
해당 내용은 인프런 JSCODE 박재성의 비전공자도 이해할 수 있는 Redis 입문/실전(조회 성능 최적화편)의 강의를 기반으로 작성했습니다.
강사님의 공부법에 따라 제 해석대로 작성해봅니다.
📢 로컬(Windows, MacOS)에서 Redis 설치하기
Redis 설치 프로그램(msi) 다운
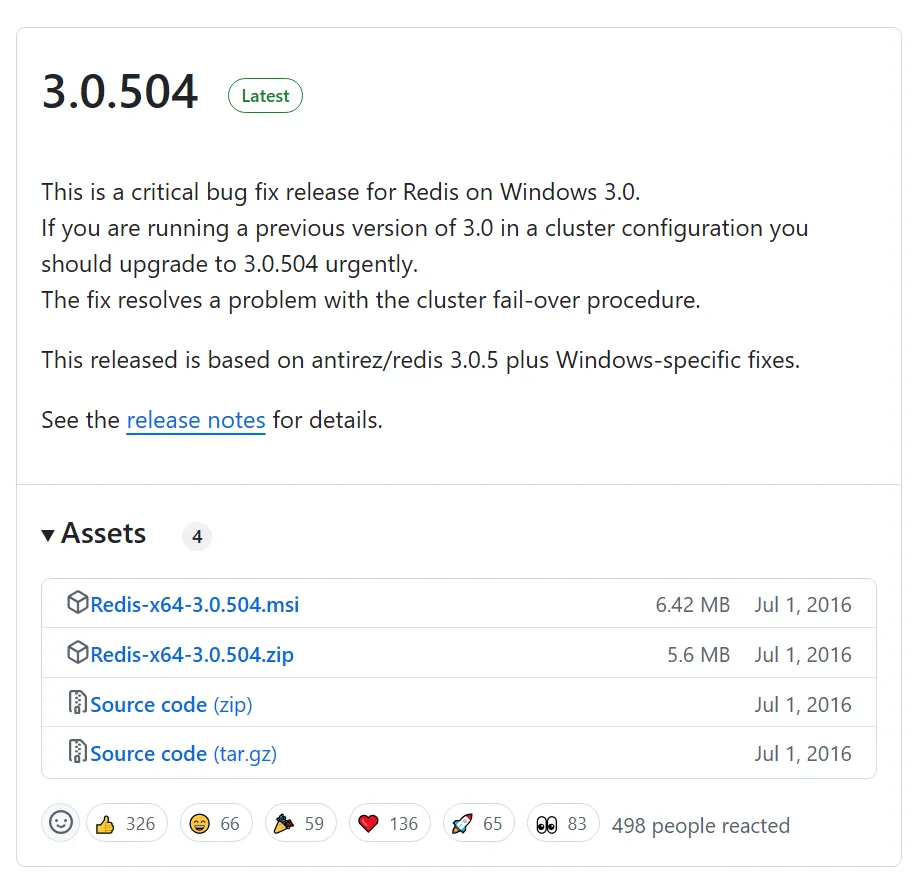
Redis 설치 프로그램 실행 및 설치

 이미 깔려 있었네...? 삭제하고 다시 설치
이미 깔려 있었네...? 삭제하고 다시 설치
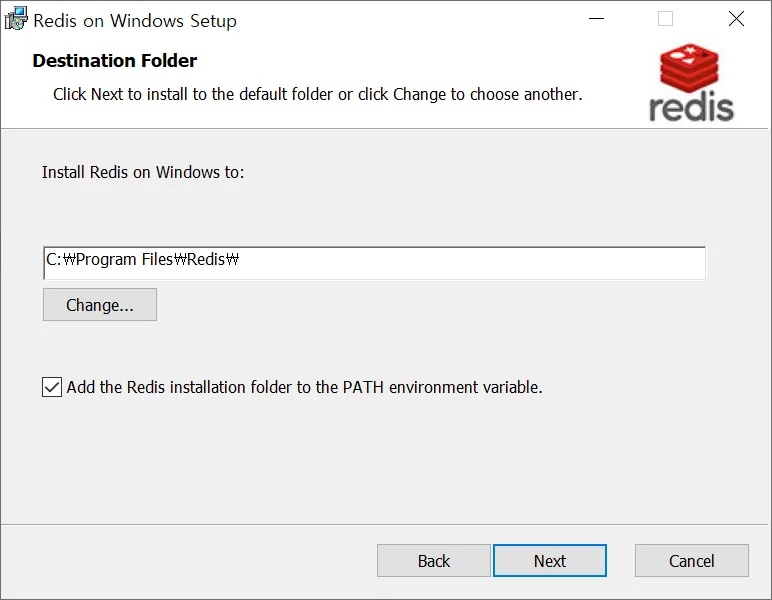
경로 설정
포트 설정
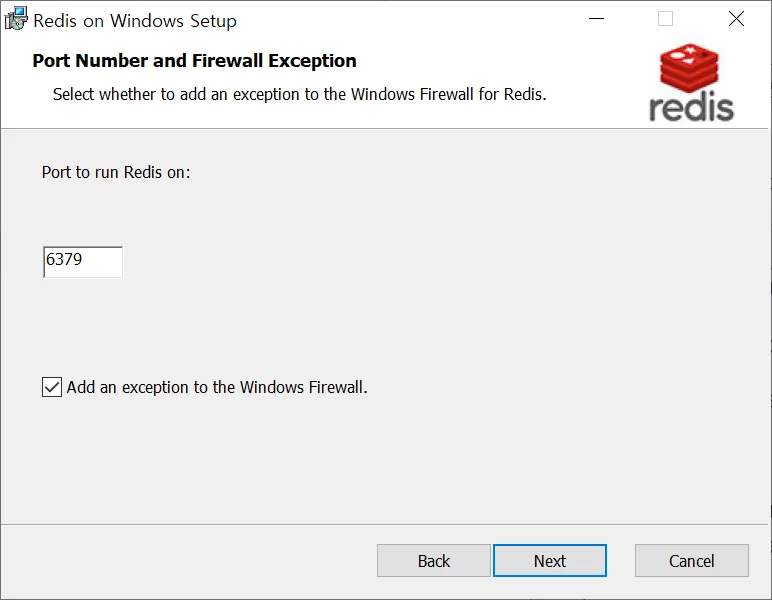
- Redis의 기본 포트 : 6739
메모리 제한 선택
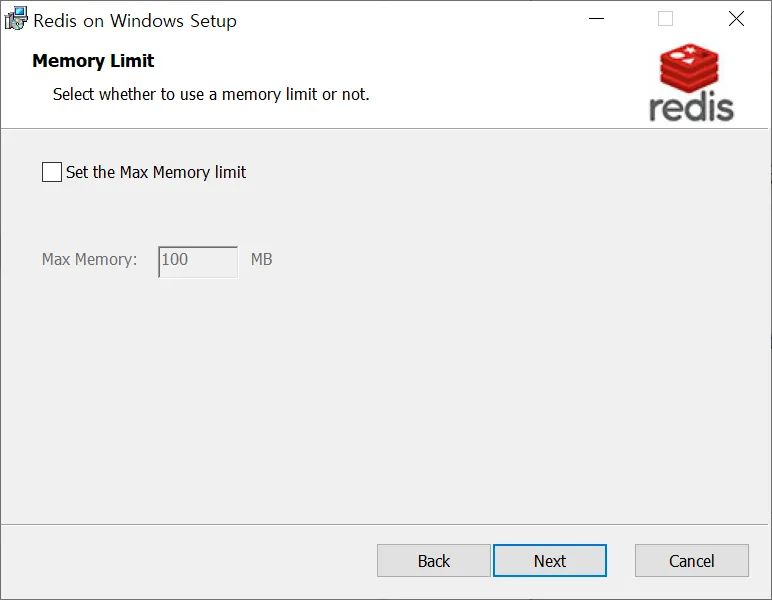
- Redis에 할당할 메모리 크기 지정
- 기본 : 100MB
설치 완료

Redis 실행
서버 실행 확인
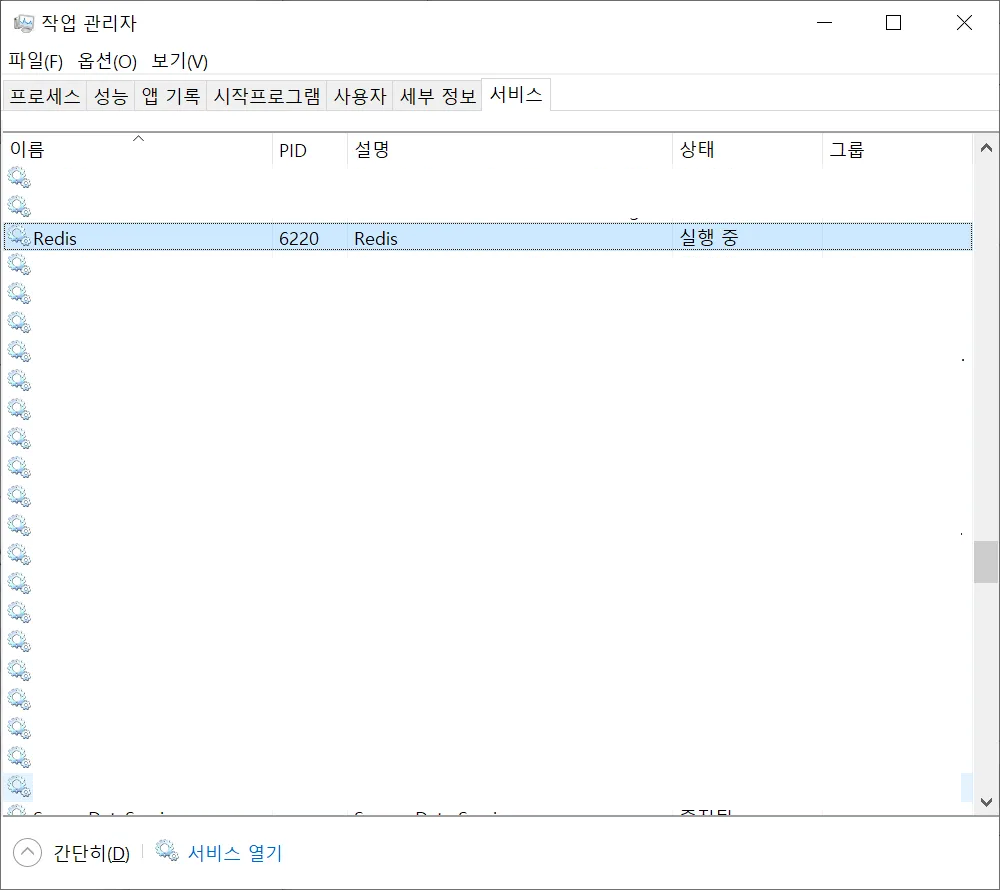
클라이언트 실행
redis-cli.exe실행
Redis 작동 확인
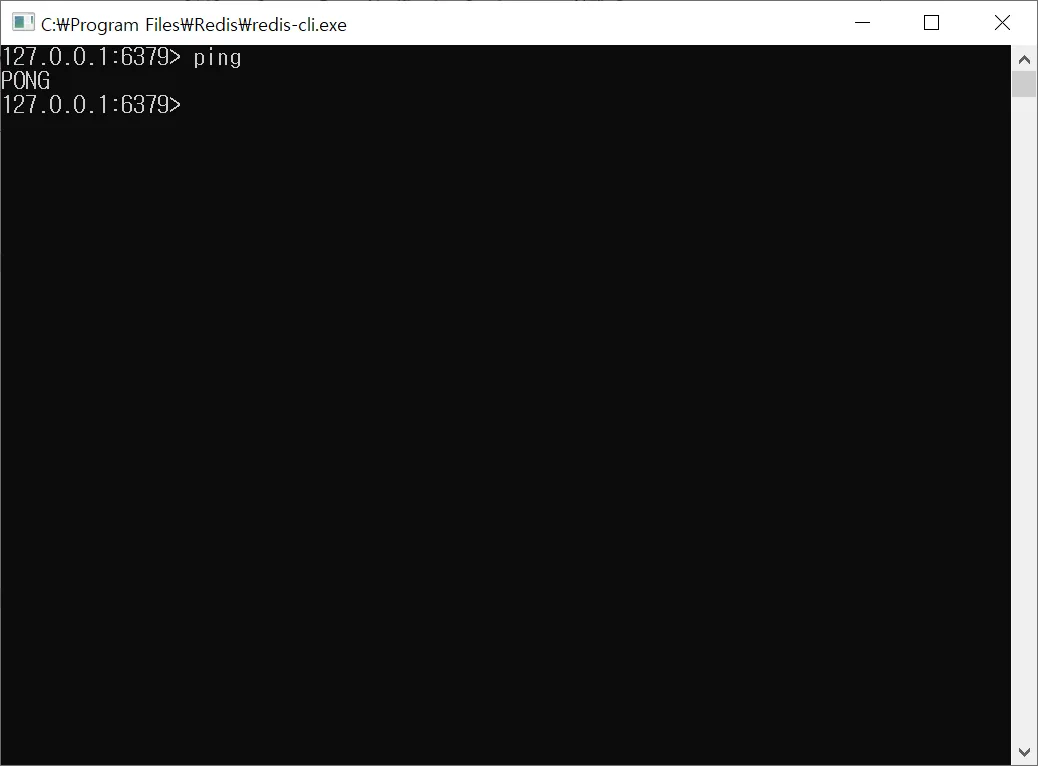
ping- 위 이미지처럼 ping을 입력하면 pong이라는 확인 응답
📢 Redis 기본 명령어 익히기
Reids를 가지고 조회 성능을 개선할 때 필요한 7가지 명령어만 학습
추가적으로 필요한 기능은 그때그때 찾아서 사용
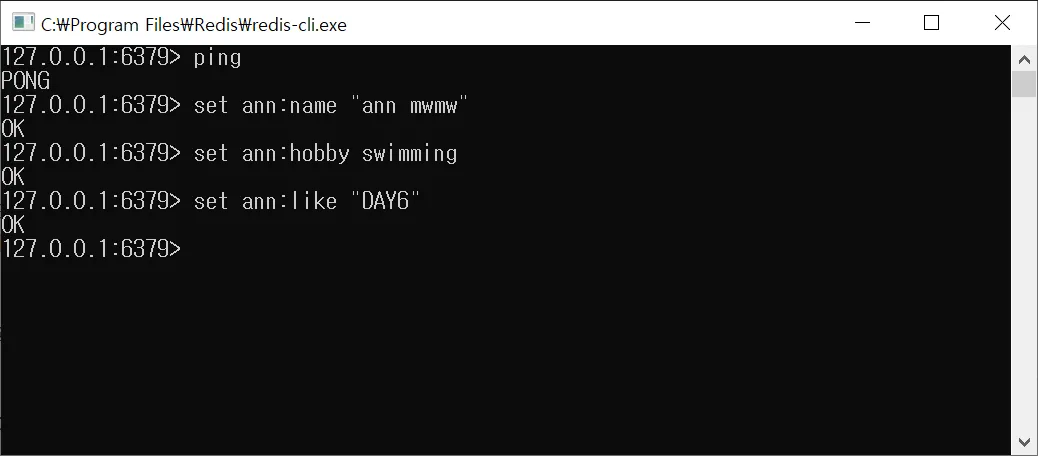
데이터(Key, Value) 저장하기
$ set ann:name "ann mwmw"
$ set ann:hobby swimming
$ set ann:like "DAY6"
$ set [Key] [Value]
Value 안에 띄어쓰기까지 하려면 ""로 표기
데이터 조회하기(Key로 Value값 조회하기)
$ get ann:name
$ get ann:like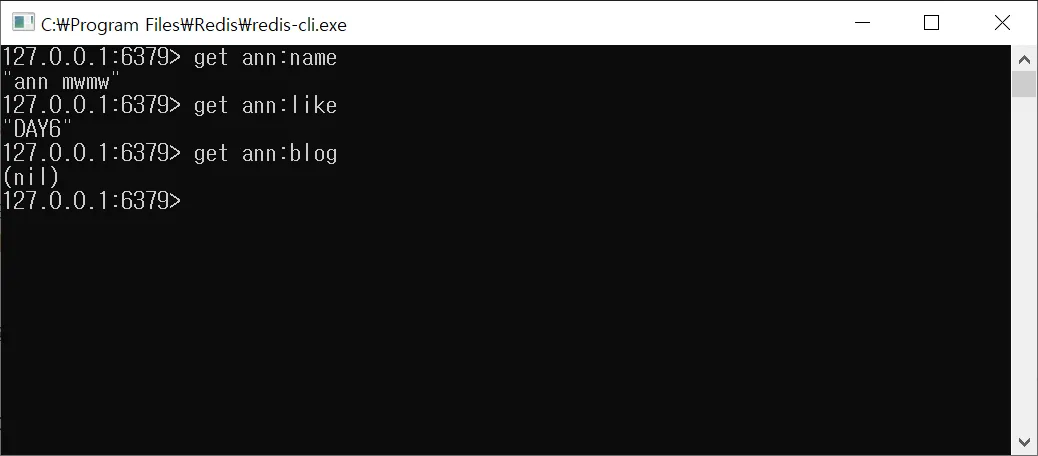
- 없는 Value를 조회할 경우 (nil) 출력
데이터 삭제(Key로 데이터 삭제하기)
$ del ann:hobby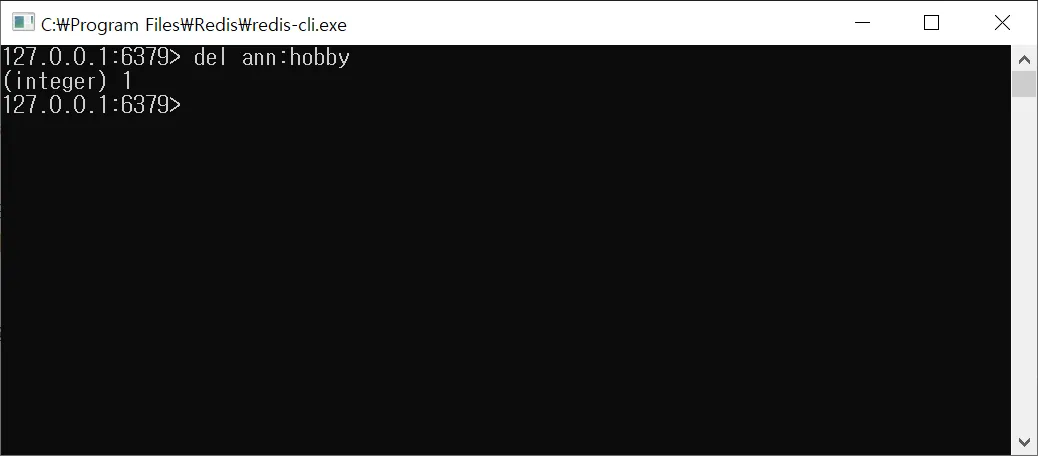
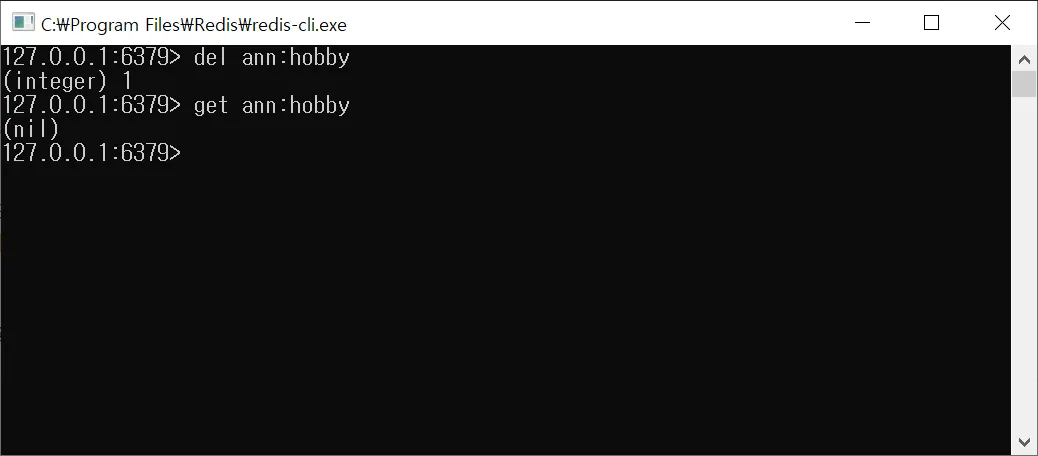
del명령어로 Key를 입력하면, 해당하는 데이터 삭제get명령어로 해당 Key 조회하면 삭제되었음을 확인 가능
데이터 저장 시 만료 시간(TTL) 정하기
RDBMS(MySQL)는 1시간 뒤에 열어봐도 데이터가 그대로 존재하지만, Redis는 1시간 뒤에 열어봤을 때 데이터가 없도록 설정 가능
→ 즉, 영구적으로 데이터를 저장하지 않고 일정 시간이 지나면 데이터가 삭제되도록, 데이터 저장 시에 데이터를 보관하는 만료 시간을 설정가능
Why? Redis의 특성상 메모리 공간이 한정되어 있기 때문에, TTL을 활용해 자주 사용하지 않는 데이터는 삭제하고, 자주 사용하는 데이터만 Redis에 저장
TTL이란?
Time To Live, 살아 있는 시간 = 즉, 만료되기까지의 시간
# $ set [key 이름] [value] ex [만료 시간(초)] # ex == expire $ set ann:coffee latte ex 30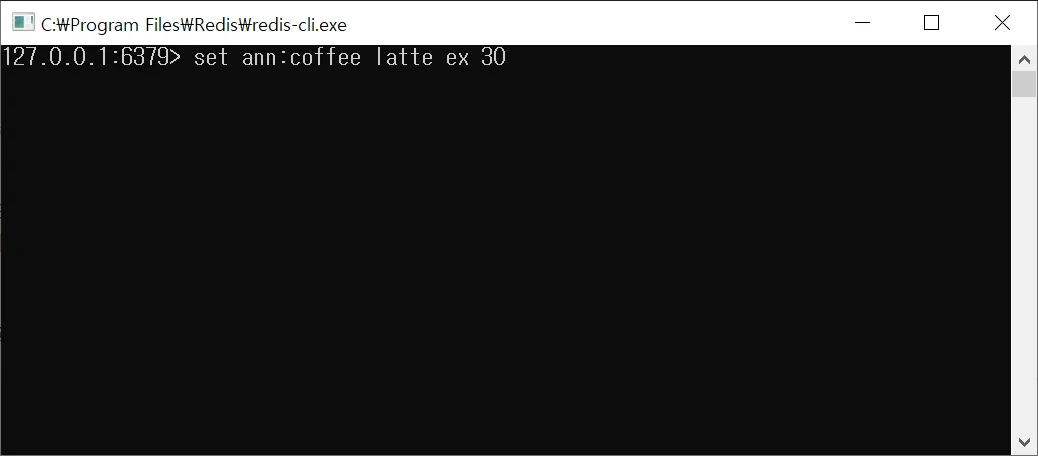
만료 시간(TTL) 확인하기
# ttl [key 이름]
$ ttl ann:coffee # 남은 시간 반환 or 남은 시간이 모두 지나면 삭제되어서 -2 반환
$ ttl ann:food #처음부터 존재하지 않아, 없는 Key이므로 -2 반환
$ ttl ann:name #Key는 존재하지만, TTL은 존재하지 않은 경우, -1 반환만료 시간이 몇 초 남았는지 반환
삭제된(즉, 존재하지 않는) Key를 조회하면, -2 반환
Key는 존재하지만 TTL이 없는 경우, -1반환
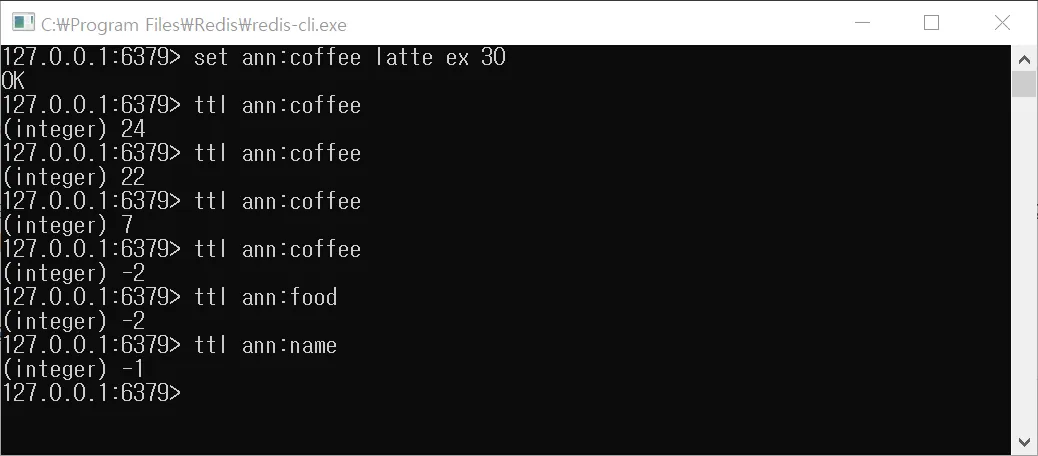
ann:coffee의 경우는 TTL을 반환하다가, 30초가 지나서 아예 데이터(Key-Value)가 삭제되어 -2를 반환
모든 데이터 삭제하기
$ flushall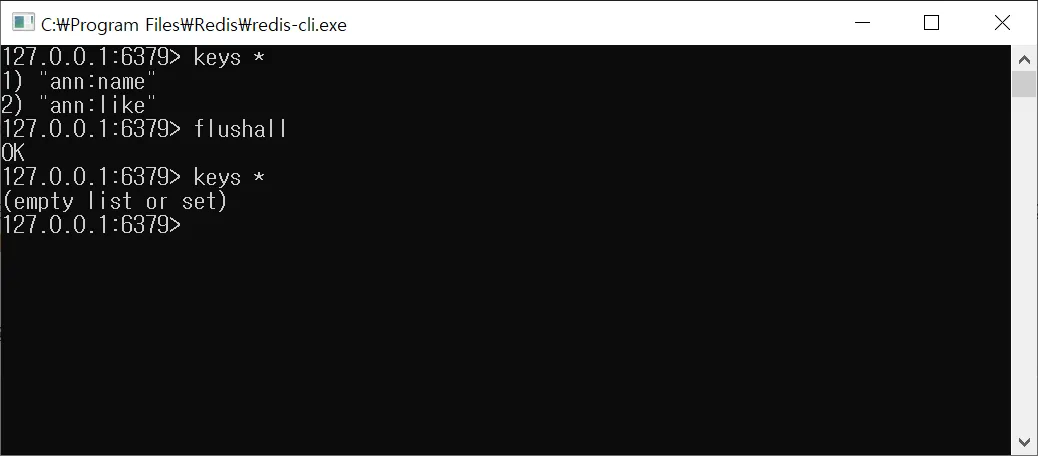
- 모두 삭제된 것을 확인
📢 Redis에서 Key 네이밍 컨벤션 익히기
Reids의 Key이름을 짓는 건 정해져있지 않지만, 자주 사용하는 Key 네이밍 컨벤션을 배워 활용
현업에서 자주 사용하는 네이밍 컨벤션
콜론(
:)을 활용해 계층적으로 의미를 구분해서 사용
그외에도 다양
예시
users:100:profile: 사용자들(users) 중에서 PK가 100인 사용자(user)의 프로필(profile)
users:123:details: 상품들(products) 중에서 PK가 123인 상품(product)의 세부사항(details)
- 계층적으로 의미를 구분
→ 왼쪽부터 읽으면서 해석이 가능
ann:name # ann의 name
ann:like # ann이 좋아하는 것
따라서 나도 위에서처럼 사용해봄😶
이렇게 정하면 뭐가 좋은데?🤔
1. 가독성 : 데이터의 의미와 용도를 쉽게 파악 가능
→ Key 네이밍만 보고 어떤 데이터인지 유추 가능
2. 일관성 : 컨벤션을 따름으로써 코드의 일관성이 높아지고 유지보수 용이
3. 검색 및 필터링 용이성 : 패턴 매칭을 사용해 특정 유형의 Key를 쉽게 발견
4. 확장성 : 서로 다른 Key와 이름이 거쳐 충돌할 일 감소
