본 포스트의 내용은 ML 기초 쌓기 #1에서 이어지는 내용입니다.
2.2 Classification Model(분류 모델)
Reference
PN - [머신러닝] Accuracy (정확도) 란?
우주먼지의 하루 - 모델 성능 평가 지표(회귀 모델, 분류 모델)
곽동현 - ROC curve, ROC_AUC, PR_AUC, 민감도, 특이도\
PN - [머신러닝] Precison과 Recall 이란? (F-measure / Precision-Recall Curve / AUC-PR 개념 포함!)
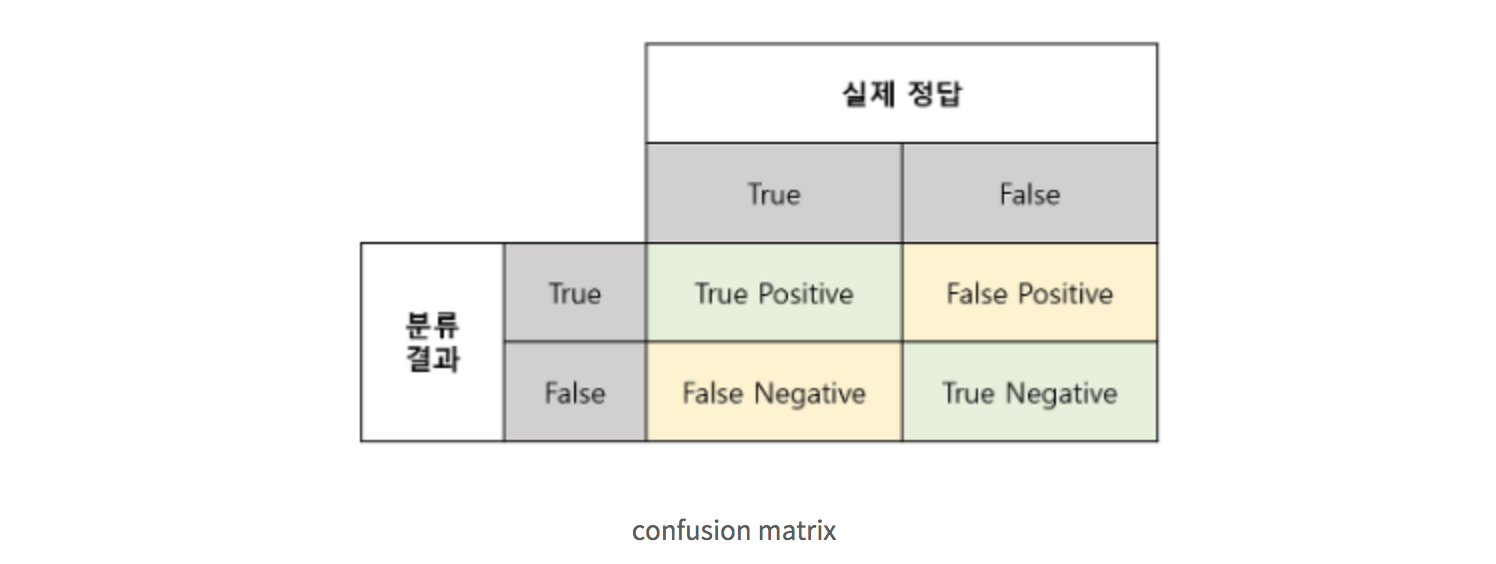
Confusion Matrix(오차행렬)
분류 모델 성능 평가 지표에 대해 이해하기 위해서는 먼저 Confusion matrix에 대해 알고 있어야 합니다.
Confusion matrix는 contingency table또는 an error matrix라고도 불리는데 주로 알고리즘의 성능을 평가할 때 사용됩니다.
- TP(True Positive) : 실제 True인 정답을 True라고 예측
- TN(True Negative) : 실제 False인 정답을 False 예측
- FN(False Negative) : 실제 True인 정답을 False라고 예측
- FP(False Positive) : 실제 False인 정답을 True라고 예측
2.2.1 Accuracy : 정확도
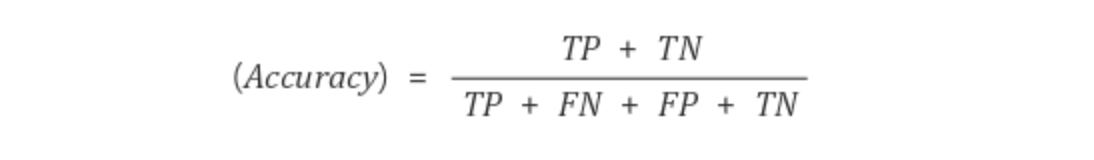
Accuracy는 전체중에서 정답을 맞춘 비율입니다. 단순하게 True, False 상관없이 단지 정답을 맞춘 비율로써 1에 가까울 수록 좋습니다.
예를 들어 실제 데이터는 전체 환자 100명 중 악성 종양을 가지고 있는 환자들이 5명인 데이터가 있습니다.
모델은 100명이 모두 종양이 없다고 예측을 했을 때 Accuracy는(0+95)/100 = 0.95일 것입니다.
그렇다면 Accuracy는 1에 가깝기 때문에 Accuracy로만 모델을 평가한다면 좋은 모델이겠네요. 하지만 이것이 진짜 좋은 모델일까요?
위의 예시와 같이 Accuracy는 bias한 데이터에 관해 심각한 단점을 가집니다.
이와 같이 실제 데이터에 대한 Negative 비율이 매우 높아서 발생할 수 있는 상황해 대하여 제대로 된 분류를 해주는지 평가를 해줄 지표는 Precision과 Recall입니다.
2.2.2 Precision : 정밀도

Precision은 모델이 True라고 예측한 것 중에서 실제 True인 것의 비율입니다. PPV(Positive Prediction Value)라고도 불리며 1에 가까울 수록 좋습니다.
Accuracy에서의 예와 비슷하게 종양 환자에 대한 예를 들어봅시다.
모델에서 악성 종양이 있는 환자 1명을 맞추고(TP = 1)그 외에는 전부 악성 종양이 없다고 예측했습니다.(TN = 95, FP = 0, FN = 4)
그렇다면 Precision은1/(1+0) = 1입니다.
위의 예시 또한 이상한 결과가 나옵니다.
2.2.3 Recall : 재현율
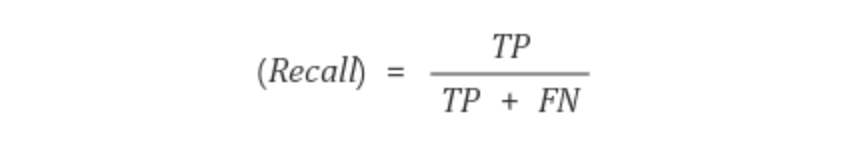
Recall은 실제 True인 것 중에서 모델이 True라고 예측한 비율입니다. 1에 가까울 수록 좋습니다.
Recall 또한 Precision과 비슷한 단점을 지니고 있습니다.
Precision과 Recall 두 지표는 1에 가까울 수록 좋은 모델이지만 둘은 서로 반비례하는 경향이 있습니다. 이를 보완하기 위해 이 둘의 조화평균하는 F1 score라는 지표가 등장했습니다.
2.2.4 F1 score

F1 score는 Precision과 Recall을 조화평균한 값입니다.
조화 평균이란 주어진 수의 역수를 산술 평균한 값을 다시 역수한 값입니다.
ex) A, B ->2/(1/A + 1/B)
산술 평균을 하지 않고 조화 평균을 구하는 이유는 두 지표 중 하나가 0에 가깝에 낮을 때 지표(F1 score)에 잘 반영이 되어 모델의 성능 검증을 보다 정확하게 하기 위함입니다.
2.2.5 AUPRC - PRC(Precision - Recall Curve) AUC(Area Under the Curve)
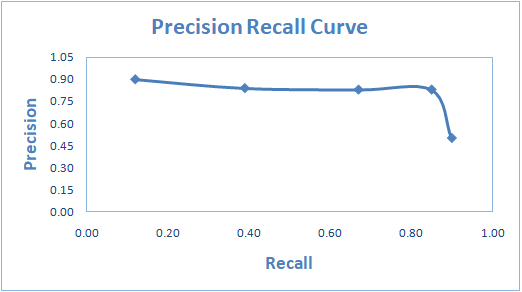
AUPRC는 x축을 Recall, y축을 Precision으로 설정하여 그린 곡선 아래의 면적 값인 모델 평가 지표입니다.
두 값은 서로 반비례하는 관계를 가지고 있기 때문에 x축 오른쪽으로 갈 수록 하향하는 곡선을 가지게 됩니다.
Precision과 Recall 두 지표다 1에 가까우면 좋은 모델이기 때문에 AUPRC의 값도 1에 가까울 수록 좋은 모델입니다.
2.2.6 Fall-out
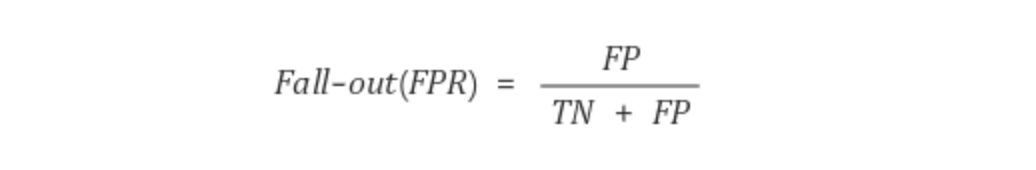
Fall-out 지표는 실제 False인 데이터 중에서 잘못 분류되어진 값의 비율입니다.
0에 가까울 수록 좋겠네요.
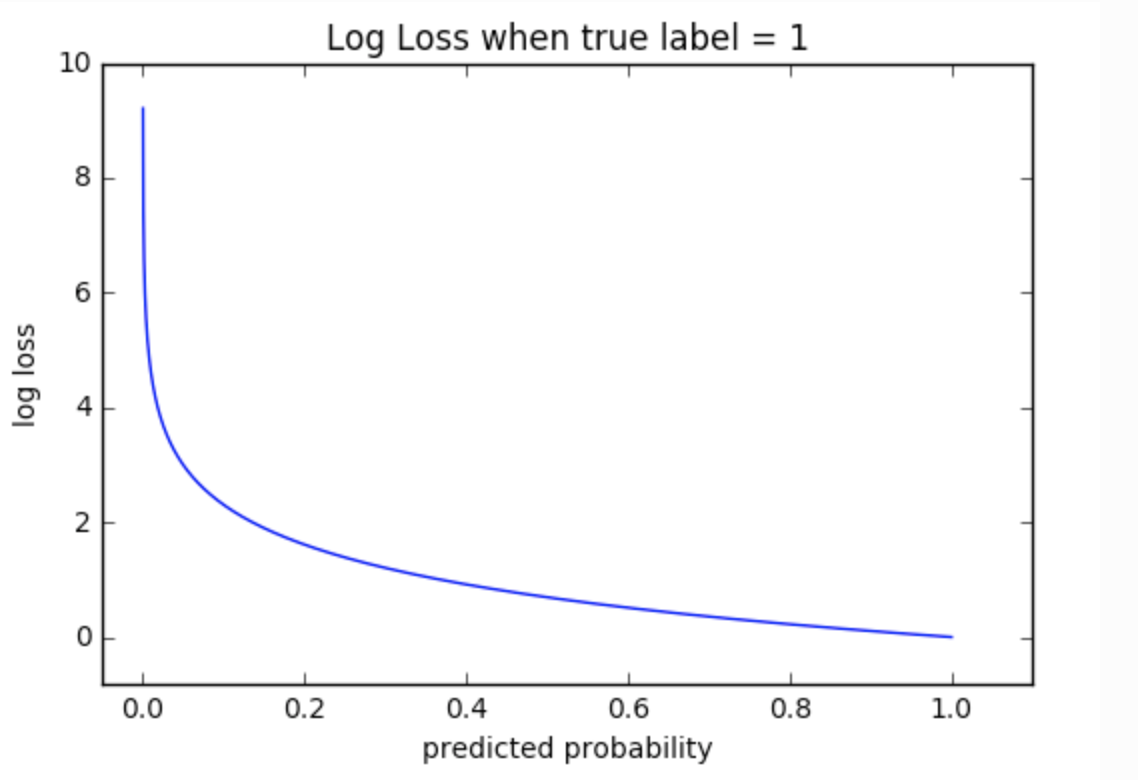
2.2.7 Log Loss
Log Loss는 모델이 예측한 학률 값을 음의 log함수에 넣어 변환을 시킨 값으로 평가를 진행합니다. 따라서 값이 0에 가까울 수록 좋은 모델입니다.
예를 들어 예측 확률이 100%이면
-log(1.0) = 0입니다.
2.2.8 ROC(Receiver Operating Characteristic) AUC(Area Under the Curve) = AUROC
ROC곡선은 Binary Classifier Model에 대한 성능 평가 기법 중 하나입니다.
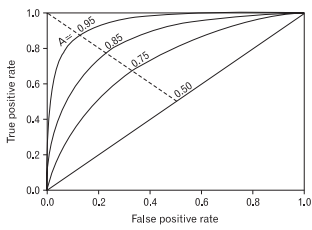
y축은 TP rate, x축은 FP rate인데 일반적으로 TP rate와 FP rate는 비례하는 관계에 있습니다.
좋은 성능 지표인 TP rate를 상승시키려면 나쁜 성능 지표인 FP rate도 상승한다는 것입니다.
따라서 해당 모델의 성능을 판단하기 위해서 특정 기준을 연속적으로 바꾸어 가면서 TP rate, FP rate를 측정해야하고 이 측정값을 시각화한 것이 ROC 곡선입니다.
이때 Scikit-learn에서는 ROC 곡선 아래의 면적(AUC: Area Under the Curve) 을 측정하여 성능을 평가하는 AUROC라는 평가 지표로 사용합니다.
ROC curve를 다른 그림으로 이해해봅시다.
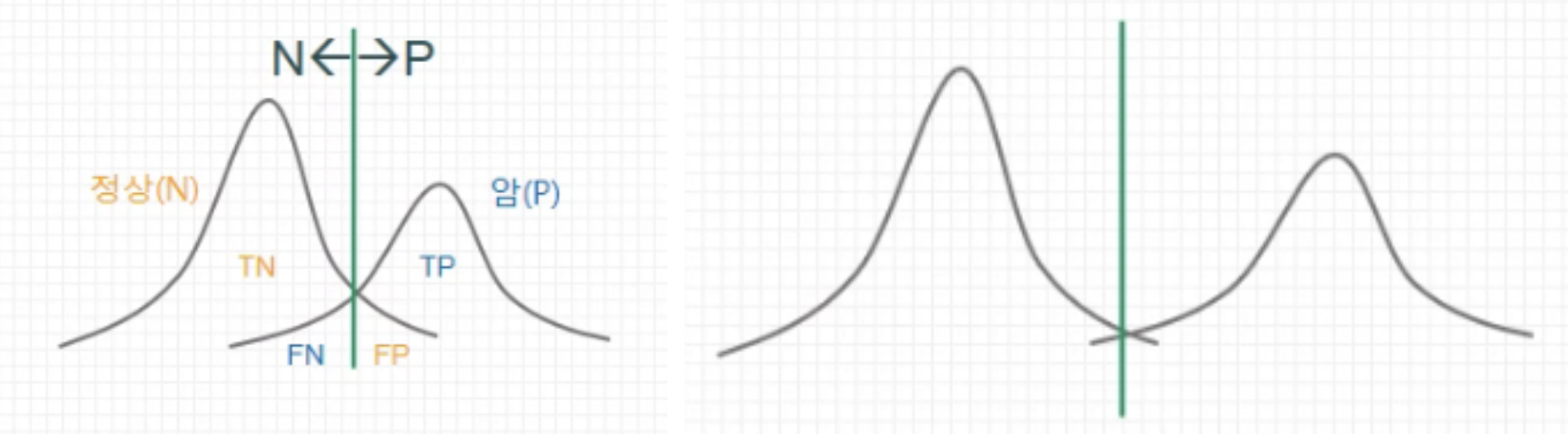
위의 분포 곡선이 곂치지 않을 수록 면적(TN + TP - FN - FP)이 넓어집니다.
따라서, ROC 곡선의 면적이 1에 가까울 수록 좋은 모델임을 확인해줍니다.

Precision은 모델이 True라고 예측한 것 중에서 실제 True인 것의 비율입니다. PPV(Positive Prediction Value)라고도 불리며 1에 가까울 수록 좋습니다. -> 모델이 Positive라고 예측한 것 중에서 실제로 True인 것의 비율 이라고 표현해야 맞는거 아닌가요?