메시지 큐 시스템을 운영하다 보면 다양한 이유로 메시지 처리에 실패하는 경우가 발생합니다. 네트워크 오류, 잘못된 데이터 형식, 일시적인 서비스 장애 등 원인은 다양하죠. 이때 실패한 메시지를 무작정 버리거나 무한 재시도 루프에 빠뜨리는 대신, 안전하게 별도 공간으로 옮겨 분석하고 후처리하는 메커니즘이 바로 Dead Letter Queue (DLQ) 입니다.
메시징 시스템의 양대 산맥인 RabbitMQ와 Kafka 모두 DLQ 개념을 활용하지만, 그 방식에는 결정적인 차이가 있습니다. 바로 RabbitMQ는 브로커 레벨에서 '자동' DLQ 기능을 제공하는 반면, Kafka는 '패턴'으로서 애플리케이션/프레임워크 레벨에서 구현해야 한다는 점입니다.
이번 글에서는 두 시스템의 DLQ 처리 방식을 비교하고, 어떤 상황에 어떤 방식이 더 유리할지 명확하게 짚어보겠습니다.
🐇 RabbitMQ: 설정 한 줄로 끝! 브로커가 책임지는 자동 Dead-Lettering
RabbitMQ는 Dead-Letter Exchange (DLX) 라는 개념을 통해 매우 강력하고 편리한 자동 DLQ 기능을 제공합니다. 말 그대로, 설정만 해두면 특정 조건에서 실패한 메시지를 브로커가 알아서 지정된 Exchange로 다시 발행(re-publish)해 줍니다.
언제 Dead-Letter 처리되나요? (브로커 자동 처리)
- 소비자가 메시지를 명시적으로 거부했을 때 (
basic.reject또는basic.nack호출 시requeue=false옵션 사용) - 메시지의 TTL(Time-To-Live)이 만료되었을 때
- 큐의 최대 길이(Max Length) 제한을 초과했을 때
- (Quorum Queue 사용 시) 설정된
delivery-limit을 초과하여 메시지 전달 시도가 실패했을 때
어떻게 설정하나요?
매우 간단합니다. 원본 큐를 선언할 때 arguments로 x-dead-letter-exchange (필수)와 x-dead-letter-routing-key (선택) 옵션을 지정하거나, Policy를 통해 설정할 수 있습니다.
// 예시: Spring AMQP를 사용한 큐 선언
@Bean
public Queue myQueue() {
return QueueBuilder.durable("my-queue")
.withArgument("x-dead-letter-exchange", "my-dlx") // 실패 시 보낼 DLX 지정
.withArgument("x-dead-letter-routing-key", "my-dlq-routing-key") // DLX에서 사용할 라우팅 키 (선택)
.build();
}
@Bean
public Queue myDLQ() {
return new Queue("my-dlq"); // Dead Letter 메시지가 최종 도착할 큐
}
@Bean
public DirectExchange myDLX() {
return new DirectExchange("my-dlx"); // Dead Letter Exchange
}
@Bean
public Binding dlqBinding() {
return BindingBuilder.bind(myDLQ()).to(myDLX()).with("my-dlq-routing-key"); // DLX와 DLQ 바인딩
}핵심 장점: 애플리케이션(Consumer) 코드에는 실패 시 reject/nack 처리 외에 DLQ 로직이 전혀 필요 없습니다. 브로커가 모든 Dead-Letter 처리를 책임지므로 구성이 매우 깔끔하고 관리가 용이합니다.
🐙 Kafka: '패턴'으로 승부! 애플리케이션/프레임워크 레벨의 Dead-Letter Topic
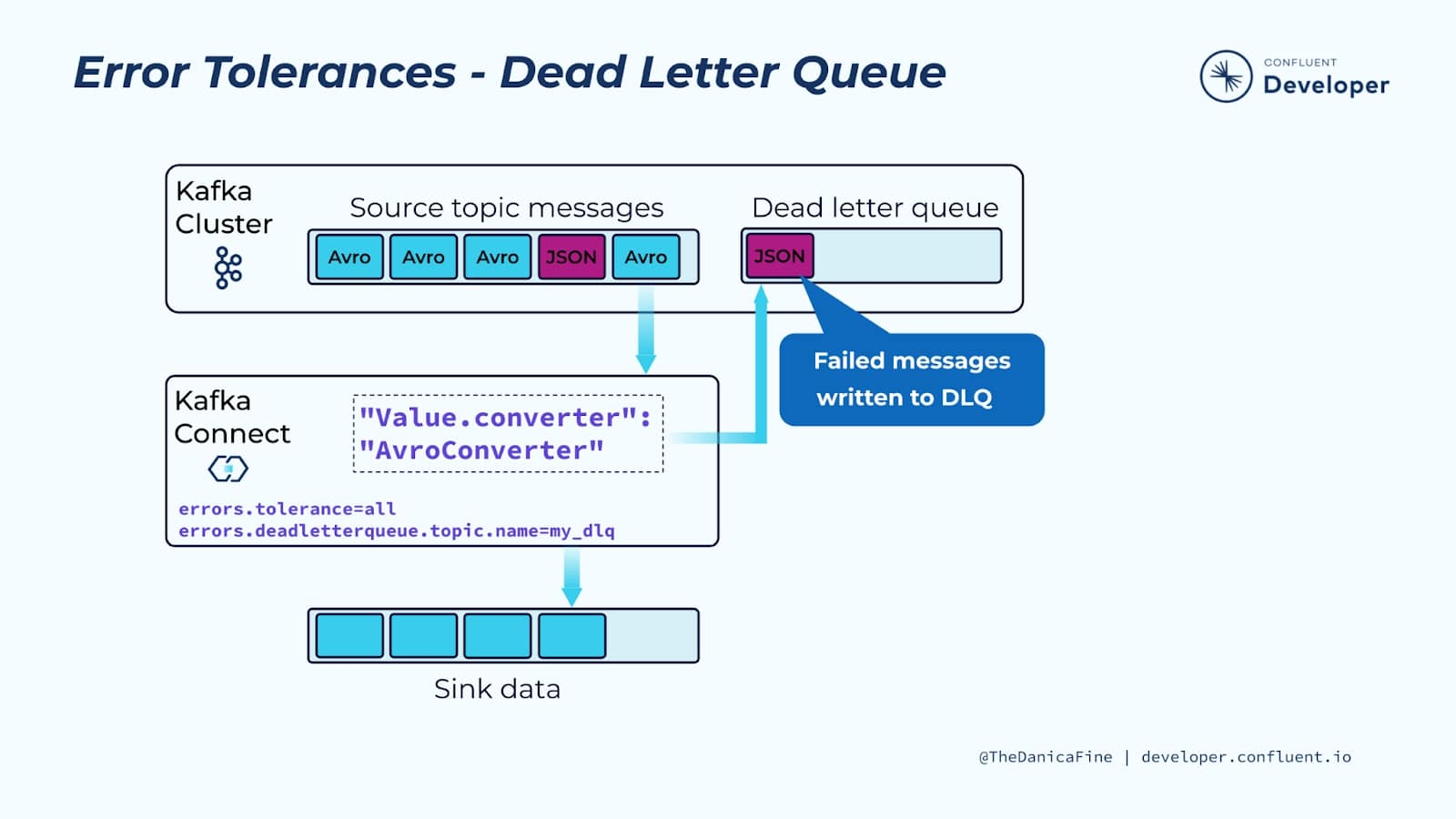
Kafka는 RabbitMQ와 달리 코어 브로커 레벨에 내장된 자동 DLQ 기능이 없습니다. 대신, Kafka 생태계에서는 "실패한 레코드를 별도의 Dead-Letter Topic으로 보내는 패턴" 을 주로 사용합니다. 즉, DLQ 로직 구현의 책임이 브로커가 아닌 애플리케이션(Consumer), Kafka Connect, Kafka Streams, 또는 사용하는 프레임워크에 있습니다.
| 구분 (구현 주체) | 현황 및 구현 방법 |
|---|---|
| Kafka Core Consumer (애플리케이션) | 브로커 차원의 자동 DLQ 기능 없음. ① Consumer 코드 내에서 try-catch 등으로 예외 처리 후, 실패한 레코드를 KafkaProducer를 이용해 직접 DLQ 토픽으로 발행(produce).② 또는 오류 로그만 남기고 해당 레코드의 오프셋을 커밋하여 건너뛰거나, 내부적으로 재시도 로직 구현 후 최종 실패 시 DLQ 토픽으로 전송. |
| Kafka Connect (커넥터) | Sink/Source 커넥터 설정에서 errors.deadletterqueue.topic.name 등의 옵션을 제공.➡️ 레코드 처리/변환 실패 시 자동으로 지정된 DLQ 토픽으로 레코드를 전송해 줍니다. 커넥터 레벨에서는 자동화된 DLQ 처리가 가능합니다. |
| Kafka Streams (스트림 처리 애플리케이션) | 표준 DLQ 기능은 아직 개발 중(KIP-1034). 현재는 DeserializationExceptionHandler나 ProcessExceptionHandler 인터페이스를 구현하여, 예외 발생 시 DLQ 토픽으로 레코드를 라우팅하는 방식으로 직접 구현하는 것이 일반적입니다. |
| Spring Kafka, Quarkus 등 (프레임워크) | 프레임워크 레벨에서 재시도(Retry) + DLQ 전송 기능을 추상화하여 제공합니다. ➡️ Spring Kafka의 @RetryableTopic, DefaultErrorHandler 등을 사용하면 어노테이션/설정 기반으로 간편하게 재시도 및 DLQ 토픽 전송 로직을 구성할 수 있습니다. |
핵심: Kafka에서 DLQ를 사용하지 못하는 것은 아니지만, "브로커가 알아서 해준다"는 개념이 아닙니다. 어떤 방식으로든 "실패 시 이 토픽으로 보내라"는 로직을 명시적으로 구현해야 합니다.
🔔 알림(푸시) 전송 실패 시나리오: 어떻게 다를까?
푸시 알림 발송 중 일시적인 네트워크 오류로 실패하는 경우를 가정해 봅시다.
| 단계 | RabbitMQ (DLX 사용) | Kafka (DLQ Topic 패턴 사용) |
|---|---|---|
| 1️⃣ 발행 | 알림 큐(my-notification-queue, DLX 설정됨)로 메시지 발행. | 알림 토픽(notification-topic)으로 레코드 발행. |
| 2️⃣ 소비/시도 | 알림 서비스(Consumer)가 메시지 수신 후 푸시 전송 시도. → 실패! | 알림 서비스(Consumer)가 레코드 수신 후 푸시 전송 시도. → 실패! (예외 발생) |
| 3️⃣ 실패 처리 | Consumer는 basic.nack(requeue=false) 호출.➡️ 브로커가 자동으로 해당 메시지를 설정된 DLX로 재발행 → DLQ( my-notification-dlq)에 도착. | Consumer 코드의 catch 블록 실행.➡️ Consumer가 직접 KafkaProducer를 사용해 실패한 레코드를 DLQ 토픽(notification-dlq-topic)으로 재발행(produce). |
| 4️⃣ 후속 조치 | 별도의 DLQ Consumer가 my-notification-dlq를 구독하여 재시도/분석/모니터링. | 별도의 DLQ Consumer 서비스가 notification-dlq-topic을 구독하여 재시도/분석/모니터링. |
보시다시피 RabbitMQ는 3단계 처리가 자동이지만, Kafka는 Consumer가 직접 실패 레코드를 DLQ 토픽으로 보내야 합니다. (단, Kafka Connect나 Spring Kafka 같은 경우는 해당 컴포넌트/프레임워크가 이 부분을 자동화해 줄 수 있습니다.)
🤔 그래서, 언제 무엇을 선택해야 할까요?
| 선택 기준 | RabbitMQ DLX (자동) | Kafka Dead-Letter Topic (패턴/수동) |
|---|---|---|
| 구현/구성 단순성 | 매우 우수. (설정 몇 줄로 끝) | Consumer 코드/프레임워크 설정 등 구현 필요. |
| 메시지 처리량/규모 | 일반적인 메시지 큐잉, 수만 TPS 규모까지 무난. | 대규모 스트리밍, 로그 집계, 이벤트 소싱 등 고처리량 환경에 최적. |
| 메시지 순서 보장 | 큐 단위 FIFO 보장 (단일 Consumer 기준). | 파티션 키 설계에 따라 순서 보장 가능 및 병렬 처리 유리. |
| 생태계 및 주요 용도 | 전통적인 MQ, 작업 큐, RPC, AMQP 표준 준수. | 빅데이터 파이프라인, 실시간 분석, Event Sourcing 중심. |
| 유연성/커스터마이징 | 비교적 정해진 방식. | DLQ 로직(재시도 횟수, 전송 전 처리 등) 커스터마이징 용이. |
📌 핵심 요약
- RabbitMQ는 브로커에 Dead-Letter Exchange/Queue 기능이 내장되어 있어, 설정만으로 실패 메시지를 자동으로 별도 큐로 라우팅할 수 있습니다. (👍 매우 간편)
- Kafka는 코어 브로커 레벨의 자동 DLQ 기능은 없으며, "실패 레코드를 별도 DLQ 토픽으로 보내는 패턴" 을 애플리케이션/Connect/Streams/프레임워크 레벨에서 직접 구현해야 합니다. (⚙️ 유연하지만 구현 필요)
- 따라서, 단순히 "실패한 메시지를 나중에 처리하기 위해 안전하게 옮겨두는" 목적이라면:
- 구성이 간단하고 빠른 구현이 중요하다면 → RabbitMQ DLX 가 더 편리합니다.
- 대규모 데이터 스트리밍 환경이거나, DLQ 처리 로직에 대한 커스터마이징이 필요하다면 → Kafka + DLQ 토픽 패턴 (프레임워크 지원 활용 권장)이 적합합니다.
DLQ는 안정적인 메시지 처리 시스템을 구축하기 위한 필수 요소입니다. 각 시스템의 특징과 장단점을 명확히 이해하고, 여러분의 서비스 아키텍처와 요구사항에 맞는 최적의 도구와 패턴을 선택하시길 바랍니다!
