데이터베이스(Database)는 현대 애플리케이션의 심장과도 같습니다. 단순히 데이터를 저장하는 것을 넘어, 신뢰성 있는 데이터 관리, 컴포넌트 간 데이터 공유, 그리고 비즈니스 의사결정을 위한 핵심 정보를 제공하는 중추적인 역할을 담당합니다. 하지만 "데이터베이스"라는 용어는 그 사용 목적과 내부 구조에 따라 매우 다양한 시스템을 포괄합니다.
이 글에서는 데이터베이스의 근본적인 역할부터 시작하여, OLTP, OLAP, HTAP와 같은 주요 카테고리, DBMS의 내부 아키텍처, 그리고 특정 문제 해결에 특화된 Elasticsearch와 지리정보 데이터베이스까지, 개발자라면 꼭 알아야 할 데이터베이스의 모든 것을 깊이 있게 파헤쳐 보겠습니다. 빅테크 면접에서 자주 등장하는 질문과 핵심 개념을 중심으로 실무적인 관점까지 함께 살펴보시죠!
1. 데이터베이스의 근본적인 역할: 왜 사용할까요?
데이터베이스 관리 시스템(DBMS)은 우리에게 다음과 같은 핵심 가치를 제공합니다.
- 신뢰성 있는 데이터 저장: 데이터의 무결성, 일관성, 지속성을 보장하며 안전하게 데이터를 보관합니다.
- 애플리케이션 컴포넌트 간 데이터 공유: 여러 서비스나 사용자가 동일한 데이터에 접근하고 공유할 수 있는 중앙 저장소 역할을 합니다.
- 데이터의 원천 (Source of Truth): 중요한 비즈니스 데이터의 기준점이 되어, 데이터 기반 의사결정을 지원합니다.
이러한 기본적인 역할 외에도, 데이터베이스는 다양한 목적에 따라 특화된 기능을 제공합니다.
- 일시적인 대량 트래픽 처리 (예: 이벤트 기간 동안의 주문 데이터)
- 장기간 보존해야 하는 아카이브 데이터 저장
- 복잡한 분석 쿼리 및 리포팅 지원
- 키(Key)를 사용한 빠른 데이터 접근 (예: 캐싱)
- 이미지, 동영상 등 대용량 바이너리 객체(BLOB)의 효율적인 관리
2. 데이터베이스의 주요 카테고리: OLTP, OLAP, HTAP
데이터베이스는 주로 처리하는 작업의 성격에 따라 크게 세 가지 카테고리로 나눌 수 있습니다.
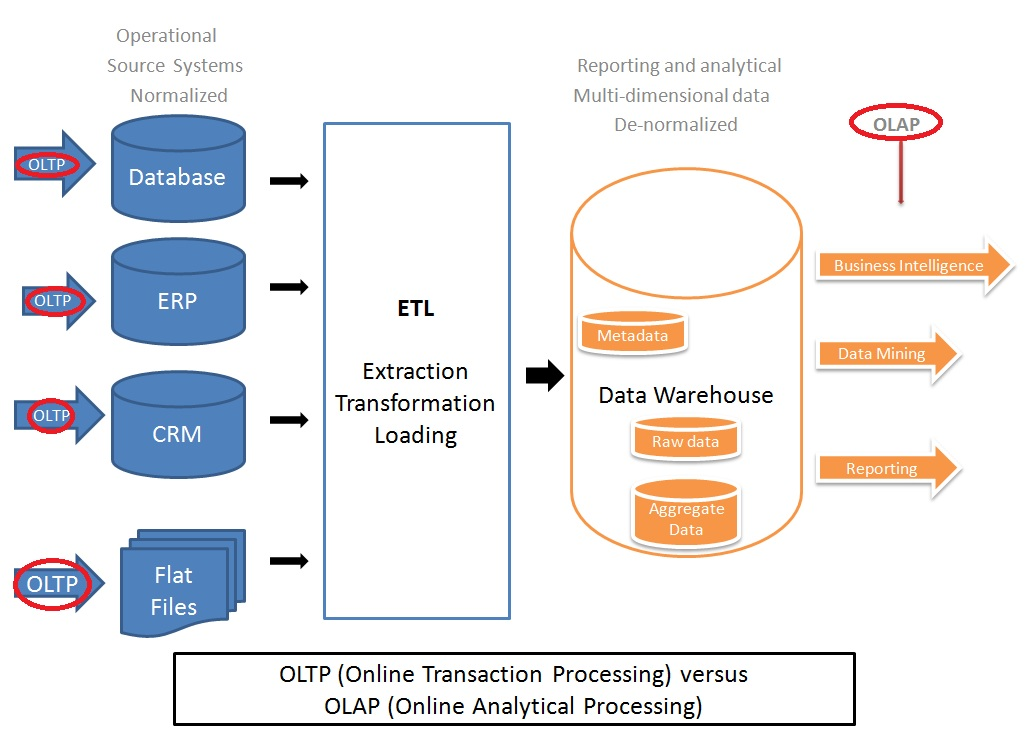
◼️ Online Transaction Processing (OLTP) 데이터베이스
- 정의: 실시간으로 발생하는 다수의 사용자 트랜잭션(INSERT, UPDATE, DELETE 등)을 빠르고 정확하게 처리하는 데 중점을 둔 시스템입니다.
- 특징:
- 빠른 응답 시간과 높은 처리량(Throughput)이 중요합니다.
- 데이터의 정확성과 일관성(ACID 특성)을 보장하는 것이 핵심입니다.
- 주로 정규화된 스키마를 사용하여 데이터 중복을 최소화합니다.
- 예시: MySQL, PostgreSQL, Oracle, SQL Server 등 관계형 데이터베이스(RDBMS)가 대표적입니다. 온라인 쇼핑몰의 주문 처리, 은행의 계좌 이체, 항공권 예약 시스템 등에 사용됩니다.
◼️ Online Analytical Processing (OLAP) 데이터베이스
- 정의: 대량의 과거 데이터를 기반으로 복잡한 분석 쿼리를 실행하여 비즈니스 의사결정에 필요한 인사이트를 도출하는 데 사용되는 시스템입니다.
- 특징:
- 읽기 중심(Read-heavy) 작업에 최적화되어 있습니다.
- 다차원 분석(Drill-down, Roll-up, Slicing, Dicing 등)을 효율적으로 지원합니다.
- 비정규화된 스키마(예: 스타 스키마, 눈송이 스키마)를 사용하여 분석 쿼리 성능을 높이는 경우가 많습니다.
- 활용 예시 (분석 질문):
- "올해 2분기 미국 지역에서 가장 많이 팔린 상품은 무엇인가?"
- "지난 3년간 월별 매출 추세를 제품 카테고리별로 비교 분석하고 싶다."
- "고객 세그먼트별 이탈률과 주요 원인은 무엇인가?"
- 예시 DB: Google BigQuery, Amazon Redshift, Snowflake, Apache Druid, ClickHouse 등이 있습니다. 이들은 주로 데이터 웨어하우스(DW) 역할을 수행합니다.
◼️ Hybrid Transactional and Analytical Processing (HTAP) 데이터베이스
- 정의: OLTP의 트랜잭션 처리 능력과 OLAP의 분석 능력을 하나의 시스템에서 통합적으로 제공하려는 데이터베이스 시스템입니다.
- 목표: 실시간 운영 데이터에 대해 별도의 ETL 과정 없이 즉시 분석을 수행하여, 더 빠른 의사결정을 지원하는 것입니다.
- 특징: 아직 발전 중인 분야이며, TiDB, SingleStore (구 MemSQL), SAP HANA 등이 HTAP를 지향하는 데이터베이스로 언급됩니다.
💡 인터뷰 팁: OLTP와 OLAP의 분리 이유
- 워크로드 특성 차이: OLTP는 짧고 빈번한 읽기/쓰기 트랜잭션, OLAP는 길고 복잡한 읽기 중심의 분석 쿼리가 주를 이룹니다. 이 두 가지 상반된 워크로드를 하나의 시스템에서 효율적으로 처리하기는 매우 어렵습니다.
- 성능 격리: OLAP의 무거운 분석 쿼리가 OLTP 시스템의 성능에 영향을 주어 실시간 트랜잭션 처리를 방해하는 것을 막기 위함입니다.
- 데이터 모델 차이: OLTP는 정규화된 모델, OLAP는 분석에 유리한 비정규화된 모델을 선호하는 경우가 많습니다.
따라서 일반적으로 운영 시스템(OLTP)에서 발생한 데이터를 주기적으로 ETL(Extract, Transform, Load) 과정을 거쳐 데이터 웨어하우스(Data Warehouse, DW)로 적재하고, 이 DW를 OLAP DB로 사용하여 분석 및 리포팅 작업을 수행하는 아키텍처를 구성합니다.
예상 질문 시나리오:
- "월간 매출 보고서를 빠르게 생성할 수 있는 시스템을 설계해주세요." (ETL → DW(OLAP DB) → BI 툴 구조 제시)
- "OLAP DB를 왜 별도로 분리해서 사용해야 하나요?" (위에서 언급한 워크로드, 성능 격리, 데이터 모델 차이 설명)
3. DBMS 아키텍처 한눈에 보기: 요청부터 저장까지
현대의 데이터베이스 관리 시스템(DBMS)은 단순한 CRUD(Create, Read, Update, Delete) 저장소가 아닙니다. 효율적인 쿼리 실행, 동시성 제어, 트랜잭션 처리, 장애 복구, 메모리 최적화 등 수많은 내부 컴포넌트들이 정교하게 협업하여 데이터의 정확성과 빠른 응답 속도를 보장합니다.
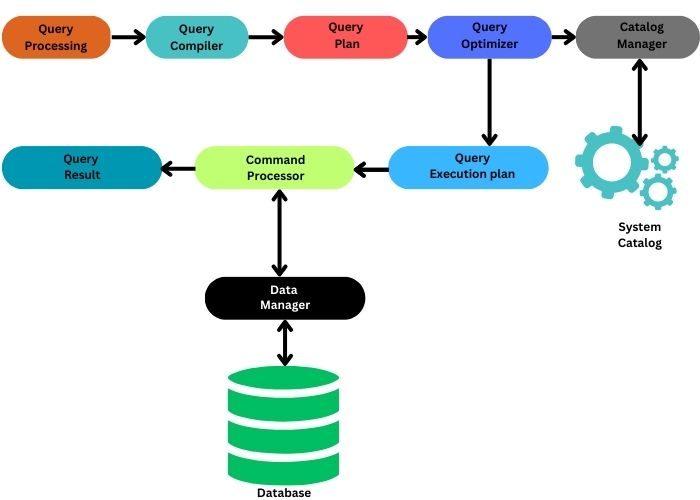
DBMS는 클라이언트의 요청을 받아 처리하고 결과를 반환하기까지 크게 다음과 같은 4단계를 거칩니다.
1) Transport Layer (전송 계층)
- 클라이언트(애플리케이션)와 데이터베이스 서버 간의 네트워크 통신을 담당합니다.
- 연결 설정, 인증, 요청/응답 메시지 직렬화/역직렬화 등을 처리합니다.
- 클라이언트로부터 받은 쿼리는 이 계층을 통해 Query Processor로 전달됩니다.
2) Query Processor (쿼리 처리기)
- 수신된 SQL 쿼리를 DBMS가 이해하고 실행할 수 있는 형태로 변환하고 최적화합니다.
- Query Parser (구문 분석기): SQL 쿼리의 문법적 오류를 검사하고, 파스 트리(Parse Tree) 또는 추상 구문 트리(AST)와 같은 내부 표현으로 변환합니다.
- Query Optimizer (쿼리 최적화기): 가장 효율적인 쿼리 실행 계획(Execution Plan)을 생성합니다.
- 통계 정보(테이블 크기, 인덱스 카디널리티, 데이터 분포 등)를 활용합니다.
- 다양한 접근 방법(예: 인덱스 스캔 vs. 풀 테이블 스캔), 조인 순서, 조인 알고리즘 등을 평가하여 비용이 가장 적게 드는 계획을 선택합니다.
- 불필요한 연산을 제거하고, 쿼리를 재작성(Query Rewrite)하기도 합니다.
- 실무 팁: 대부분의 RDBMS 성능은 이 쿼리 옵티마이저의 능력에 크게 좌우됩니다. 동일한 쿼리라도 옵티마이저의 판단에 따라 실행 속도가 수십 배 이상 차이 날 수 있습니다.
3) Execution Engine (실행 엔진)
- 쿼리 옵티마이저가 생성한 최적의 실행 계획에 따라 실제 쿼리를 실행합니다.
- Storage Engine으로부터 데이터를 읽거나 쓰고, 필요한 연산(정렬, 그룹화, 조인 등)을 수행합니다.
- 클러스터 환경에서는 로컬 노드뿐만 아니라 원격 노드에 분산된 데이터에 접근하여 쿼리를 실행(Remote Execution)하기도 합니다.
4) Storage Engine (스토리지 엔진)
- 데이터를 디스크나 메모리에 실제로 저장하고 접근하는 방식을 관리하는 핵심 컴포넌트입니다. 다양한 하위 모듈들이 유기적으로 작동합니다.
- Transaction Manager (트랜잭션 관리자): 트랜잭션의 ACID 속성(원자성, 일관성, 고립성, 지속성)을 보장합니다. 트랜잭션 스케줄링, 동시성 제어 등을 담당합니다.
- Lock Manager (잠금 관리자): 여러 트랜잭션이 동일한 데이터에 동시에 접근할 때 데이터 일관성을 유지하기 위해 잠금(Lock) 메커니즘을 관리합니다. (예: 공유 잠금, 배타적 잠금)
- Access Methods (접근 방법): B-Tree, LSM-Tree, Hash 인덱스 등 실제 데이터 구조에 접근하고 조작하는 인터페이스를 제공합니다.
- Buffer Manager (버퍼 관리자): 디스크 I/O 성능을 향상시키기 위해, 자주 사용되는 데이터 페이지를 메모리(버퍼 풀)에 캐싱하고 관리합니다. (예: LRU, LFU 알고리즘)
- Recovery Manager (회복 관리자): 시스템 장애(예: 정전, 서버 다운) 발생 시, 로그(WAL - Write-Ahead Logging 등)를 사용하여 데이터베이스를 일관된 상태로 복구합니다.
4. 메모리 기반 DBMS vs. 디스크 기반 DBMS: 성능과 지속성의 트레이드오프
데이터를 주로 어디에 저장하고 처리하느냐에 따라 DBMS는 크게 두 가지로 나눌 수 있습니다.
◼️ 인메모리 DBMS (In-Memory DBMS)
- 핵심 특징: 모든 데이터를 주기억장치인 RAM에 저장하고 처리합니다. 디스크는 주로 데이터 백업이나 트랜잭션 로그 저장(지속성 확보 목적)에만 제한적으로 사용됩니다.
- 장점: 디스크 I/O가 거의 발생하지 않으므로 매우 빠른 데이터 접근 속도와 낮은 지연 시간(Low Latency)을 제공합니다.
- 단점: RAM은 휘발성이므로 정전이나 시스템 장애 시 데이터 유실 위험이 존재합니다. (물론 이를 극복하기 위한 다양한 전략이 있습니다.) RAM 가격이 디스크보다 비싸므로 상대적으로 저장 용량당 비용이 높습니다.
- 적합한 환경: 실시간 분석, 고성능 캐싱 시스템, 금융 거래 시스템의 빠른 주문 처리 등 극도의 저지연과 높은 처리량이 요구되는 환경에 적합합니다. (예: Redis, Memcached - 엄밀히는 Key-Value Store지만 인메모리 특성 공유, SAP HANA)
◼️ 디스크 기반 DBMS (Disk-Based DBMS)
- 핵심 특징: 데이터를 주로 디스크(HDD, SSD)에 저장하고, 필요한 경우 Buffer Manager를 통해 일부 데이터를 메모리(버퍼 풀)에 캐싱하여 사용합니다.
- 장점: 데이터의 지속성(Durability)이 뛰어나며, 상대적으로 저렴한 비용으로 대용량 데이터를 저장할 수 있습니다.
- 단점: 디스크 I/O로 인해 인메모리 DBMS보다 데이터 접근 속도가 느릴 수 있습니다.
- 적합한 환경: 대부분의 일반적인 OLTP 및 OLAP 애플리케이션에 널리 사용됩니다. (예: MySQL, PostgreSQL, Oracle, SQL Server)
💡 인메모리 DBMS의 데이터 유실 위험 극복 전략
- 주기적인 디스크 스냅샷 (Check Pointing): 특정 시점의 메모리 상태를 디스크에 스냅샷으로 저장하고, 그 이후의 변경 사항은 로그로 기록하여 복구 시간을 단축합니다.
- WAL (Write-Ahead Logging): 데이터 변경 사항을 실제 데이터 페이지에 쓰기 전에 로그에 먼저 기록하여, 장애 발생 시 로그를 통해 복구함으로써 지속성을 확보합니다.
- 비휘발성 메모리 (NVRAM, NVDIMM) 사용: 배터리 백업 RAM이나 차세대 비휘발성 메모리를 활용하여 하드웨어적으로 데이터 유실을 방지합니다.
- 데이터 복제 (Replication): 여러 노드에 데이터를 복제하여 한 노드에 장애가 발생해도 다른 노드에서 서비스를 지속할 수 있도록 합니다.
5. 데이터베이스 종류와 개념 비교: 관계형(RDBMS) vs. NoSQL
데이터 모델링 방식과 확장성 전략에 따라 데이터베이스는 크게 관계형과 비관계형(NoSQL)으로 구분됩니다.
◼️ 관계형 데이터베이스 (RDBMS - Relational Database Management System)
- 핵심 특징:
- 데이터를 테이블(행과 열) 형태로 저장하며, 테이블 간의 관계를 키(기본 키, 외래 키)를 통해 정의합니다.
- 정형화된 스키마(Schema)를 가지며, 데이터 입력 시 스키마를 준수해야 합니다.
- SQL(Structured Query Language)이라는 표준 질의 언어를 사용하여 데이터를 조작하고 조회합니다.
- ACID 트랜잭션을 통해 데이터의 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)을 강력하게 보장합니다.
- 장점:
- 데이터 무결성 및 일관성 유지가 용이합니다.
- 복잡한 데이터 관계 표현 및 JOIN 연산에 강점을 가집니다.
- 성숙한 기술과 풍부한 생태계를 가지고 있습니다.
- 단점:
- 스키마가 고정되어 있어 유연성이 떨어질 수 있습니다. (스키마 변경 비용 발생)
- 일반적으로 수직적 확장(Scale-up: 서버 성능 향상)에 의존하며, 대규모 트래픽 처리나 수평적 확장(Scale-out: 서버 대수 증가) 구성이 상대적으로 복잡할 수 있습니다. (샤딩, 복제 등으로 일부 해결 가능)
- 적합한 환경: 금융 거래, ERP, CRM 등 데이터의 정확성과 일관성이 매우 중요한 업무, 정형화된 데이터를 다루는 시스템에 적합합니다.
◼️ NoSQL 데이터베이스 (Not Only SQL)
- 핵심 특징:
- 전통적인 RDBMS와 다른 유연한 데이터 모델을 제공하며, 수평적 확장성에 중점을 둔 비관계형 데이터베이스들을 통칭하는 용어입니다.
- 스키마가 없거나(Schemaless) 매우 느슨하여(Schema-flexible) 데이터 구조 변경에 용이합니다.
- CAP 이론(Consistency, Availability, Partition Tolerance)에서 일관성(C)보다는 가용성(A)이나 분산 환경에서의 장애 허용(P)을 우선시하는 경우가 많습니다. (결과적 일관성 - Eventual Consistency 모델 채택)
- BASE(Basically Available, Soft state, Eventual consistency) 속성을 지향하는 경우가 많습니다.
- 장점:
- 대용량 데이터 및 높은 트래픽 처리에 유리한 뛰어난 확장성을 제공합니다.
- 다양하고 유연한 데이터 모델을 지원하여 비정형/반정형 데이터 처리에 적합합니다.
- 일반적으로 RDBMS보다 빠른 읽기/쓰기 성능을 제공할 수 있습니다 (특정 워크로드에 따라 다름).
- 단점:
- RDBMS만큼 강력한 데이터 일관성을 보장하기 어려울 수 있습니다. (애플리케이션 레벨에서 일관성 처리 필요 가능성)
- 복잡한 JOIN 연산이나 트랜잭션 지원이 제한적일 수 있습니다. (최근에는 일부 NoSQL도 트랜잭션 지원 강화 추세)
- 데이터 모델 및 쿼리 방식이 다양하여 학습 곡선이 존재할 수 있습니다.
NoSQL의 대표적인 하위 유형:
-
키-값 저장소 (Key-Value Store):
- 구조: 고유한 키(Key)에 값(Value)을 매핑하는 단순한 해시 테이블 형태. (예: Redis, Amazon DynamoDB, Memcached)
- 특징: O(1)에 가까운 매우 빠른 읽기/쓰기 성능. 값의 내부 구조에 대한 질의는 제한적.
- 주요 용도: 캐싱, 세션 관리, 실시간 순위표 등 간단한 데이터 조회 및 빠른 응답이 중요한 경우.
- DynamoDB 예시: Amazon Dynamo 시스템은 쇼핑 카트 서비스에 키-값 스토어를 활용하여 높은 가용성을 보장했습니다. 네트워크 분할 상황에서도 쓰기를 허용하는 AP(Availability, Partition Tolerance) 지향 설계를 통해 "Always Writable" 시스템을 구현했습니다.
-
문서 지향 데이터베이스 (Document Store):
- 구조: JSON, BSON, XML 등 유연한 문서(Document) 형식으로 데이터를 저장. 각 문서는 독립적인 필드 구조를 가질 수 있음. (예: MongoDB, CouchDB)
- 특징: 스키마 유연성이 매우 높음. 문서 내 필드에 대한 인덱싱 및 질의 가능. 집계 파이프라인 지원.
- 주요 용도: 웹 애플리케이션 백엔드, 사용자 프로필 관리, 콘텐츠 관리 시스템(CMS), 다양한 형태의 데이터를 수용해야 하는 경우.
- MongoDB 예시: 같은 컬렉션 내의 사용자 문서들이 각기 다른 속성을 가질 수 있으며, 새로운 속성 추가가 다른 문서에 영향을 주지 않아 데이터 모델 변경에 탄력적입니다. 최근에는 다중 문서 트랜잭션도 지원하고 있습니다.
-
컬럼 패밀리 데이터베이스 (Column-Family / Wide-Column Store):
- 구조: 행(Row) 대신 컬럼 패밀리(Column Family) 단위로 데이터를 묶어 저장. 각 행은 서로 다른 컬럼 집합을 가질 수 있음. (예: Apache HBase, Apache Cassandra, Google Cloud Bigtable, ScyllaDB)
- 특징: 대용량 데이터의 수평 확장에 매우 뛰어남. 특정 컬럼들만 선택적으로 읽는 데 최적화. 컬럼 단위 압축으로 저장 효율 우수.
- 주요 용도: 시계열 데이터, IoT 센서 데이터, 로그 데이터 수집 및 분석, 메시징 시스템 등 쓰기 작업이 빈번하고 데이터 규모가 매우 큰 경우.
- Cassandra/Netflix 예시: Netflix는 Cassandra를 여러 리전에 분산 배치하여 수십억 건의 시청 이벤트와 사용자 행동 로그를 저장하고, 서비스 중단 없이 데이터를 무한 확장하도록 시스템을 구축했습니다. Cassandra는 멀티 마스터 구조로 일관성보다 가용성을 우선시하는 AP 지향 시스템입니다.
-
그래프 데이터베이스 (Graph Database):
- 구조: 데이터를 노드(Node)와 간선(Edge, 관계)의 그래프 형태로 표현하고 저장. (예: Neo4j, Amazon Neptune)
- 특징: 데이터 간의 복잡한 연결 관계를 탐색하고 분석하는 데 최적화. 관계 자체를 일급 객체로 취급.
- 주요 용도: 소셜 네트워크 분석, 추천 시스템, 지식 그래프 구축, 사기 탐지 시스템, 경로 탐색 등 관계 중심의 질의가 중요한 경우.
- GraphQL과의 구분: GraphQL은 API를 위한 쿼리 언어이지 데이터베이스 자체가 아닙니다. 그래프 DB는 데이터를 그래프 형태로 저장하고 처리하는 백엔드 시스템입니다.
💡 NoSQL 선택 시 고려사항:
NoSQL 데이터베이스는 관계형 DB의 한계를 극복하기 위해 등장했지만, 모든 상황에 적합한 만능 해결책은 아닙니다. 선택 시에는 어떤 제약(예: 강한 일관성 포기)을 감수하고 어떤 이점(예: 확장성, 유연성 확보)을 얻을 것인지 명확히 이해하고, 애플리케이션의 특성과 데이터 처리 요구사항에 가장 적합한 유형을 선택해야 합니다.
6. 특수 목적 데이터베이스: Elasticsearch와 지리정보 DB
일반적인 OLTP, OLAP, NoSQL 외에도 특정 문제 해결에 고도로 특화된 데이터베이스들이 존재합니다.
◼️ Elasticsearch: 대용량 데이터의 실시간 검색 및 분석 엔진
"엄청나게 많은 데이터 중에서 원하는 정보를 얼마나 빠르게 찾을 수 있는가?" 많은 시스템 디자인 문제는 결국 이 질문으로 귀결됩니다. 관계형 DB도 전문 검색(Full-Text Search) 기능을 제공하지만, 데이터 양이 많아지고 검색 조건이 복잡해질수록 성능 한계에 부딪힙니다. 이때 강력한 대안이 바로 Elasticsearch입니다.
- 핵심 기능: Apache Lucene 기반의 오픈소스 분산 검색 및 분석 엔진. 실시간 검색, 정렬, 필터링, 집계, 랭킹, 자동완성 등 거의 모든 검색 관련 요구사항을 효과적으로 처리합니다.
- 내부 구조:
- 역색인(Inverted Index): 단어(Term)를 기준으로 해당 단어가 포함된 문서 ID 목록을 매핑하여 저장합니다. 이를 통해 키워드 검색 시 O(1)에 가까운 빠른 속도를 제공합니다. (
LIKE '%keyword%'와 비교 불가) - Doc Values (Columnar Storage): 필드 값을 열(Column) 단위로 저장하여 정렬, 필터링, 집계 연산 시 필요한 데이터만 효율적으로 접근하여 성능을 향상시킵니다.
- JSON 기반 문서 모델: 유연한 데이터 구조를 지원합니다. (Document → Index → Field → Mapping)
- 역색인(Inverted Index): 단어(Term)를 기준으로 해당 단어가 포함된 문서 ID 목록을 매핑하여 저장합니다. 이를 통해 키워드 검색 시 O(1)에 가까운 빠른 속도를 제공합니다. (
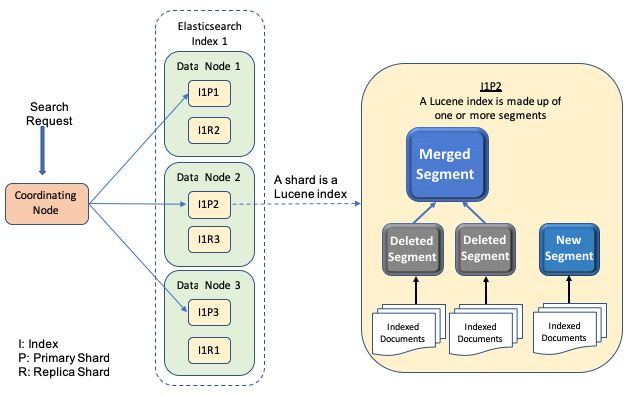
- 분산 아키텍처:
- 클러스터(Cluster) > 노드(Node) > 인덱스(Index) > 샤드(Shard) > 세그먼트(Segment) 계층 구조.
- 노드(Node): 클러스터를 구성하는 개별 서버. 역할(Master, Data, Coordinating, Ingest 등)에 따라 구분됩니다.
- 샤드(Shard): 하나의 인덱스를 여러 조각으로 분산 저장하는 단위. 각 샤드는 독립적인 Lucene 인덱스입니다. 병렬 처리 및 수평 확장 가능.
- 세그먼트(Segment): Lucene 인덱스 내부의 데이터 저장 단위. 불변(Immutable) 특성을 가져 쓰기 성능, 병렬 검색, 캐싱에 유리합니다. (Insert는 새 세그먼트에, Update/Delete는 Soft Delete 후 Merge 시 실제 처리)
- 데이터 정합성 및 활용:
- ACID 트랜잭션 지원이 제한적이며, 결과적 일관성(Eventual Consistency) 모델을 따릅니다. (문서 색인 후 검색 가능까지 약간의 지연 발생 가능 -
refresh_interval설정) - 강한 정합성이 필수인 금융 시스템의 메인 DB로는 부적합하며, 검색 기능이 중요한 서브시스템 용도로 많이 사용됩니다. (원본 데이터는 RDBMS/NoSQL에 저장 → Elasticsearch로 비동기 CDC 동기화)
- 로그 분석, 실시간 모니터링 대시보드(ELK/EFK Stack), 상품 검색, 추천 엔진, 자동완성 등에 널리 활용됩니다.
- ACID 트랜잭션 지원이 제한적이며, 결과적 일관성(Eventual Consistency) 모델을 따릅니다. (문서 색인 후 검색 가능까지 약간의 지연 발생 가능 -
- 주의사항: Join 연산 미흡, 빈번한 업데이트(Frequent Update) 워크로드에는 비효율적일 수 있습니다.
💡 인터뷰에서 Elasticsearch 언급 시:
- "왜 일반 DB의 검색 기능으로는 부족한가?" (역색인, 분석 기능의 장점)
- "Elasticsearch가 검색 시나리오에 최적화된 이유는 무엇인가?" (분산 구조, 샤딩, 역색인, Doc Values)
- "데이터 일관성 및 원본 데이터와의 동기화 전략은 어떻게 가져갈 것인가?" (Eventual Consistency, CDC 활용)
◼️ 지리정보 데이터베이스 (Geospatial DB): 위치 기반 서비스의 핵심
"내 주변 카페 찾기", "5km 반경 내 택시 호출" 등 위치 기반 서비스는 현대 애플리케이션에서 매우 흔합니다. 이러한 공간적인 질의는 단순한 값 비교가 아닌, 좌표 간의 거리나 영역 포함 관계 등을 계산해야 하므로 일반 RDBMS만으로는 효율적인 처리가 어렵습니다.
- 핵심 기능: 지도 좌표(점, 선, 폴리곤 등 Geometry)와 같은 공간 데이터를 효율적으로 저장, 인덱싱, 질의하기 위한 특수 목적 데이터베이스입니다. (예: PostgreSQL의 확장인 PostGIS, Oracle Spatial, MongoDB의 GeoJSON 지원)
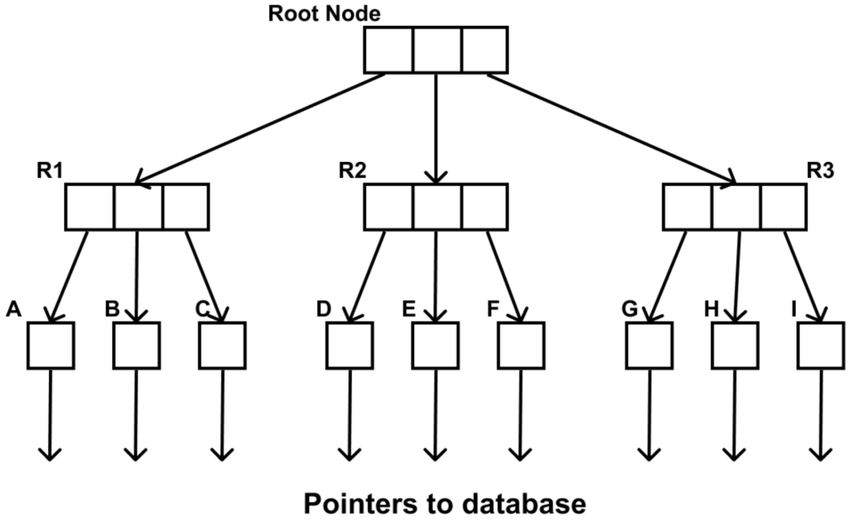
- 공간 인덱스 (Spatial Index):
- "범위 내 포함", "근접 거리 탐색", "교차 여부 판단" 등 공간 연산의 성능을 획기적으로 향상시키는 핵심 기술입니다.
- 대표적인 구조: R-Tree (범위 기반), Quad-tree (계층적 공간 분할), Geohash (문자열 기반 공간 인코딩), H3 (Uber 개발, 육각형 격자 시스템)
- PostGIS는 주로 GiST(Generalized Search Tree) 인덱스를 사용하여 R-Tree와 유사한 방식으로 공간 데이터를 인덱싱합니다.
- 지리 공간 함수 (Spatial Functions):
ST_Distance: 두 지점 간의 거리 계산.ST_Within/ST_Contains: 점이 폴리곤 내부에 포함되는지, 또는 폴리곤이 대상을 포함하는지 판단.ST_Intersects: 두 지오메트리가 교차하는지 판단.- 이러한 함수를 DB 내부에서 직접 수행하므로, 애플리케이션 서버에서 모든 데이터를 가져와 계산하는 것보다 훨씬 효율적입니다.
- 활용 사례:
- Uber의 H3 시스템: 전 세계를 육각형 셀(Cell)로 분할하고, 각 셀 단위로 수요-공급 데이터 집계, 인접 셀 탐색, 동적 요금제(Surge Pricing) 계산, 운전자 배치 최적화 등에 활용합니다.
- 위치 기반 서비스(LBS), 내비게이션, 물류 경로 최적화, 도시 계획, 환경 분석 등 다양한 GIS(Geographic Information System) 분야.
💡 인터뷰에서 위치 기반 시스템 설계 시:
단순히 "RDBMS에 위도, 경도 컬럼을 추가한다"는 답변만으로는 부족합니다. "내 주변 OO 찾기", "특정 지역 내 XX 목록 조회"와 같은 요구사항이 있다면, 반드시 공간 인덱스(R-Tree, GiST 등), PostGIS와 같은 확장 기능, 또는 H3와 같은 전용 격자 시스템 도입을 제안하여 깊이 있는 이해를 보여주는 것이 중요합니다.
결론: 데이터베이스, 목적에 맞는 최적의 선택이 중요
지금까지 살펴본 것처럼, "데이터베이스"라는 하나의 단어 뒤에는 실로 방대하고 다양한 기술과 시스템이 존재합니다. OLTP, OLAP, RDBMS, NoSQL의 여러 유형, 그리고 Elasticsearch나 지리정보 DB와 같은 특수 목적 시스템까지, 각각의 데이터베이스는 고유한 강점과 적합한 활용 사례를 가지고 있습니다.
성공적인 시스템 설계의 핵심은 애플리케이션의 요구사항(데이터 모델, 성능, 확장성, 일관성 수준 등)을 정확히 파악하고, 그에 가장 적합한 데이터베이스 기술을 "선택"하고 "조합"하는 능력에 있습니다. 이 글이 여러분의 데이터베이스에 대한 이해를 넓히고, 더 나은 기술적 의사결정을 내리는 데 도움이 되었기를 바랍니다.
