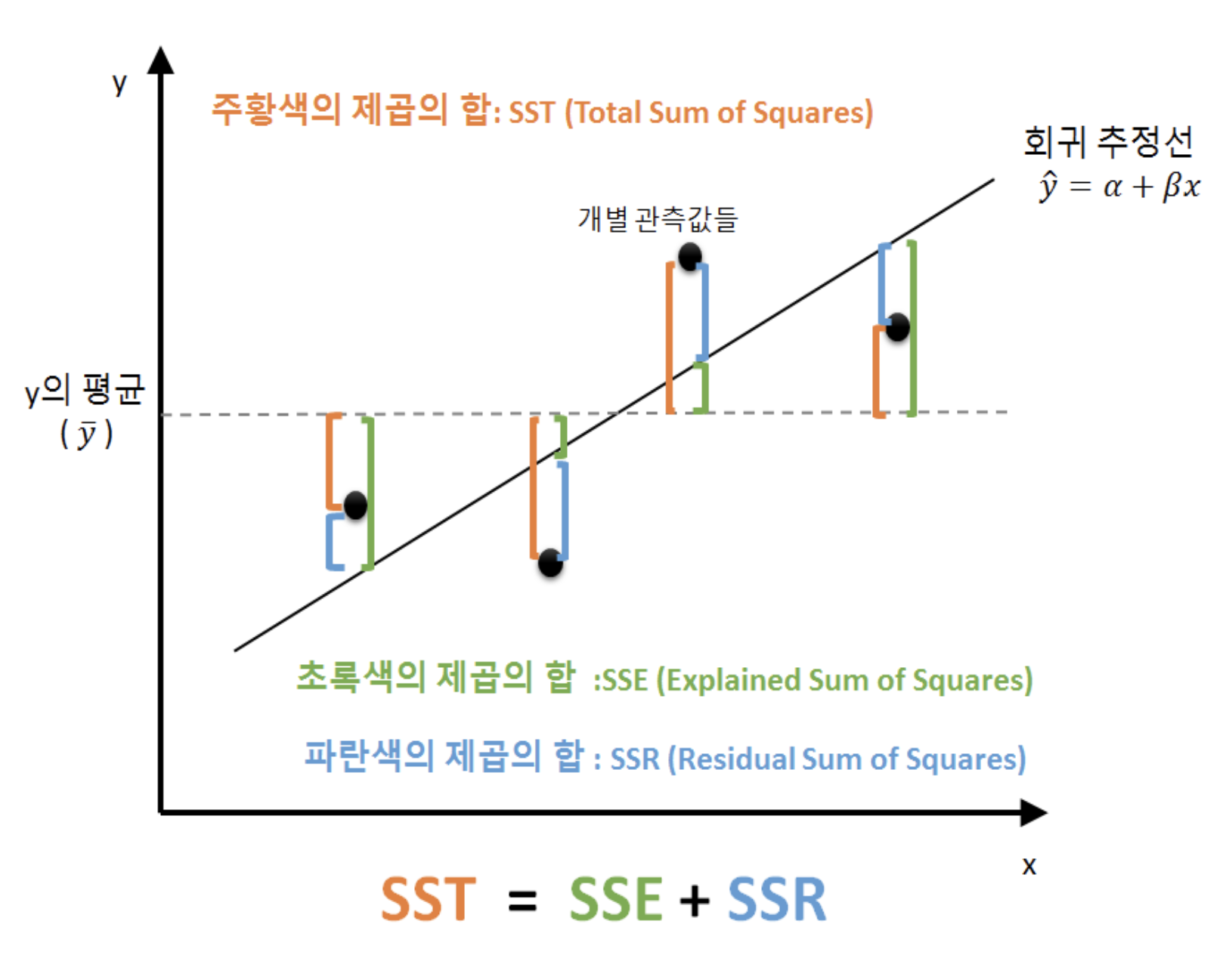

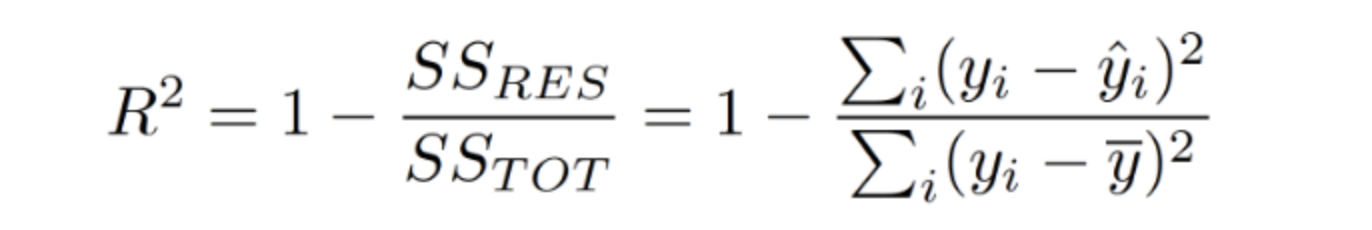
상대적으로 성능이 얼마나 나오는지를 측정한 지표입니다.
다른 성능 지표인 RMSE나 MAE는 데이터의 scale에 따라 값이 천차만별이기 떄문에 절대 값만으로 성능을 판단하기 어렵지만 결정계수의 경우 상대적 성능이기 때문에 보다 직관적으로 알 수 있습니다.
2.1.7 EVS : Explained Variance Score, 설명 분산 점수
참고 자료에서 작성자는 sklearn.metrics 라이브러리를 까서 EVS에 대한 수식을 확인 하였습니다. R제곱 = 1 - (SSR / SST)인데 EVS = 1 - ((SSR - Mean Erro) / SST)의 수식으로 되어있다는 것입니다.
R2 Score와의 유일한 차이점이 분자에 Mean Error를 빼주었다는 것으로 보아 R2와 EVS값이 다르게 나온다면 에러에 편향이 존재하는 것을 뜻하고 피팅이 잘못되었다는 것이라는 것 같습니다.
