매일매일 블로그
1.Spring Data JPA — isNew()로 “새로운 엔티티”를 구분하는 방식 완전 정리

Spring Data JPA가 save() 호출 한 번으로 INSERT(persist)와 UPDATE(merge)를 자동으로 구분해 주는 비밀은 JpaEntityInformation코드를 뜯어보며 동작 방식을 이해하고, 직접 ID를 할당할 때 주의해야 할 점까지 정리했
2. Spring Boot × JPA ddl-auto 완벽 가이드
개념 · 옵션별 동작 · 실전 사용 시나리오 · 주의할 점 총정리 Spring Data JPA(Hibernate)가 애플리케이션 시작/종료 시점에 데이터베이스 스키마를 어떻게 다룰지 결정하는 설정이 spring.jpa.hibernate.ddl-auto 입니다. app
3.논블록킹 vs 비동기 vs 멀티스레딩 ― 헷갈리는 세 용어 한방에 정리하기
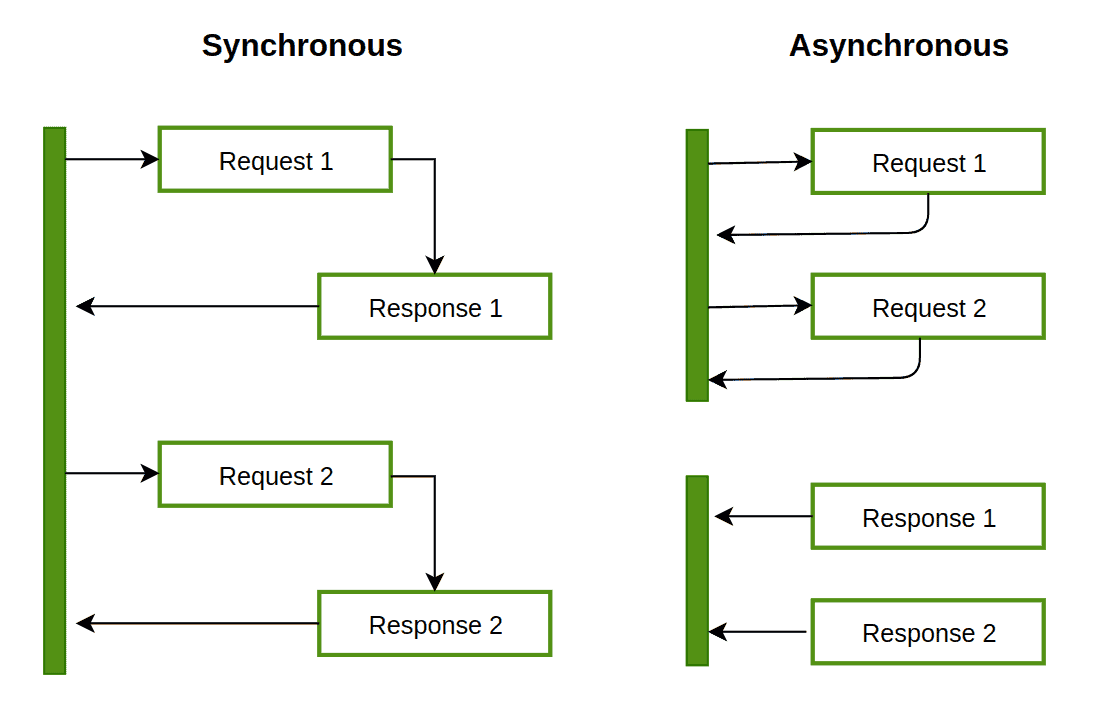
백엔드 성능 최적화 자료를 보다 보면 논블록킹(Non-blocking), 비동기(Asynchronous), 멀티스레딩(Multi-threading) 이 뒤섞여 쓰이는 경우가 많습니다. 하지만 세 용어는 초점이 서로 다릅니다. 개념을 명확히 잡아 두면 아키텍처 선택과 성
4.Transactional Outbox vs SAGA Pattern
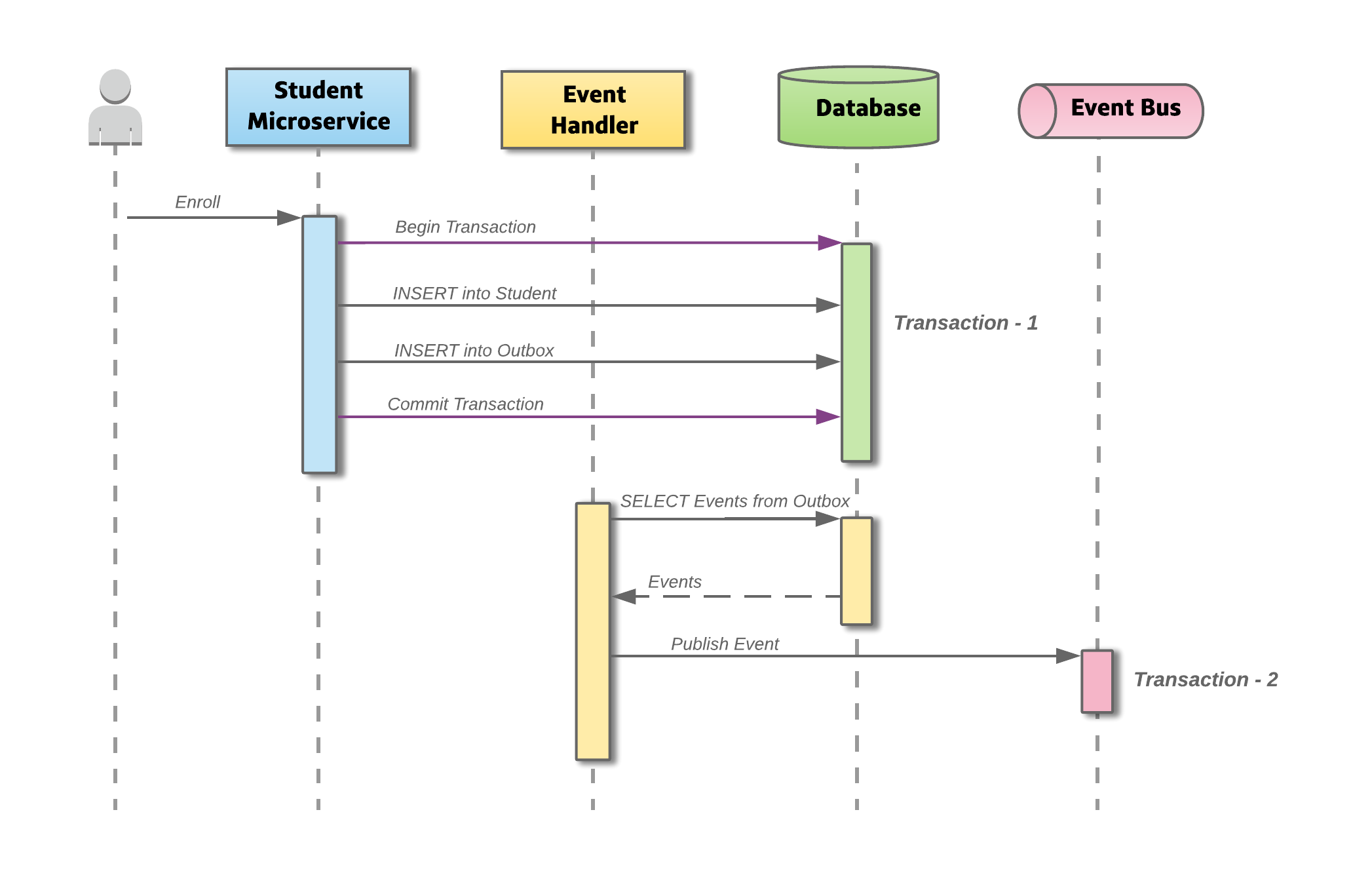
대규모 MSA에서 데이터 일관성은 생존 문제입니다. 전통 2‑PC(분산 트랜잭션)는 느리고, 장애 전파 위험도 큽니다.그래서 등장한 두 주인공이 Transactional Outbox와 SAGA입니다. 이름은 많이 들었어도 “어느 상황에서 누구를 써야 하지?” 헷갈린다면
5.Offset vs. Cursor(Keyset) 페이지네이션 완벽 분석: 성능 병목의 원인과 해결책
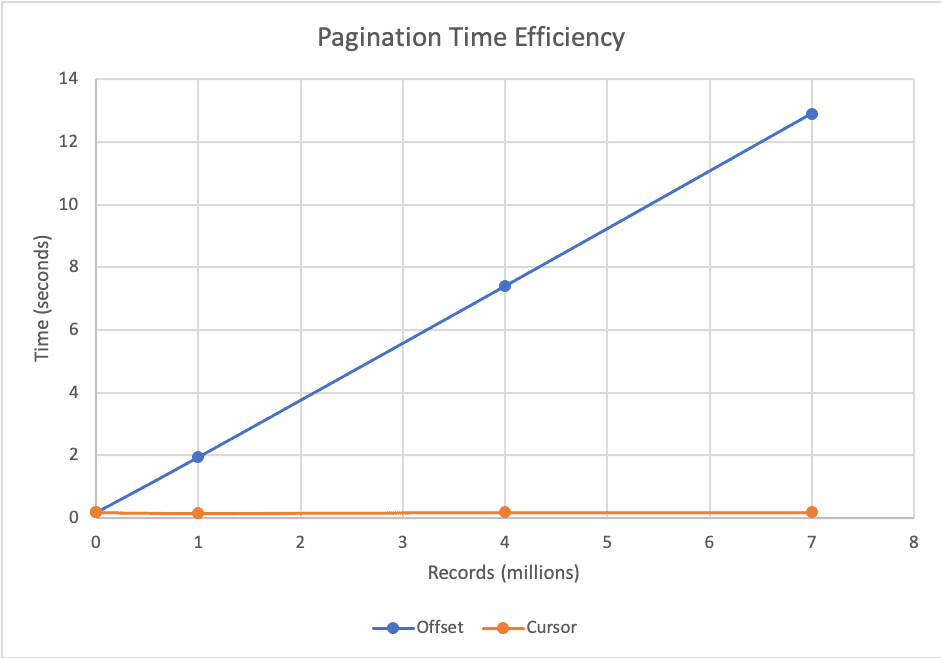
대규모 데이터를 사용자에게 효과적으로 보여주는 것은 모든 웹/앱 서비스의 중요한 과제입니다. 이때 가장 흔히 사용되는 전략이 바로 페이지네이션(Pagination) 인데요, 대표적으로 Offset 기반과 Cursor(Keyset) 기반 방식이 있습니다.많은 개발자분들이
6.RabbitMQ vs. Kafka: Dead Letter Queue(DLQ), 누가 더 편할까? 🤔 핵심 차이 완전 정복
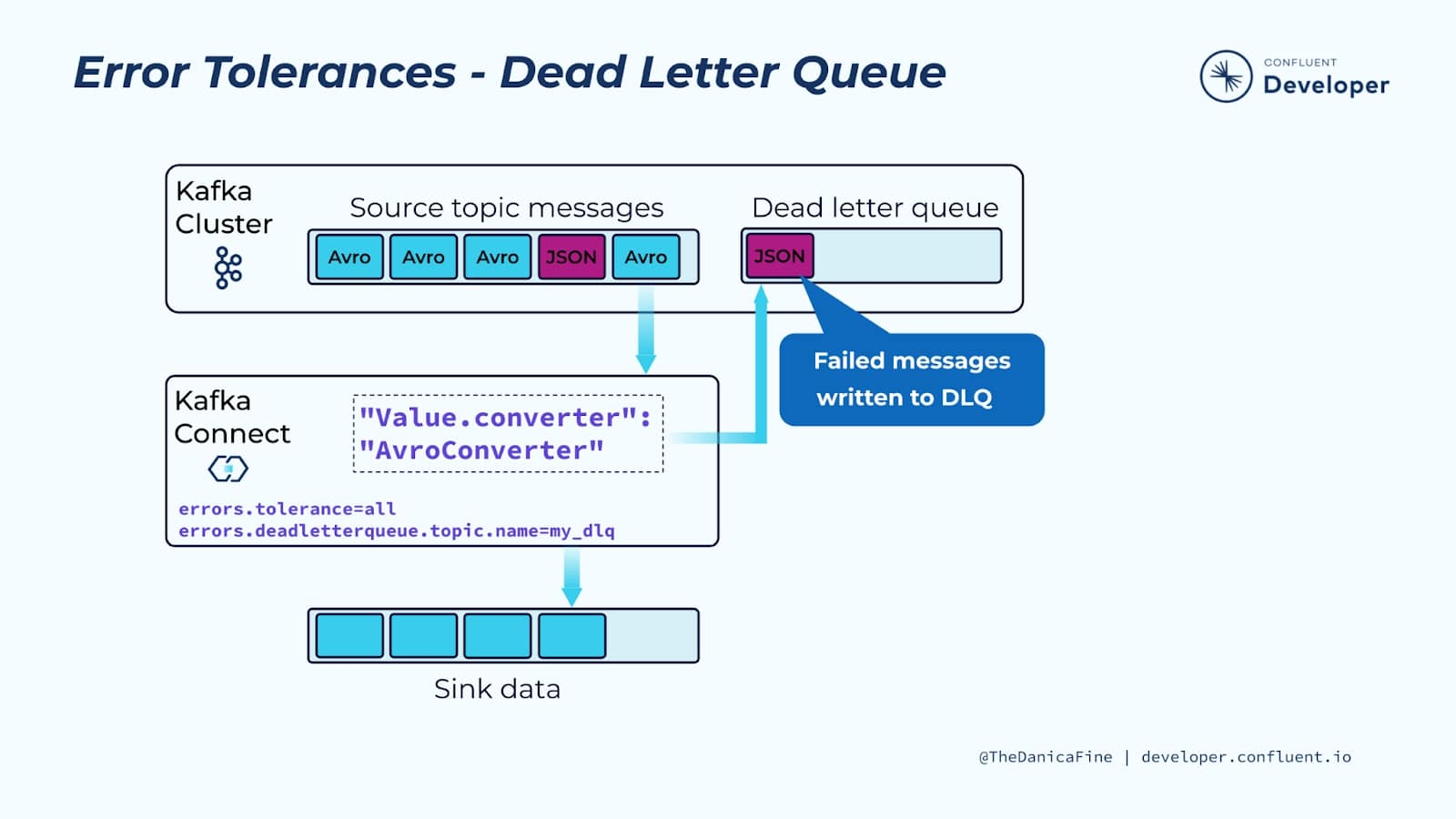
메시지 큐 시스템을 운영하다 보면 다양한 이유로 메시지 처리에 실패하는 경우가 발생합니다. 네트워크 오류, 잘못된 데이터 형식, 일시적인 서비스 장애 등 원인은 다양하죠. 이때 실패한 메시지를 무작정 버리거나 무한 재시도 루프에 빠뜨리는 대신, 안전하게 별도 공간으로
7.DB 성능의 심장, 인덱스 파헤치기
개발자라면 한 번쯤 마주했을 법한 경고, "해당 쿼리가 풀스캔을 타고 있습니다!" 이 메시지가 나타난다면, 우리 데이터베이스는 이미 상당한 부하를 견디고 있을 가능성이 높습니다.사실, 인덱스는 데이터베이스 성능 논의에서 가장 먼저 다뤄야 할 핵심 주제입니다. 매우 기본
8.쿠버네티스 알아보기
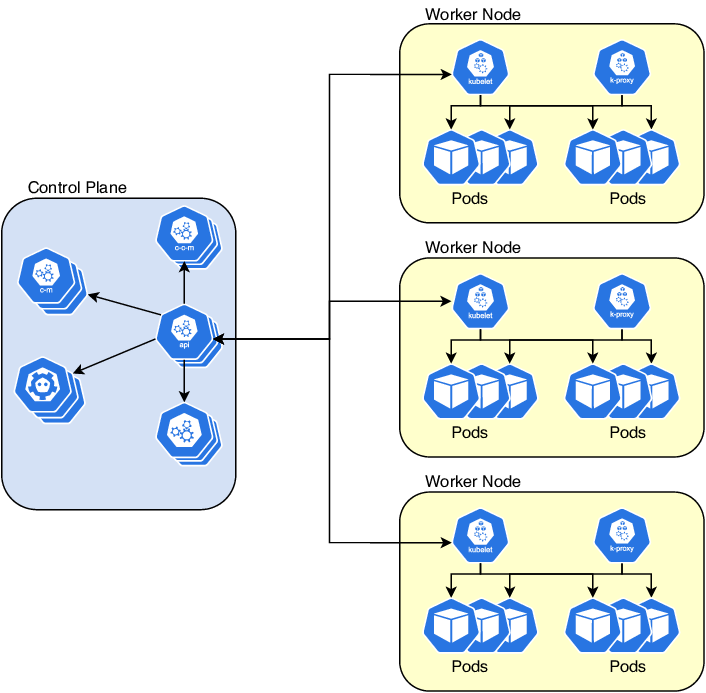
"배포했는데 왜 안 되죠?""스케일링이 이상해요!""이 파드는 왜 자꾸 죽는 거죠…?"쿠버네티스를 처음 만난 개발자라면 누구나 한 번쯤 이런 혼란과 마주하게 됩니다. YAML 파일 몇 줄로 복잡한 애플리케이션을 배포하는 과정이 마치 마법처럼 느껴지기도 하죠. 하지만 이
9.Maven vs Gradle: 빌드 자동화 도구 완벽 마스터 가이드
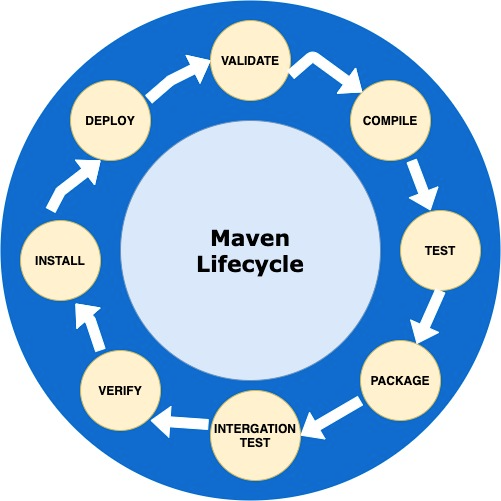
Java 및 Spring 기반 프로젝트를 개발할 때, 프로젝트의 빌드, 의존성 관리, 배포 등의 복잡한 과정을 자동화하는 빌드 도구는 선택이 아닌 필수입니다. 이 분야에서 가장 대표적인 두 거목, 바로 Maven과 Gradle인데요. 각각의 특징과 장단점, 그리고 어떤
10.ETL vs. CDC: 데이터 파이프라인 구축의 핵심 전략, 완벽 비교 분석!
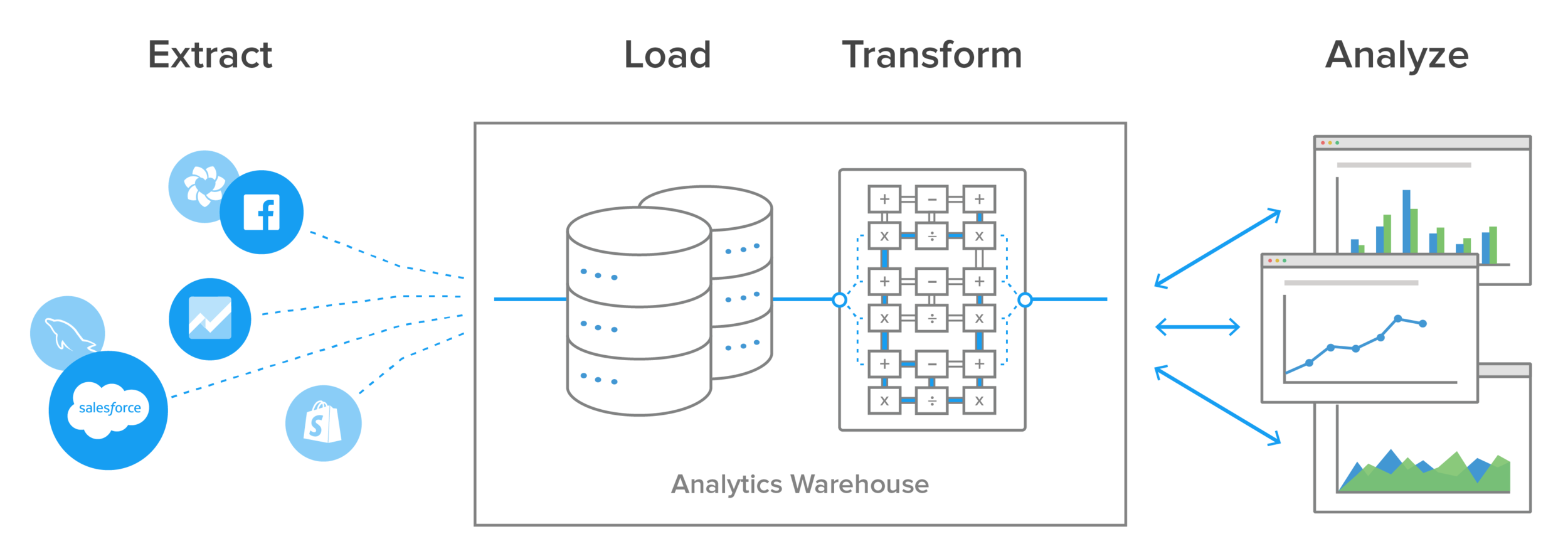
데이터가 폭발적으로 증가하는 시대, 데이터를 효과적으로 수집하고, 가공하고, 필요한 곳으로 옮기는 것은 모든 IT 시스템의 핵심 과제입니다. 이때 자주 등장하는 두 가지 중요한 개념이 바로 ETL(Extract, Transform, Load)과 CDC(Change Da
11.백엔드 개발자를 위한 필수 지식: 로그와 메트릭, 그리고 효과적인 로깅 전략
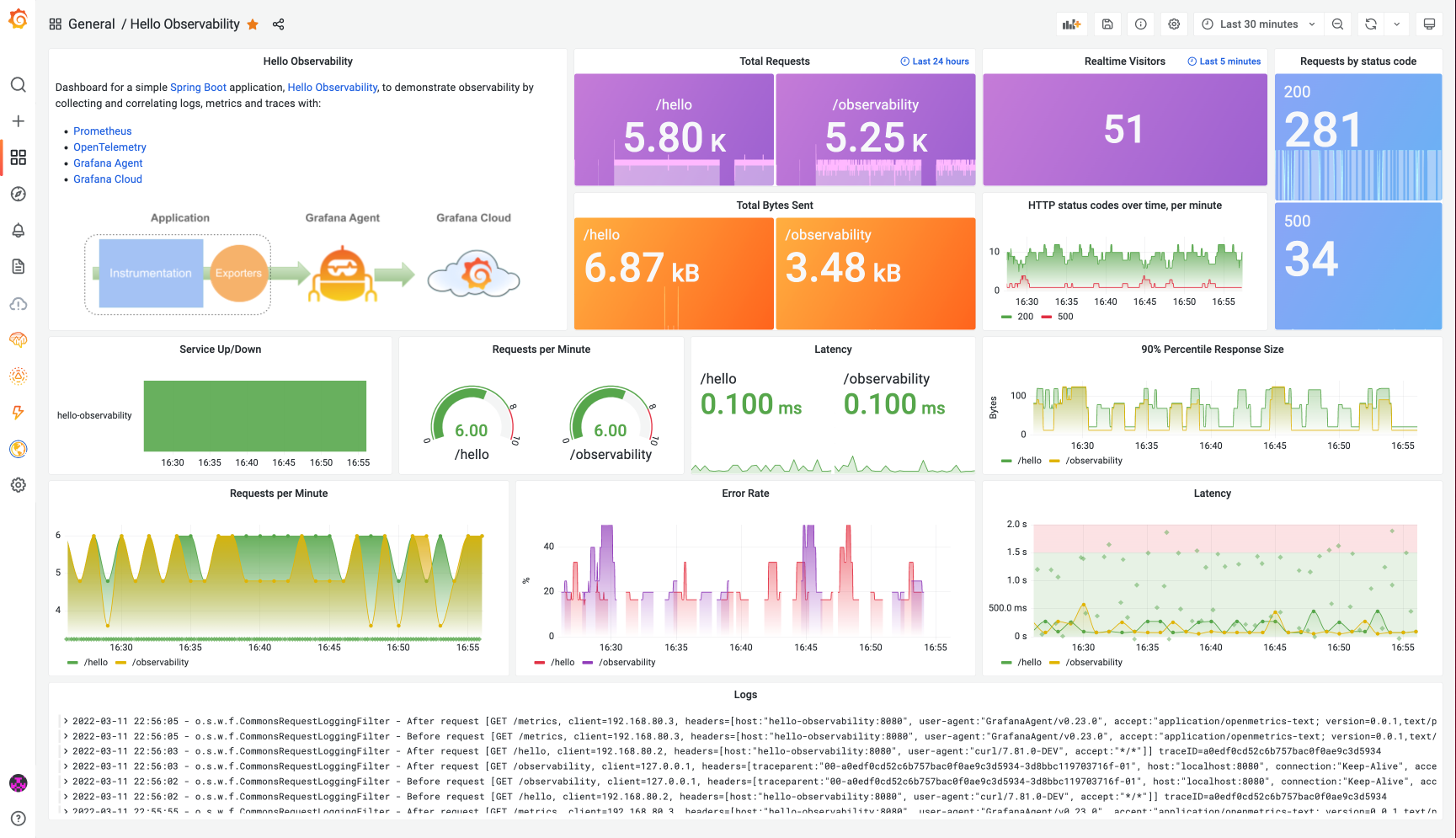
백엔드 서비스를 개발하고 운영하는 과정에서 시스템의 상태를 정확히 파악하고, 문제가 발생했을 때 신속하게 원인을 찾아 해결하는 능력은 매우 중요합니다. 이때 가장 기본적이면서도 강력한 도구가 바로 로그(Log)와 메트릭(Metric)입니다. 이 두 가지를 효과적으로 수
12.외부 서비스 장애, 내 서비스까지 마비될 순 없다! 장애 전파 막는 백엔드 생존 전략
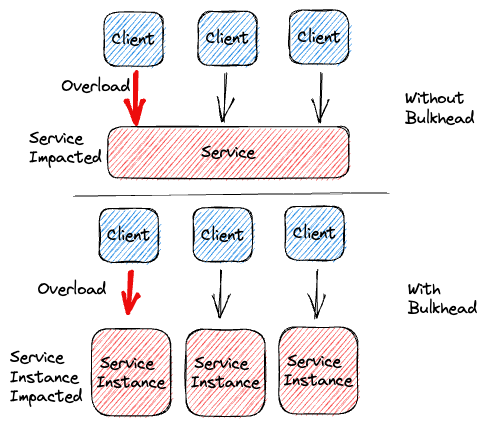
백엔드 시스템을 개발하다 보면 필연적으로 외부 서비스와 연동하게 됩니다. 그런데 만약 우리가 의존하는 외부 서비스가 갑자기 느려지거나 장애가 발생한다면 어떻게 될까요? 동기 방식으로 호출하는 경우, 외부 서비스의 문제는 고스란히 우리 서비스의 성능 저하와 장애로 이어질
13.DBMS 완전 정복 (1) : 데이터베이스, 어디까지 알고 계신가요? OLTP부터 Elasticsearch, 공간 DB까지 완전 정복
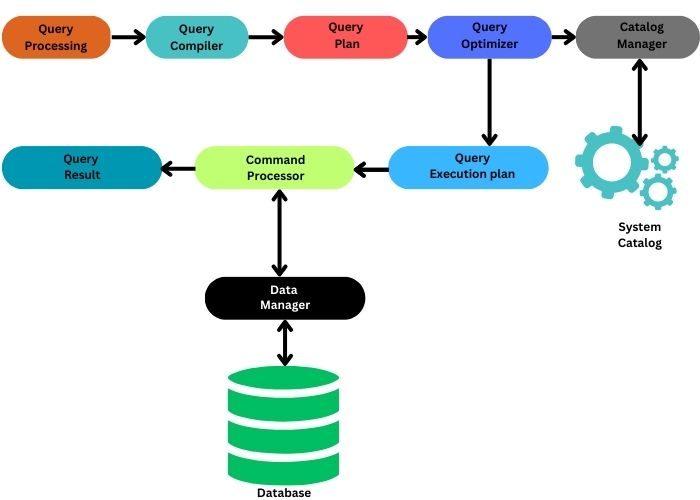
데이터베이스(Database)는 현대 애플리케이션의 심장과도 같습니다. 단순히 데이터를 저장하는 것을 넘어, 신뢰성 있는 데이터 관리, 컴포넌트 간 데이터 공유, 그리고 비즈니스 의사결정을 위한 핵심 정보를 제공하는 중추적인 역할을 담당합니다. 하지만 "데이터베이스"라
14.DBMS 완전 정복 (2): Hadoop, Cassandra, 시계열 DB 파헤치기 & DB 선택의 기술
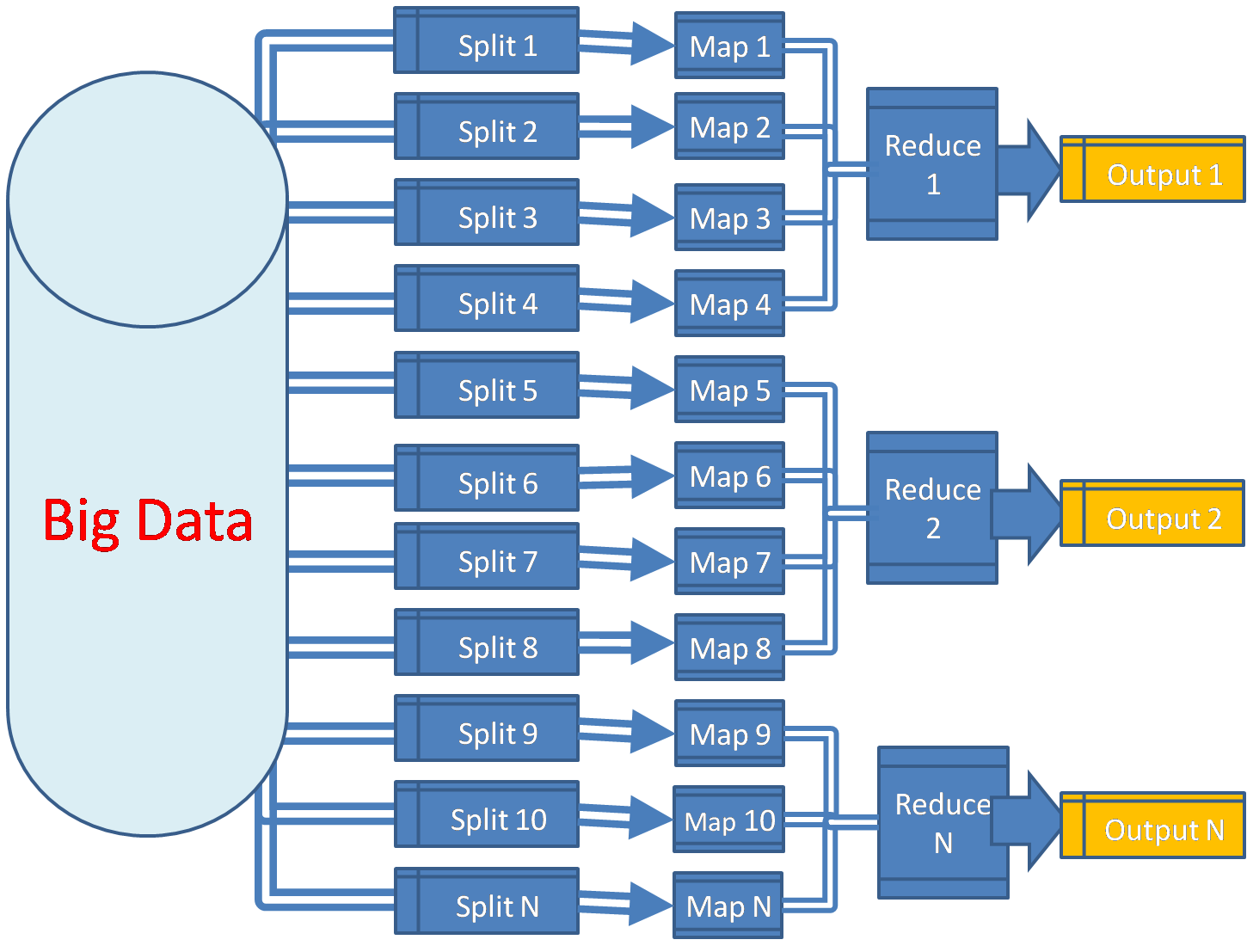
데이터베이스의 기본 역할, 주요 카테고리(OLTP, OLAP), DBMS 아키텍처, 그리고 관계형 DB와 다양한 NoSQL 유형(Key-Value, Document, Column-Family, Graph), Elasticsearch, 지리정보 DB까지 살펴보았습니다.이
15.DBA의 SOS! "이 쿼리, 인덱스 좀 달아주세요!" - 실행 계획(EXPLAIN) 완벽 분석 가이드
"오늘도 DBA에게 연락이 왔어요. '이 쿼리, 인덱스가 시급합니다!'"개발자라면 한 번쯤 경험해 봤을 법한 상황이죠. 대체 DBA는 무엇을 보고 이런 요청을 하는 걸까요? 그 비밀은 바로 SQL 쿼리 실행 계획(Execution Plan)에 숨어 있습니다. 오늘은 이
16.서킷 브레이커 적용기: 장애 전파, 너는 이제 그만!
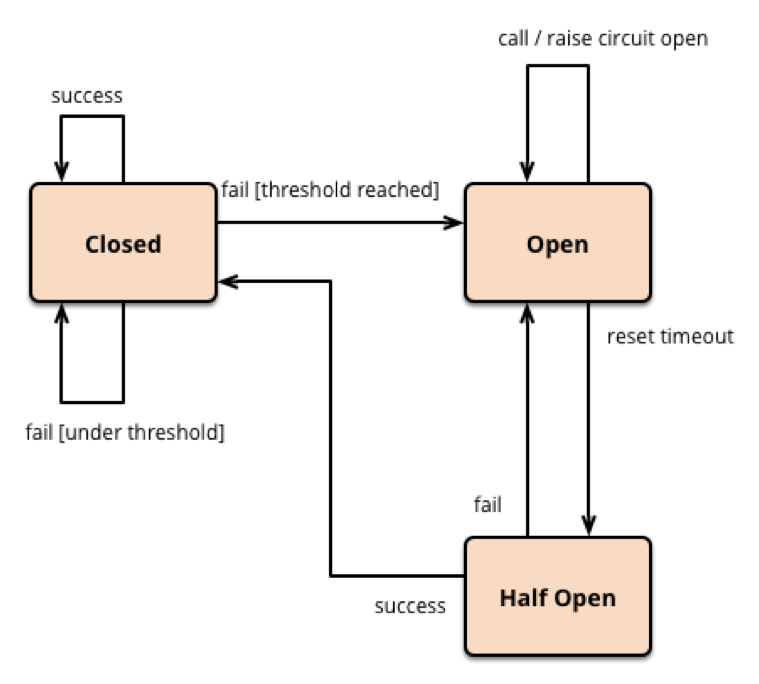
서비스가 확장되고 여러 기능이 모듈화되면서, 우리 애플리케이션은 점점 더 많은 외부 서비스 또는 내부 공통 플랫폼과 통신하게 됩니다. 이때 한 가지 중요한 고민이 생깁니다. "만약 내가 호출하는 저 서비스가 갑자기 느려지거나 장애가 나면, 내 서비스는 괜찮을까?"안타깝
17."JOIN에 대해 설명해주세요" 완벽 대비 가이드 (논리적 & 물리적 조인 파헤치기)
면접장에서 "JOIN에 대해 설명해주세요."라는 질문을 받는다면, 어떤 내용부터 떠오르시나요? INNER JOIN? OUTER JOIN? 아니면 조금 더 깊이 들어가서 Nested Loop Join이나 Hash Join 같은 용어들일까요?데이터베이스에서 여러 테이블의
18.API 게이트웨이 & 로드 밸런서: 마이크로서비스 시대의 문지기들, 제대로 알고 쓰자!
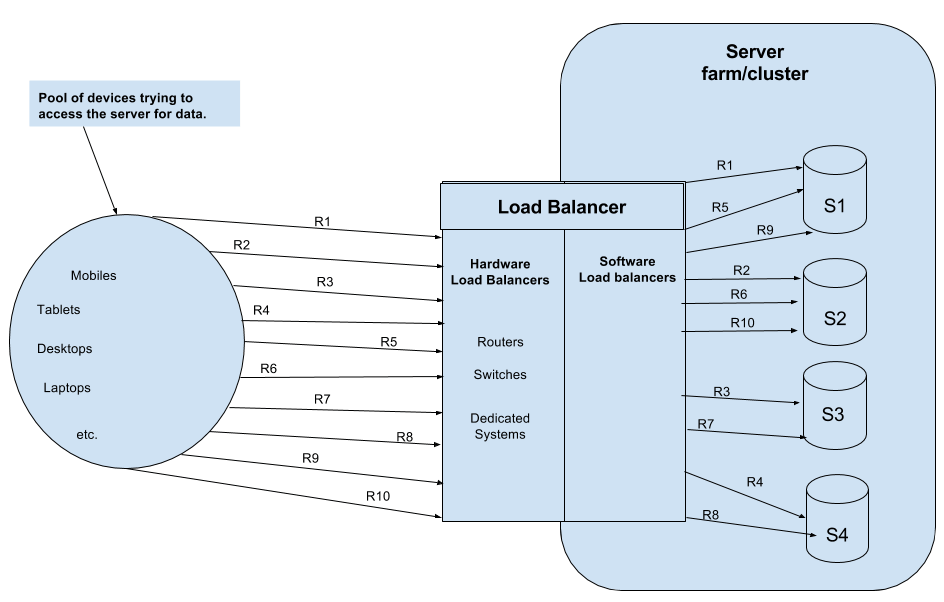
마이크로서비스 아키텍처(MSA)가 대세로 자리 잡으면서, 수많은 서비스 간의 트래픽을 효율적으로 관리하고, 외부 요청을 안전하게 처리하는 기술의 중요성은 더욱 커졌습니다. 이때 등장하는 핵심 컴포넌트가 바로 API 게이트웨이(API Gateway)와 로드 밸런서(Loa
19.NoSQL 완전 정복: RDBMS를 넘어선 데이터 저장의 새로운 패러다임
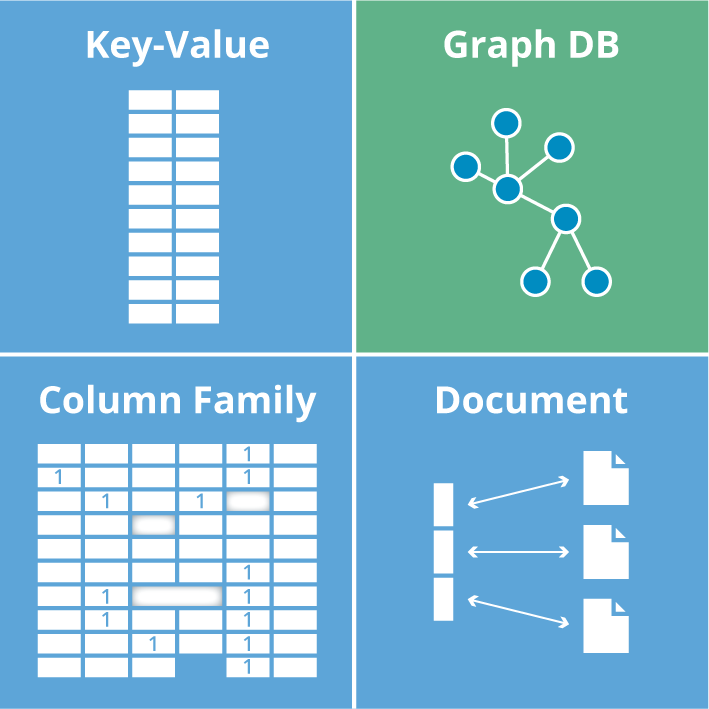
"데이터가 너무 많고, 너무 빠르고, 너무 다양해요!"오늘날 우리가 마주하는 데이터는 과거와는 비교할 수 없을 만큼 방대한 양, 빠른 속도, 그리고 다양한 구조를 가지고 있습니다. 전통적인 관계형 데이터베이스(RDBMS)는 정형 데이터를 다루는 데는 여전히 강력하지만,
20.OpenSearch 완전 정복: Analyzer부터 클러스터, 한국어 처리(Nori)까지 샅샅이 파헤치기
데이터베이스는 몇 가지나 알고 계신가요?" 이 질문에 MySQL, Oracle, MongoDB, Redis 등을 떠올리셨다면, 오늘 또 하나의 강력한 도구를 리스트에 추가할 시간입니다. 바로 검색 기능을 갖춘 NoSQL 데이터베이스이자 검색 엔진인 OpenSearch입
21.DBMS 완전 정복 (3) : 메모리 vs. 디스크 DBMS: 성능, 내구성, 비용의 줄다리기 & 현명한 선택 가이드
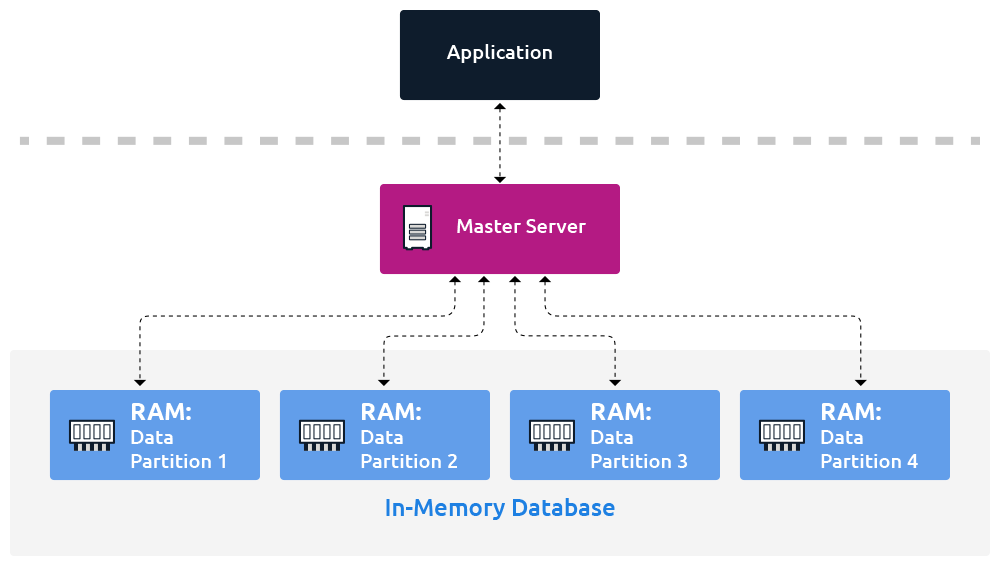
데이터베이스를 선택하거나 설계할 때, 우리는 종종 "데이터를 어디에, 어떻게 저장할 것인가?"라는 근본적인 질문에 직면합니다. 이때 가장 중요한 결정 중 하나가 바로 메모리 기반 DBMS(In-Memory DBMS)와 디스크 기반 DBMS(Disk-Based DBMS)
22.DBMS 완전 정복 (4) : 빅테크는 어떻게 수억 명의 트래픽을 감당할까? 쿼리 최적화 & 스키마 설계 실전 전략
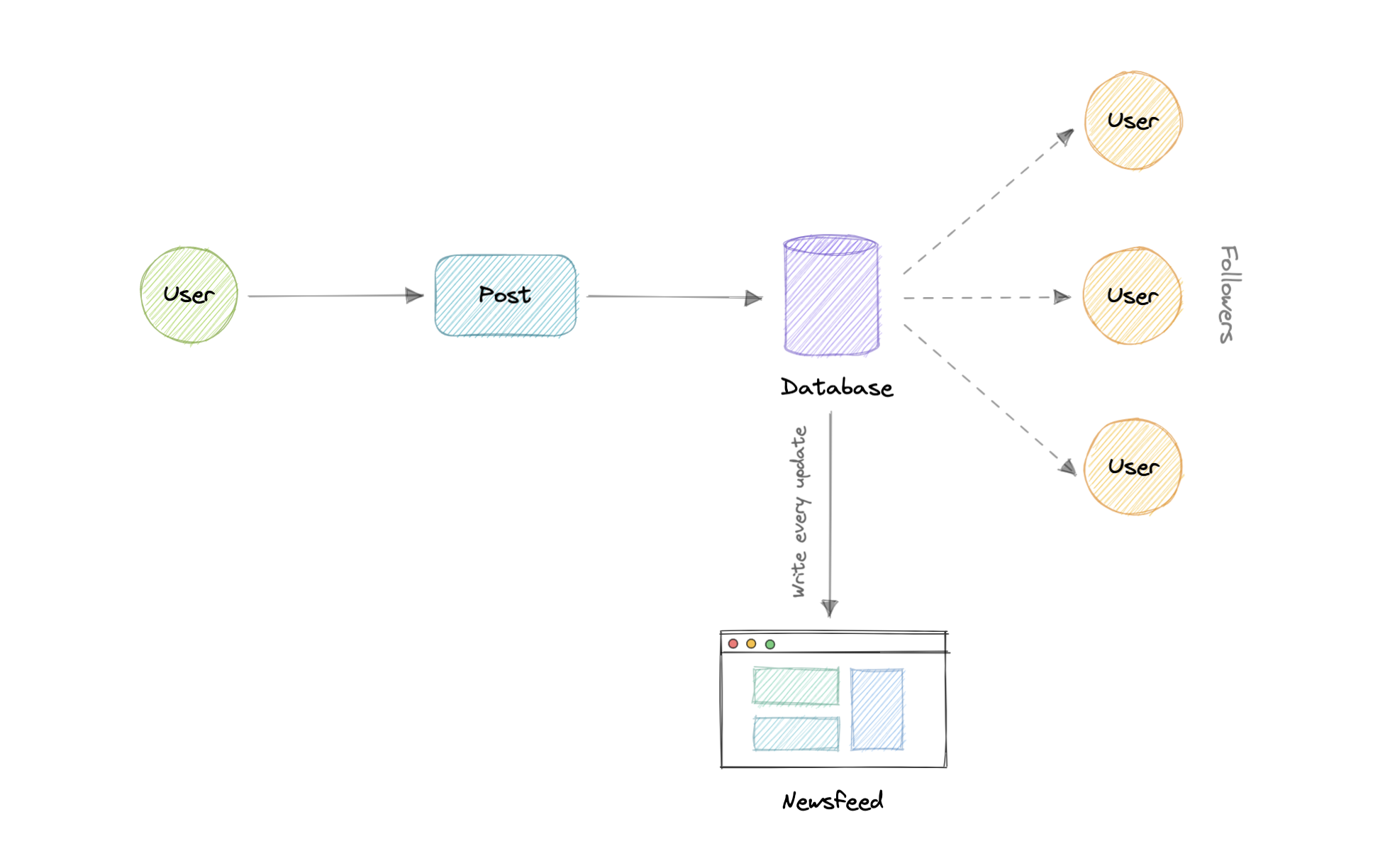
"이 쿼리, 왜 이렇게 느릴까요?", "데이터가 너무 많아서 DB가 버티질 못해요!", "SQL 써야 할까요, NoSQL 써야 할까요?"개발자라면 누구나 한 번쯤 마주하게 되는 고민들입니다. 특히 X(구 트위터), 인스타그램, 왓츠앱, 유튜브처럼 전 세계 수억 명의 사
23.프록시(Proxy) 완전 정복: 왜 대규모 서비스는 직접 연결하지 않을까요?
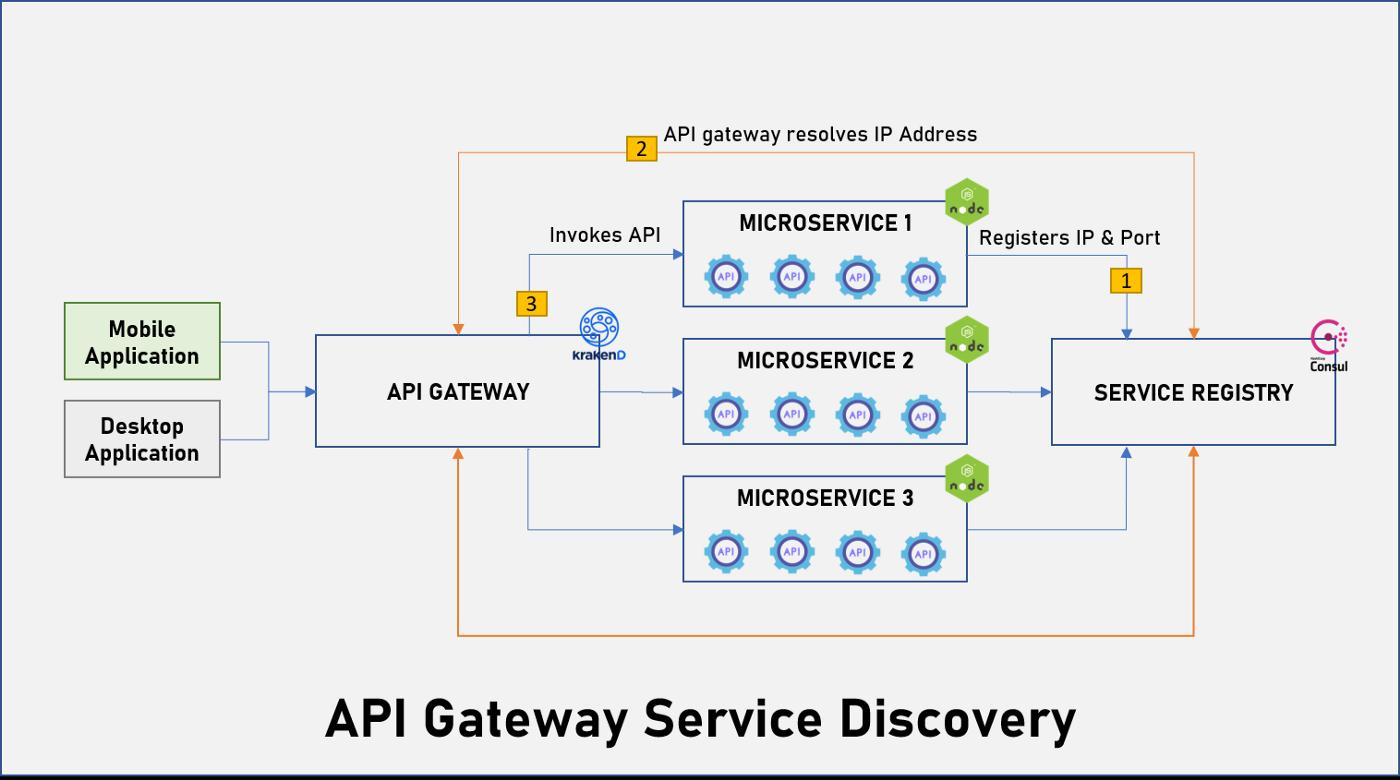
"오늘도 당신은 알게 모르게 수십, 수백 번 프록시를 통과했을 겁니다."넷플릭스, 우버, 아마존과 같은 글로벌 테크 기업들의 시스템 아키텍처를 살펴보면 공통적으로 발견되는 핵심 컴포넌트가 있습니다. 바로 프록시(Proxy)입니다. 단순한 트래픽 중계기라고 하기엔, 이들
24."분명 로직은 맞는데 데이터가 꼬여요!" - 실무에서 만나는 DB 격리 수준(Isolation Level) 이야기
"DB 격리 수준... 그거 전공 시간에 배웠던 것 같은데... READ COMMITTED랑 REPEATABLE READ... 뭐 그런 거였나?"많은 개발자분들이 데이터베이스 트랜잭션 격리 수준(Isolation Level)에 대해 이론적으로는 알고 있지만, 막상 실제
25.대규모 검색을 위한 색인 파이프라인 개선기: 안정성과 생산성을 잡다
다양한 서비스가 결합된 대규모 플랫폼에서는 사용자들이 원하는 정보를 빠르고 정확하게 찾을 수 있도록 지원하는 검색 기능이 매우 중요합니다. 저희 팀은 여러 서비스들이 공통으로 사용할 수 있는 검색 플랫폼을 만들고, 다양한 서비스의 검색 기능을 안정적으로 지원하는 역할을
26.유저의 소리를 더 빠르게 듣는 법: 신규 앱 리뷰 수신 시스템 개발기
"배포했는데 왜 안 돼요?", "이 기능, 너무 불편해요!"고객의 목소리는 서비스를 성장시키는 가장 중요한 자양분입니다. 특히 B2C 서비스를 운영한다면, 사용자의 피드백, 그중에서도 앱 스토어 리뷰에 담긴 생생한 목소리를 얼마나 빠르고 정확하게 듣느냐가 서비스의 품질
27.AI와 글쟁이의 동행: 코드만 주시면 API 레퍼런스 써 드려요
"기술 문서는 늘 부족합니다. 특히 '좋은' 기술 문서는 더더욱 그렇죠."테크니컬 라이터로서, 또 문서 엔지니어로서 항상 마주하는 현실입니다. 모든 개발 프로젝트의 문서를 소수의 전문가가 전부 책임지기에는 수가 턱없이 부족합니다. "개발자 글쓰기 교육"으로 그 간극을
28.StarRocks 파헤치기: 고성능 OLAP 엔진의 도입부터 성능 최적화까지
컴퓨팅 성능의 발전은 데이터 처리 패러다임의 변화를 이끌고 있습니다. 전통적인 ETL(Extract, Transform, Load) 방식에서, 데이터를 먼저 적재한 후 필요에 따라 변환하는 ELT(Extract, Load, Transform) 방식으로의 전환이 가속화되
29.제휴사 테스트 서버가 또 말썽인가요? 정밀 제어 가능한 Mock 서버 개발기
"제휴사 개발 서버가 또 다운됐어요.", "이 케이스는 테스트 데이터가 없어서 QA를 못하고 있어요.", "테스트 중인데 유효한 응답이 안 와요."외부 기관, 특히 금융사나 파트너사와 연동하여 서비스를 개발하는 백엔드 개발자라면 누구나 한 번쯤 겪어봤을 법한 상황입니다
30.Zod 완전 정복: 타입 안전성과 런타임 검증, 두 마리 토끼를 잡는 법
"TypeScript를 쓰는데 왜 런타임 에러가 터지죠?", "API 응답 데이터 구조가 달라서 서비스가 멈췄어요!"TypeScript는 컴파일 시점에 타입 오류를 잡아주어 코드의 안정성을 크게 높여줍니다. 하지만 TypeScript의 타입 시스템은 컴파일 시간에만 유
31.에러율 0%에 도전! MSA 환경에서 Enum을 다루는 안전한 전략
최근 많은 서비스가 빠른 개발 속도와 유연한 확장을 위해 MSA(Microservice Architecture)를 채택하고 있습니다. 하지만 "은탄환은 없다"는 말처럼, MSA는 그 장점만큼이나 다양한 기술적 복잡성을 수반합니다. 그중에서도 많은 개발자들이 간과하기 쉽
32.프로젝트에 Supabase와 PostGIS, Supabase Auth와 Middleware 적용하기
"내 주변 맛집 찾기", "가장 가까운 편의점 안내", "반경 5km 내 배달 가능한 가게 목록"…오늘날 많은 서비스의 핵심에는 위치 기반 기능이 자리 잡고 있습니다. 하지만 단순히 데이터베이스에 위도(latitude), 경도(longitude) 컬럼을 만들어 모든 데
33.Next.js vs. Remix: React 메타-프레임워크, 무엇을 선택할 것인가?
React는 UI를 만들기 위한 강력한 라이브러리이지만, 그 자체만으로는 완전한 웹 애플리케이션을 만들 수 없습니다. 라우팅, 데이터 로딩, 서버 사이드 렌더링(SSR), 검색 엔진 최적화(SEO), 빌드 및 배포 최적화 등 실제 프로덕션 환경에서 필요한 수많은 기능들
34.Redmine개념과 우리 팀에 딱 맞는 프로젝트 관리 툴 선택가이드
"어떤 툴을 써야 우리 팀 업무가 체계적으로 관리될까요?" > 프로젝트를 진행하는 팀이라면 누구나 한 번쯤 하게 되는 고민입니다. 수많은 업무, 버그 리포트, 요청 사항들을 효율적으로 관리하고 팀원들과 원활하게 협업하기 위해선 좋은 도구가 필수적이죠. 이 분야에서 가장
35.배차 정확도를 높이는 실거리 시스템 구축기: OSRM, Kafka, 그리고 Redis 활용 사례
배달 플랫폼의 핵심인 배차 시스템은 고객에게 음식을 빠르고 효율적으로 전달하기 위해, 수많은 주문과 라이더 사이에서 최적의 조합을 찾아내는 복잡한 시스템입니다. 이 최적화 과정에서 '거리'는 매우 중요한 변수입니다.이번 글에서는 배차에 활용되는 거리를 단순한 직선거리에
36.크롤러에 잠들지 않는 심장을 달다: 24/7 무인 운영 자동화 및 성능 최적화 분투기
안녕하세요! 웹 크롤링 프로젝트를 진행하다 보면, 개발자는 종종 이런 고민에 빠지게 됩니다."내 크롤러는 왜 자꾸 한밤중에 죽어있을까?""수집한 데이터에 왜 이렇게 잘못된 정보가 많지?""이걸 언제까지 매일 손으로 돌려야 하지?"단순히 데이터를 수집하는 크롤러는 웹사이
37.Spring Boot와 FCM으로 푸시 알림 서비스 구축하기 (A to Z 가이드)
안녕하세요! 이번 글에서는 Spring Boot와 Firebase Cloud Messaging(FCM)을 연동하여, 안드로이드, iOS, 웹 애플리케이션에 푸시 알림을 보내는 서비스의 전체 구현 과정을 A to Z로 상세하게 다뤄보겠습니다. > FCM의 기본 개념부터
38.Spring Boot로 구축하는 회복력 있는(Resilient) 결제 시스템: 카드 결제부터 정기 결제, 장애 대응까지
"결제는 성공했는데, 유저는 실패했다고 느껴요." "네트워크 오류로 중복 결제가 발생했어요." "PG사 장애 때문에 우리 서비스까지 멈췄어요." > 결제 시스템을 개발하다 보면 마주하게 되는 끔찍한 시나리오들입니다. 결제는 단순히 돈을 주고받는 기술적인 행위를 넘어,
39.React로 구현하는 안전하고 현대적인 결제 프론트엔드 시스템
아무리 견고하고 회복력 있는 백엔드를 구축했다 하더라도, 사용자가 마주하는 것은 오직 브라우저 화면에 렌더링된 프론트엔드뿐입니다. 만약 결제 버튼이 버벅거리거나, 로딩 상태를 알 수 없거나, 결제 후 결과가 명확하지 않다면 사용자는 불안감을 느끼고 서비스에 대한 신뢰를
40.MongoDB, Redis, Couchbase: NoSQL 아키텍처, 성능, 활용 사례 심층 비교 분석
현대 디지털 경제는 전례 없는 규모의 데이터와 사용자 상호작용을 기반으로 합니다. 이러한 환경에서 웹, 모바일, 사물 인터넷(IoT) 애플리케이션은 비즈니스의 핵심 동력으로 자리 잡았으며, 이들의 성공은 데이터 관리 기술의 역량에 크게 좌우됩니다. 전통적인 관계형 데이
41.Kafka 프로덕션 운영 가이드: 메타데이터, 프로듀서, 압축의 비밀
이번 글에서는 Kafka 클러스터의 '지도' 역할을 하는 메타데이터(Metadata)가 어떻게 교환되고, 왜 metadata.max.age.ms 설정이 중요한지부터 시작하여, 데이터 전송의 주체인 프로듀서(Producer)가 어떻게 동작하고 최적화할 수 있는지, 그리고
42.React로 구현하는 똑똑하고 기민한 프론트엔드: 상태 관리, 훅, 그리고 UX의 모든 것
안녕하세요! 이번 글에서는 사용자가 직접 마주하는 프론트엔드 화면이 어떻게 똑똑하고 기민하게 반응하는지, 그 내부 구조를 깊이 있게 파헤쳐보려 합니다. > 복잡해질 수 있는 데이터 필터링, 사용자 위치 정보, 즐겨찾기 상태 등을 어떻게 가볍고 체계적으로 관리했는지, 그
43.단순한 CRUD를 넘어: 똑똑한 관리자 대시보드
"잘 만든 서비스 뒤에는 반드시 훌륭한 관리 도구가 있다." > 사용자가 만족하는 서비스를 만들기 위해 화려한 프론트엔드와 견고한 백엔드를 구축하는 것도 중요하지만, 서비스의 품질을 장기적으로 유지하고 발전시키는 힘은 결국 '운영'에서 나옵니다. 사용자의 문의에 신속하
44.데이터 파이프라인의 마에스트로, 아파치 에어플로우(Airflow) 완전 정복
안녕하세요! 데이터 기반의 프로젝트를 진행하다 보면, 우리는 필연적으로 거대한 '작업의 교향곡'을 지휘해야 하는 과제에 직면하게 됩니다."A 작업이 끝나면 B를 실행하고, B가 성공하면 C와 D를 동시에 시작해 줘.""만약 새벽에 작업이 실패하면, 누가 좀 알아서 재시
45.실패를 지배하는 파일럿, 프리펙트(Prefect)는 어떻게 다른가
안녕하세요! 지난 글에서 우리는 데이터 파이프라인의 클래식, 아파치 에어플로우(Airflow)에 대해 깊이 알아보았습니다. 에어플로우는 의심할 여지 없이 강력하고 안정적인 도구이지만, 일부 개발자들은 그의 방식에 몇 가지 불편함을 느끼기 시작했습니다. > > "워크플로
46.데이터 자산의 설계자, 댁스터(Dagster)는 무엇을 꿈꾸는가
안녕하세요! 지난 글들에서 우리는 데이터 파이프라인의 클래식 '에어플로우'와 실패를 지배하는 파일럿 '프리펙트'를 만나보았습니다. 두 도구 모두 '어떻게 하면 작업을 성공적으로 실행할까?'라는 질문에 훌륭한 답을 제시했죠. > 하지만 데이터 엔지니어링의 세계는 또 다른
47.데이터 파이프라인 삼대장: Airflow vs Prefect vs Dagster, 당신의 팀에 맞는 지휘자는 누구인가?
안녕하세요! 지난 세 편의 글을 통해 우리는 데이터 파이프라인 세계의 세 거인, 아파치 에어플로우(Apache Airflow), 프리펙트(Prefect), 댁스터(Dagster)를 각각 깊이 있게 만나보았습니다. > 클래식의 거장, 에어플로우는 오케스트라의 지휘자처럼
48.벡터 데이터베이스 양대산맥: Milvus vs. Qdrant, 무엇이, 왜 다른가?
안녕하세요! AI 기술이 우리 삶 깊숙이 파고들면서, 개발자들은 새로운 종류의 질문에 답해야 하는 과제에 직면했습니다. > > "이 옷 사진과 비슷한 스타일의 상품을 어떻게 찾아주지?" > "사용자가 '여름 휴가 때 가기 좋은 곳'이라고 애매하게 물어봐도, 어떻게 '한
49.Elasticsearch vs. 벡터 DB: 내 서비스에 맞는 검색 엔진은?
안녕하세요! 벡터 데이터베이스 시리즈를 통해 우리는 Milvus와 Qdrant가 어떻게 AI 시대의 '의미 기반 검색'을 가능하게 하는지 알아보았습니다. 하지만 많은 개발자분들이 이런 질문을 던집니다. > > "어? Elasticsearch도 벡터 검색(kNN) 되잖아