마이크로서비스 아키텍처(MSA)가 대세로 자리 잡으면서, 수많은 서비스 간의 트래픽을 효율적으로 관리하고, 외부 요청을 안전하게 처리하는 기술의 중요성은 더욱 커졌습니다. 이때 등장하는 핵심 컴포넌트가 바로 API 게이트웨이(API Gateway)와 로드 밸런서(Load Balancer)입니다.
이 둘은 종종 함께 사용되지만, 각자의 역할과 책임 범위에는 분명한 차이가 있습니다. 이 글에서는 API 게이트웨이와 로드 밸런서의 기본 개념부터 시작하여, 주요 기능, 다양한 알고리즘, 글로벌 빅테크 기업들의 활용 사례, 그리고 실무에 적용할 수 있는 설계 팁까지 깊이 있게 파헤쳐 보겠습니다. "단순 트래픽 분산기"를 넘어선 이들의 진정한 가치를 함께 알아봅시다!
1. API 게이트웨이란 무엇인가? 마이크로서비스의 프론트 데스크
API 게이트웨이는 마이크로서비스 아키텍처에서 모든 외부 클라이언트 요청의 단일 진입점(Single Entry Point) 역할을 수행하는 서버 또는 서비스입니다. 마치 호텔의 프론트 데스크가 방문객의 체크인, 키 발급, 각종 문의 응대 등 다양한 업무를 일괄 처리하듯, API 게이트웨이는 다음과 같은 핵심적인 공통 기능을 중앙에서 처리합니다.
- 라우팅 (Routing): 클라이언트의 요청을 적절한 내부 마이크로서비스로 전달합니다.
- 인증 및 인가 (Authentication & Authorization): API 키 검증, JWT 토큰 유효성 확인, 사용자 권한 체크 등 보안 관련 기능을 수행합니다.
- 요청/응답 변환 (Request/Response Transformation): 클라이언트와 백엔드 서비스 간의 데이터 포맷(예: XML ↔ JSON)을 변환하거나, 필요한 헤더를 추가/제거합니다.
- 속도 제한 (Rate Limiting) 및 스로틀링 (Throttling): 특정 클라이언트나 API에 대한 요청 수를 제한하여 시스템 과부하를 방지합니다.
- 로깅 및 모니터링 (Logging & Monitoring): 모든 API 호출에 대한 로그를 기록하고, 사용량, 에러율 등의 메트릭을 수집하여 모니터링 시스템으로 전송합니다.
- 캐싱 (Caching): 자주 요청되는 응답을 캐싱하여 백엔드 부하를 줄이고 응답 속도를 향상시킵니다.
- API 버전 관리, API 문서화 지원 등
언제 필요할까?
- 마이크로서비스 아키텍처: 수십 개 이상의 서비스가 분리되어 운영될 때, 클라이언트가 각 서비스의 엔드포인트를 직접 호출하는 것은 매우 비효율적이고 관리하기 어렵습니다. API 게이트웨이가 이 복잡성을 숨기고 단일 인터페이스를 제공합니다.
- 공통 기능 중앙 집중화: 인증, 로깅, 트래픽 제어 등 여러 서비스에 걸쳐 반복적으로 구현해야 하는 횡단 관심사(Cross-cutting Concerns)를 게이트웨이에서 일괄 처리하여 개발 생산성을 높이고 유지보수 비용을 절감합니다.
언제 불필요할까?
- 단일 서버/모놀리식 아키텍처: 클라이언트가 직접 단일 서비스 엔드포인트에 접근하는 것이 합리적이고 관리 가능한 경우.
- 단순한 트래픽 분산만이 목적이라면 로드 밸런서만으로 충분할 수 있습니다.
💡 AWS의 관리형 API 게이트웨이: Amazon API Gateway
Amazon API Gateway는 RESTful, WebSocket, HTTP API를 손쉽게 생성, 게시, 유지 관리, 모니터링 및 보호할 수 있는 완전 관리형 서비스입니다. AWS Lambda, EC2, ALB, S3 등 다양한 AWS 백엔드 서비스와의 통합, IAM/Cognito를 통한 인증/인가, 요청/응답 변환, 캐싱, CloudWatch 연동 모니터링 등 API 게이트웨이의 핵심 기능을 편리하게 제공합니다.
보안 기능: AWS WAF(Web Application Firewall)와 통합하여 SQL 인젝션, XSS 등 일반적인 웹 공격 방어, IP 기반 접근 제어, 지리적 제한, 봇 제어 등의 보안 기능을 강화할 수 있으며, TLS 암호화, 요청 유효성 검사 등도 지원합니다.
2. 로드 밸런서란 무엇인가? 트래픽 분산의 해결사
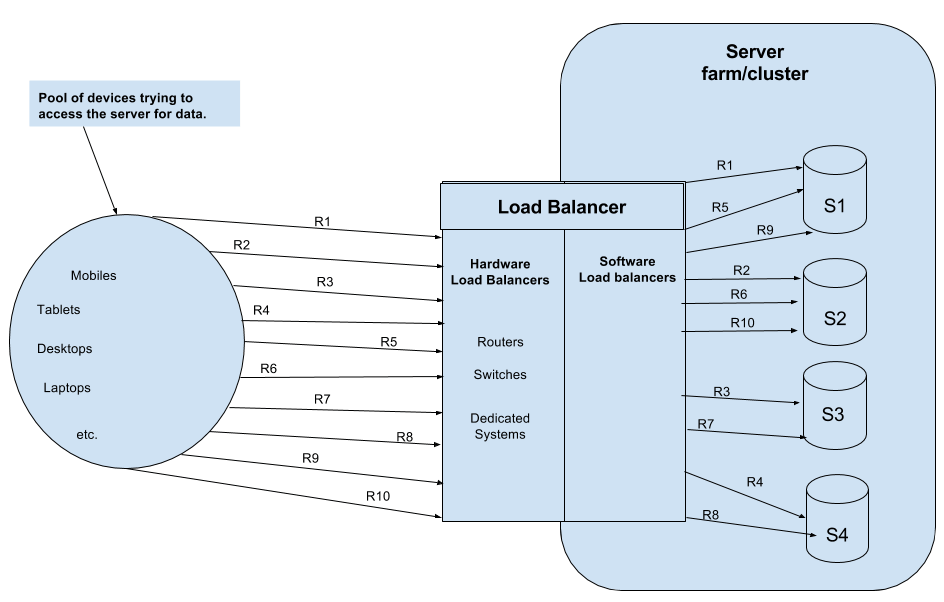
로드 밸런서(Load Balancer)는 여러 대의 서버(백엔드 인스턴스)로 들어오는 네트워크 트래픽을 효율적으로 분산시켜 특정 서버에 과부하가 걸리는 것을 방지하고, 시스템 전체의 성능, 가용성, 확장성을 향상시키는 핵심 네트워크 컴포넌트입니다.
로드 밸런서의 주요 기능:
- 트래픽 분산 (Traffic Distribution): 수신되는 요청을 설정된 알고리즘에 따라 여러 서버에 고르게 분배합니다.
- 고가용성 (High Availability): 헬스 체크(Health Check)를 통해 특정 서버에 장애가 발생하면, 해당 서버로는 트래픽을 보내지 않고 정상 작동하는 다른 서버로 자동으로 전환하여 서비스 중단을 최소화합니다.
- 확장성 (Scalability): 트래픽 증가에 맞춰 백엔드 서버를 유연하게 추가(Scale-out)하거나 제거(Scale-in)할 수 있도록 지원합니다. 로드 밸런서가 새로운 서버를 감지하고 트래픽 분산 대상에 포함시킵니다.
- 세션 지속성 (Session Persistence / Sticky Session): 특정 클라이언트의 요청이 항상 동일한 서버로 전달되도록 보장하여, 세션 정보를 유지해야 하는 애플리케이션을 지원합니다.
- SSL 종료 (SSL Termination): 클라이언트와 로드 밸런서 간의 HTTPS 통신 암호화/복호화 처리를 로드 밸런서에서 담당하여 백엔드 서버의 부하를 줄입니다.
- (일부 고급 기능) 보안 강화: DDoS 공격 방어, 웹 방화벽(WAF) 연동 등의 기능을 제공하기도 합니다.
다양한 로드 밸런싱 알고리즘:
로드 밸런서는 다음과 같은 다양한 알고리즘을 사용하여 트래픽을 분산합니다.
- 라운드 로빈 (Round Robin): 요청을 서버 목록 순서대로 돌아가며 균등하게 분배합니다. 가장 단순하고 일반적인 방식입니다.
- 가중 라운드 로빈 (Weighted Round Robin): 각 서버의 처리 능력(성능)에 따라 가중치를 부여하고, 가중치가 높은 서버에 더 많은 요청을 분배합니다.
- 최소 연결 (Least Connections): 현재 활성 연결 수가 가장 적은 서버로 요청을 보냅니다. 서버마다 처리 시간이 다를 때 효과적입니다.
- IP 해시 (IP Hash / Source IP Hash): 클라이언트의 IP 주소를 해싱하여 특정 서버에 고정적으로 매핑합니다. 세션 지속성이 필요할 때 사용됩니다.
- 최소 응답 시간 (Least Response Time): 가장 최근의 평균 응답 시간이 가장 빠른 서버로 요청을 보냅니다. (실제 응답 시간 측정 필요)
- (기타) Consistent Hashing, URL Hash 등
💡 로드 밸런서는 단순 분산기가 아니다! 빅테크의 스마트 라우팅
많은 개발자들이 로드 밸런싱을 "라운드 로빈으로 트래픽을 서버에 고르게 보내는 것" 정도로 이해하지만, 실제 대규모 서비스를 운영하는 빅테크 기업들은 훨씬 더 정교하고 지능적인 로드 밸런싱 전략을 사용합니다. 이들은 다음과 같은 다양한 요소를 고려하여 스마트 라우팅(Smart Routing)을 구현합니다.
- 사용자의 지리적 위치 및 네트워크 지연 시간
- 서버의 실시간 CPU/메모리 부하, 디스크 I/O, 네트워크 대역폭
- 요청의 종류 및 크기 (예: 작은 API 요청 vs. 대용량 파일 다운로드)
- TCP 연결 상태 및 지속 시간
- 캐시 적중률 및 데이터 지역성(Locality)
- 장애 발생 시의 신속하고 안정적인 장애 극복(Failover) 전략
이러한 요소들을 종합적으로 고려하여, 사용자에게 최상의 경험을 제공하고 시스템 자원을 최대한 효율적으로 사용하는 것이 현대 로드 밸런싱의 목표입니다.
AWS의 다양한 로드 밸런서 종류:
AWS는 다양한 워크로드와 요구사항에 맞춰 여러 종류의 로드 밸런서를 제공합니다.
- Application Load Balancer (ALB): HTTP/HTTPS (L7) 트래픽에 최적화되어 있으며, URL 경로 기반 라우팅, 호스트 헤더 기반 라우팅, 쿼리 문자열 기반 라우팅 등 고급 라우팅 규칙을 지원합니다. 마이크로서비스 아키텍처에 널리 사용됩니다.
- Network Load Balancer (NLB): TCP/UDP (L4) 트래픽 처리에 최적화되어 있으며, 초당 수백만 건의 요청을 매우 낮은 지연 시간으로 처리할 수 있는 고성능 로드 밸런서입니다. 고정 IP 주소를 제공할 수 있습니다.
- Gateway Load Balancer (GWLB): 방화벽, 침입 탐지/방지 시스템(IDS/IPS) 등 서드파티 가상 네트워크 어플라이언스를 손쉽게 배포하고 확장하며 관리할 수 있도록 지원합니다.
- Classic Load Balancer (CLB): 이전 세대의 로드 밸런서로, EC2-Classic 네트워크 환경에서 주로 사용되었습니다. (신규 사용은 권장되지 않음)
3. 글로벌 빅테크 기업들의 로드 밸런서 활용 사례 엿보기
글로벌 빅테크 기업들은 자체적으로 고도화된 로드 밸런싱 기술을 개발하고 운영하여 엄청난 규모의 트래픽을 처리하고 있습니다. 몇 가지 사례를 통해 이들의 접근 방식을 살펴보겠습니다.
-
Meta (Facebook) - Katran:
- 기술: L4 로드 밸런서. Linux 커널의 eBPF(extended Berkeley Packet Filter) 기술을 활용하여 매우 높은 성능과 유연성을 제공합니다.
- 특징: 커널 레벨에서 직접 로드 밸런싱을 수행하여 사용자 공간(User-space)으로의 컨텍스트 스위칭 오버헤드가 없습니다. Facebook.com의 모든 수신 트래픽을 처리하며, Dropbox 등 다른 기업에서도 채택하여 사용 중입니다.
- 핵심 전략: 주로 Source IP 해싱과 가중 최소 연결(Weighted Least Connection) 알고리즘을 사용하며, 장애 서버는 자동으로 제외합니다. 사용자 IP를 해싱하여 동일 사용자의 요청이 가능한 한 동일 서버로 연결되도록 함으로써 TCP 세션 유지 및 캐시 효율을 극대화합니다.
-
Google - Maglev & Prequal:
- Maglev: Google이 자체 개발한 소프트웨어 기반 분산 로드 밸런서로, Google Cloud Load Balancing의 핵심 기술입니다.
- 기술: L4 ~ L7 로드 밸런싱. 일관된 해싱(Consistent Hashing) 기반의 라우팅 테이블을 사용하여 서버 증설/삭제 시에도 기존 연결 매핑의 안정성을 최대한 유지합니다.
- 특징: 로드 밸런서당 초당 수백만 건의 요청 처리가 가능하며, 높은 확장성과 안정성을 자랑합니다.
- Prequal (YouTube): YouTube에서 사용하는 로드 밸런서로, 실시간 요청 지연을 최소화하고 서버 용량을 효율적으로 활용하는 데 중점을 둡니다.
- 핵심 전략: 동일 클라이언트 요청을 동일 서버로 보내는 것보다, 서버 그룹의 상태 변화(추가/삭제/장애)에도 안정적인 연결 매핑을 유지하는 것을 더 중요하게 여깁니다.
-
Netflix - AWS ALB + eBPF 기반 최적화:
- 기술: L4 ~ L7 혼합. 기본적으로 AWS의 ALB를 활용하며, 내부적으로 eBPF를 사용하여 네트워크 관측성 확보 및 성능 진단을 통해 로드 밸런싱 효율을 높입니다.
- 특징: 글로벌 트래픽을 자체 CDN인 Open Connect와 연계하여 분산 처리하며, Edge → Regional → Origin으로 이어지는 계층적인 로드 밸런서 구조를 가집니다.
- 핵심 전략: 스트리밍 트래픽의 특성상, 단순 요청 분배를 넘어 응답 시간과 네트워크 지연율까지 고려한 동적인 트래픽 분산이 중요합니다. ALB의 URI 경로 기반 라우팅 외에도 내부적으로 Least Response Time과 유사한 알고리즘을 활용하는 것으로 알려져 있습니다.
-
기타 기업 (Cloudflare, Dropbox, Yahoo!, Walmart 등): 이들 역시 자체 개발 솔루션(예: Cloudflare의 Unimog) 또는 오픈소스(예: Cilium, Katran) 및 eBPF 기술을 적극적으로 활용하여 고성능, 고가용성의 로드 밸런싱 시스템을 구축하고 운영하고 있습니다.
4. API 게이트웨이 확장 전략 및 실무 설계 팁
API 게이트웨이 확장 전략:
- 수평 확장 (Horizontal Scaling): API 게이트웨이는 일반적으로 상태를 가지지 않는(Stateless) 컴포넌트로 설계되므로, 로드 밸런서(ELB 등) 뒤에 여러 인스턴스를 배치하여 쉽게 수평 확장이 가능합니다.
- 글로벌 분산 (Global Distribution): 여러 리전(Region)에 API 게이트웨이를 배포하고, Route 53(AWS)과 같은 GeoDNS 서비스를 사용하여 사용자 위치에 가장 가까운 게이트웨이로 요청을 라우팅합니다. 이때, 게이트웨이 간의 설정 및 정책 동기화 방안을 마련해야 합니다.
- 게이트웨이 내부의 서비스별 로드 밸런싱: API 게이트웨이가 여러 백엔드 마이크로서비스로 요청을 라우팅할 때, 각 서비스 그룹(Target Group)에 대해 내부적으로 로드 밸런싱을 수행할 수 있습니다.
실무에 적용 가능한 로드 밸런싱/API 게이트웨이 설계 팁:
- 헬스 체크(Health Check)는 필수! 로드 밸런서가 백엔드 서버의 상태를 주기적으로 확인하여, 정상적인 서버로만 요청을 전달하도록 설정해야 합니다. 헬스 체크 없는 로드 밸런서는 무용지물입니다.
- 단순 Round Robin은 초보적인 설계일 수 있습니다. 실제 운영 환경에서는 서버별 처리 능력, 현재 연결 수, 응답 시간 등을 고려한 보다 지능적인 분산 알고리즘(예: Least Connections, Weighted Round Robin) 선택이 필요합니다.
- 로드 밸런서 유형 선택의 기준 (ALB vs. NLB vs. Katran/eBPF):
- ALB: L7 기능(경로 기반 라우팅, 호스트 기반 라우팅 등), HTTPS 트래픽 처리가 중심일 때.
- NLB: 초고속 TCP/UDP 처리, 고정 IP, 극도의 낮은 지연 시간이 필요할 때.
- Katran/eBPF 기반 자체 솔루션: 초대규모 트래픽 처리, 커널 레벨에서의 세밀한 제어 및 최적화가 필요할 때. (구현 및 운영 난이도 높음)
- 일관된 해싱(Consistent Hashing)의 중요성: 서버 그룹 변경(추가/삭제/장애) 시 기존 연결 및 캐시의 영향을 최소화해야 하는 분산 캐시, 스트리밍 서비스, 장기 세션 유지 애플리케이션 등에서는 필수적으로 고려해야 합니다.
- 이중화(HA) 및 다중 가용 영역(Multi-AZ) 구성은 기본입니다. 단일 로드 밸런서는 그 자체로 단일 실패 지점(SPOF, Single Point of Failure)이 될 수 있으므로, 로드 밸런서 자체도 이중화 구성하는 것이 중요합니다.
- API 게이트웨이는 "만능 도구"가 아닌 "목적에 맞는 도구"입니다. 모든 것을 API 게이트웨이에서 처리하려 하기보다는, 핵심 기능(라우팅, 인증, 공통 미들웨어)에 집중하고, 복잡한 비즈니스 로직은 백엔드 서비스에 위임하는 것이 좋습니다. 게이트웨이 뒤단의 서비스 아키텍처(서비스 분리, DB 구성, 스케일링 전략 등)가 더 중요합니다.
5. 실전형 시나리오 문제와 해설 방향
시나리오 #1: 실시간 주식 트레이딩 플랫폼
- 상황: 고빈도 거래 요청이 밀려드는 주식 매매 API 서버. 동일 사용자는 로그인 상태 유지 필요, 연결 단절 시 거래 실패 가능성.
- 요구사항: 순간적인 트래픽 급증 대응, 사용자 세션 유지, 트랜잭션 신뢰성 및 성능 모두 중요.
- 질문:
- 어떤 로드 밸런서 알고리즘을 사용할 것인가?
- 세션 유지와 장애 복구를 동시에 만족시키기 위한 구성은?
- 응답 지연 발생 시 동적으로 트래픽을 조정할 방법은?
- 해설 방향:
- IP Hash 또는 세션 선호도(Session Affinity / Sticky Session) 알고리즘 사용 (ALB에서 지원). 사용자 세션이 동일 서버에 유지되어야 주문 누락/중복 방지.
- ALB + Sticky Session 설정. 백엔드 서버에 헬스 체크를 구성하여, 세션이 유지되더라도 서버 장애 시 다른 정상 서버로 트래픽 자동 전환. 오토스케일링 그룹(ASG)으로 트래픽 급증에 유연하게 대응. 백엔드에는 DB 트랜잭션 기반 재시도 로직 구현.
- ALB 자체의 동적 가중치 조정은 제한적. NGINX + Lua 등을 사용한 커스텀 로드 밸런서 또는 서비스 메시(예: Istio)를 활용하면 서버 상태(CPU, 지연 시간 등) 기반 동적 가중치 조정 가능. 또는 Amazon Global Accelerator + Route 53 Failover (EC2 헬스/CloudWatch 기반) 조합으로 지리적으로 최적화된 서버 유도 및 장애 시 지역 페일오버 고려.
시나리오 #2: 글로벌 동영상 스트리밍 플랫폼 (YouTube 유사)
- 상황: 전 세계 사용자 대상 동영상 스트리밍. 영상은 조각(Chunk) 단위 전달, 끊김 없는 서비스 중요.
- 요구사항: 요청 단위 크고 연결 시간 김, 지역별 분산 처리, 버퍼링 최소화.
- 질문:
- 어떤 로드 밸런서와 알고리즘을 사용할 것인가?
- Edge 서버를 고려한 아키텍처 구성은?
- 특정 지역 과부하 발생 시 처리 방법은?
- 해설 방향:
- NLB + Least Connections 또는 Least Response Time 알고리즘. 동영상 스트리밍은 지속적인 연결과 대량 트래픽 발생. 부하가 적고 응답이 빠른 서버로 연결 분배, TCP 지연 최소화가 핵심.
- CloudFront CDN + Origin Load Balancer (ALB/NLB) 조합. 영상 콘텐츠는 전 세계 Edge Location에 캐싱, 사용자에게 가장 가까운 POP에서 제공. Origin Shield + Regional Edge Cache 설정으로 원본 서버 호출 최소화.
- CloudFront는 위치 기반 자동 라우팅. 특정 POP 과부하 시 다른 POP로 Failover 가능. Edge 서버 수용 한계 초과 시 Amazon Global Accelerator로 라우팅 재조정 또는 Regional Failover 설정. 백엔드 서버는 ASG + Target Group Health Check로 수평 확장 및 자동 복구.
시나리오 #3: 마이크로서비스 기반 쇼핑몰
- 상황:
/products,/cart,/checkout,/orders등 URI별 서비스 분리. 트래픽은 상품 검색 → 장바구니 → 결제 흐름. - 요구사항: 경로별 트래픽 분산, 일부 서비스 장애 시 전체 서비스 영향 최소화, 서비스별 독립 배포 및 스케일링.
- 질문:
- 어떤 라우팅 전략이 가장 적절한가?
- 서비스 장애 격리와 경로 분리를 어떻게 구현할 것인가?
- AWS 기준으로 구현한다면 어떤 구조로 만들 것인가?
- 해설 방향:
- ALB + 경로 기반 라우팅(Path-based Routing). 각 URI 패턴(
/products,/cart등)에 따라 서로 다른 백엔드 서비스 그룹으로 라우팅. - 서비스별 독립적인 Target Group 구성. 각 Target Group은 자체 헬스 체크 설정. 특정 서비스(예:
/products담당) 장애 시 해당 Target Group으로의 라우팅만 중단, 다른 서비스는 정상 동작 (장애 격리). 백엔드 서비스는 서킷 브레이커 패턴 적용 고려. - ALB Listener Rule을 사용하여 URI 경로 기반 라우팅. 각 Target Group은 ECS 서비스(Fargate), Lambda, 또는 EC2 인스턴스 그룹으로 구성. ASG를 통해 서비스별 동적 확장. ALB 앞단에 AWS WAF를 배치하여 웹 공격 방어. 필요한 경우 API Gateway와 연계하여 인증/인가 처리.
- ALB + 경로 기반 라우팅(Path-based Routing). 각 URI 패턴(
결론: 지능형 문지기로서의 역할
로드 밸런싱과 API 게이트웨이는 단순한 트래픽 분산 도구를 넘어, 애플리케이션의 지능형 라우팅, 네트워크 최적화, 장애 복원력 확보, 보안 강화, 비용 절감까지 책임지는 현대 분산 시스템 아키텍처의 핵심 전략입니다.
글로벌 빅테크 기업처럼 고도로 복잡한 자체 솔루션을 직접 구현하기는 어렵겠지만, AWS ALB/NLB/API Gateway, Nginx, Envoy, 그리고 다양한 오픈소스 라이브러리들을 상황에 맞게 잘 조합하고 이해한다면, 우리도 충분히 견고하고 확장 가능한 시스템을 구축할 수 있습니다. 중요한 것은 각 기술의 본질을 이해하고, 우리 서비스의 특성에 맞는 최적의 설계를 고민하는 자세일 것입니다.
