
해당 내용은 인프런 JSCODE 박재성의 비전공자도 이해할 수 있는 Redis 입문/실전(조회 성능 최적화편)의 강의를 기반으로 작성했습니다.
📢 캐시(Cache), 캐싱(Caching)이란?
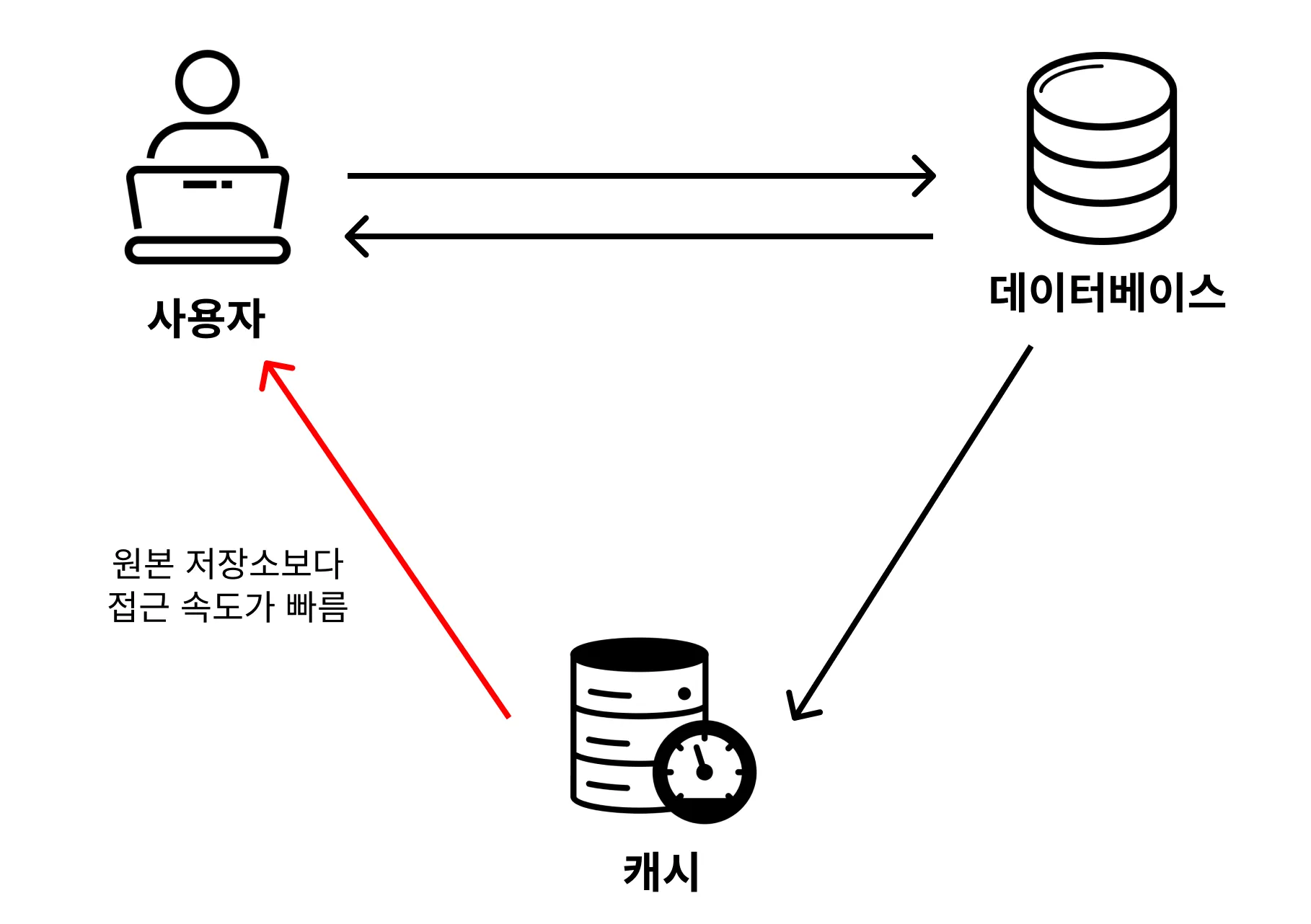
캐시(Cache)란?
데이터를 원본 저장소보다 빠르게 가져올 수 있는 임시 데이터 저장소
참고로, Redis에서만 쓰이는 용어가 아닌 전반적인 개발 분야에서 통용되는 단어
데이터는 원래 원본 데이터베이스에 저장하지만, 데이터베이스 서버의 물리적인 거리가 멀든 혹은 다른 문제에 의해 속도가 너무 느림
→ "더 빨리 가져올 수 없을까?" 하다가 데이터를 빨리 가져오게끔 속도가 빠르거나 거리가 가까운 임시 저장소를 마련
- 이 임시 저장소를 캐시라고 함
캐시의 특징
- 원본의 데이터가 저장되어 있는 곳보다 접근 속도가 빠름
참고) 브라우저에도 캐시 존재
- 브라우저에도 캐시 존재 == 브라우저에 임시로 이미지랑 파일 저장
Why? 나중에 그 페이지를 들어갔을 때 빠르게 그 이미지랑 파일을 열어서 홈페이지가 빨리 로딩되도록 크롬에서 캐시를 시켜둠
💡 오!
캐시 == 임시로 이미지나 파일 저장
이미지나 파일은 비정형 데이터고, Redis는 비정형 데이터를 저장해둔다 했으니, 그럼 Redis가 캐시하기 좋겠네?
캐싱(Caching)이란?
캐시(Cache, 임시 데이터 저장소)에 접근해서 데이터를 빠르게 가져오는 방식
"이 API는 응답 속도가 너무 느린데? 이 응답 데이터는 캐싱(Caching)해두고 쓰는 게 어때?"
즉, "API 응답 결과를 원본 데이터베이스보다 빠르게 가져올 수 있는 임시 데이터 저장소(Cache)에 저장해두고, 빠르게 조회할 수 있게 만드는 게(Caching) 어때?"라는 의미
📢 데이터를 캐싱할 때 사용하는 전략(Cache Aside, Write Around)
Redis를 캐시로 쓸 때, 데이터를 어떻게 캐싱을 하고 캐싱된 데이터를 어떻게 조회해올 건지에 대한 전략은 다양하지만, 딱 2가지만 살펴볼 것!
Cache Aside (= Look Aside, Lazy Loading) 전략
Cache Aside의 흐름
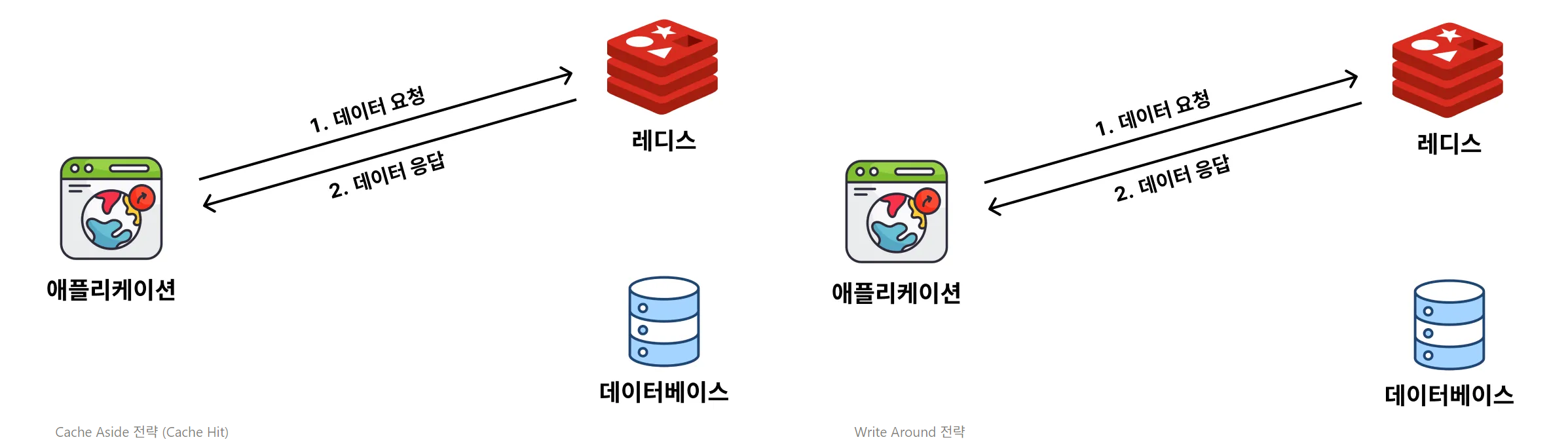
1. 캐시에 데이터가 있을 경우 (= Cache Hit)
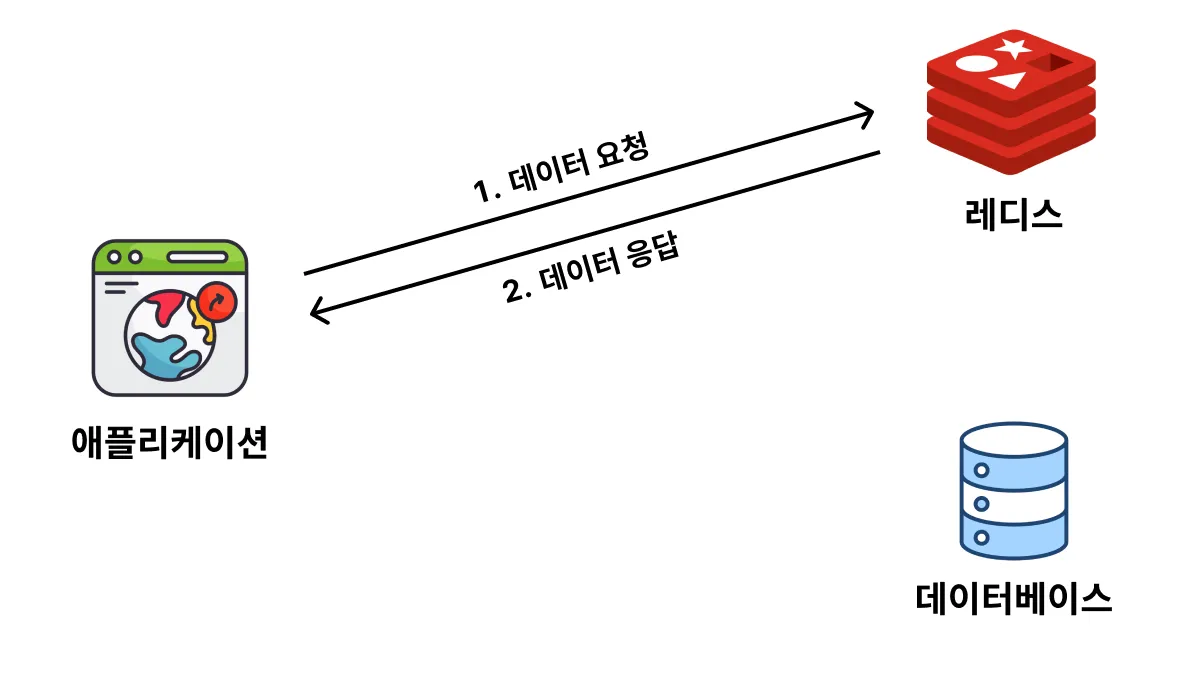
데이터를 요청했을 때, 캐시에 데이터가 있으면 "Cache Hit"
: 데이터베이스보다 캐시에 먼저 "데이터 있어?"하고 물어보고, 데이터가 있으면 데이터를 꺼내와서 응답하고 끝
2. 캐시에 데이터가 없을 경우 (= Cache Miss)
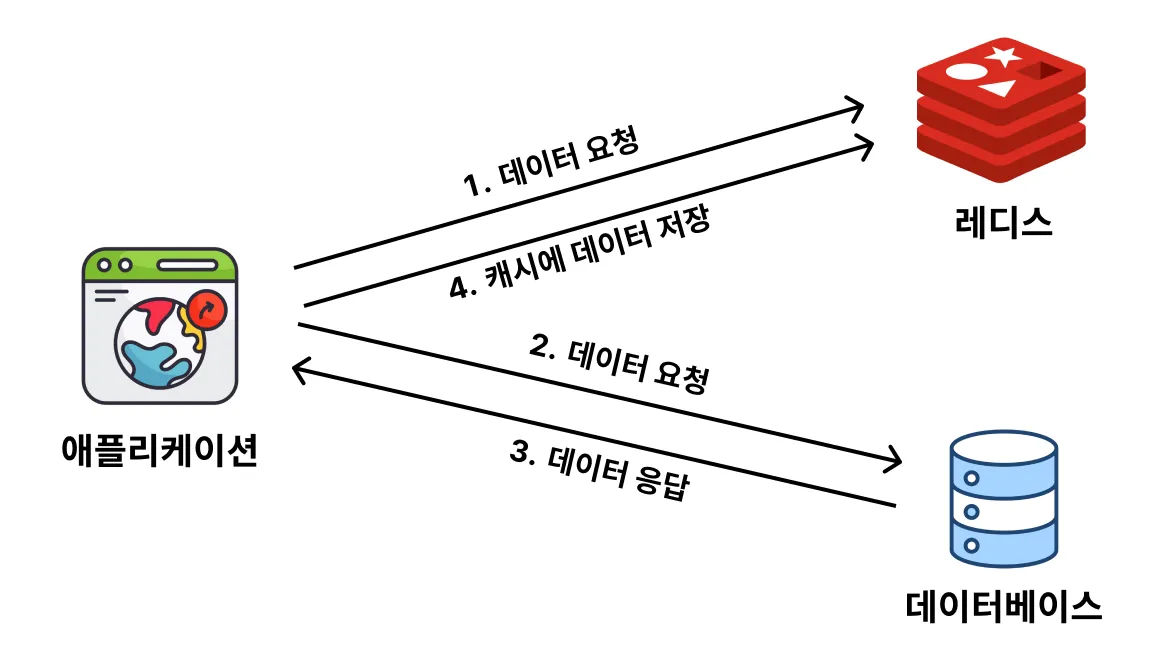
데이터를 요청했을 때, 캐시에 데이터가 없으면 "Cache Miss"
: 데이터베이스보다 캐시에 먼저 "데이터 있어?"하고 물어보고, 데이터가 없으면 그제서야 데이터베이스에서 데이터를 조회해와서 그 데이터를 응답하고, 응답한 데이터를 캐시에도 저장
Why? 다음에 또 해당 데이터를 조회할 일이 있으면, 빠르게 Redis에서 꺼내 쓸 수 있게 저장
Cache Aside 작동 방식
처음으로 개시판 서비스 배포
- 처음 게시판을 배포했기 때문에, 데이터베이스와 Redis에는 비어있음
- 일부 사용자가 들어와 회원가입하고, 게시글을 작성함으로써 데이터 저장
2-1. 이때 데이터는 데이터베이스에 저장(Redis에는 저장 되지 않음, 그렇게 구성) - 사용자가 데이터 조회를 요청
3-1. 이때, 데이터베이스가 아닌 Redis에 먼저 데이터가 있는지 확인 - Redis에 데이터가 없는 걸 확인한 뒤, 데이터베이스로부터 데이터를 조회하여 응답
- 데이터베이스로부터 조회한 데이터를 응답한 뒤, Redis에도 해당 데이터 저장
- 다시 한 번 사용자가 같은 데이터를 조회하려고 요청
- Redis에 조회하고자 하는 데이터가 있는지 확인했더니, 데이터가 존재해서 Redis로부터 데이터를 조회(5번에서 Redis에 (데이터베이스로부터 가져온) 데이터를 저장해두었기 때문에)
Cache Aside 전략 요약
캐시(Cache)에서 데이터를 확인하고, 없다면 DB를 통해 조회해오는 방식
Write Around 전략
Cache Aside 전략 : 데이터를 어떻게 조회할지에 대한 전략
Write Around 전략 : 데이터를 어떻게 쓸지(저장, 수정, 삭제)에 대한 전략
두 전략은 같이 자주 활용됨
데이터 저장 시 Write Around 전략 동작 방식
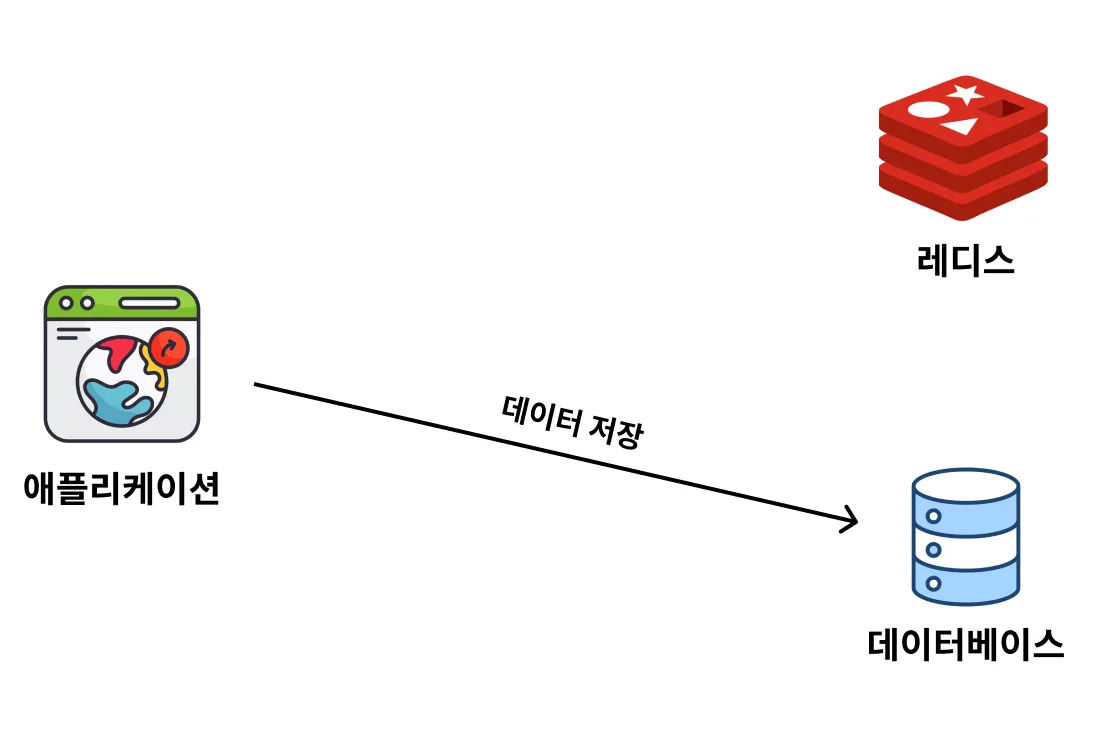
데이터를 저장할 때 Redis에 저장하지 않고, 데이터베이스에만 저장하는 방식
그러다가 데이터를 조회할 때, Redis에 데이터가 없으면, 데이터베이스로부터 데이터를 조회해와서 Redis에 저장하는 방식
(저장 시, 데이터베이스와 Redis에 동시 저장하는 방식도 있지만, 현업에서도 안 씀)
💡오!
Redis 없을 때도, 데이터는 원래 데이터베이스에 저장, 삭제, 수정했으니까, 크게 어렵지 않은 개념!
Write Around 전략 요약
쓰기 작업(저장, 수정, 삭제)을 캐시에는 반영하지 않고, DB에만 작업하는 방식
📢 Cache Aside, Write Around 전략의 한계점 / 해결 방법
Cache Aside, Write Around 전략의 한계점
1. 캐시된 데이터와 DB 데이터 불일치
캐시된 데이터와 DB의 데이터가 일치하지 않는다는 건,
데이터의 일관성을 보장할 수 없다는 것
두 방식을 같이 쓰는 건 현업에서도 많이 쓰는 방식이지만, 데이터를 수정할 때 DB만 업데이트 시키기 때문에 기존에 저장된 Redis의 데이터와 DB의 데이터는 다를 수밖에 없다.
ex) 나의 닉네임을 "안뮤뮤"에서 "안냥냥"으로 바꿨는데, 프로필을 조회해보니 여전히 "안뮤뮤"라고 표시된다면?
- 일단 처음 닉네임을 설정할 때, "안뮤뮤"라고 설정
한 번 조회를 하게 되면, (Redis에는 존재하지 않으니) 데이터베이스에서 이름을 조회했을 것
그리고 Redis에도 "안뮤뮤"를 저장했을 것(Cache Aside)- 닉네임을 "안냥냥"으로 수정
데이터베이스 내의 닉네임 데이터를 "안냥냥"으로 수정
하지만 Redis에는 별도의 작업을 하지 않음(Write Around)
Redis : 안뮤뮤
DB : 안냥냥- 새로 조회하면,
Redis에 데이터가 존재하는지 확인할 것임.(Cache Aside)
Redis는 저장하고 있던 "안뮤뮤"를 반환할 것임
2. 캐시에 저장할 수 있는 공간이 비교적 협소
DB는 디스크(Disk)에 저장해서 많은 양을 저장하기 용이하지만, 캐시는 메모리(RAM)에 저장하기 때문에 DB에 비해 많은 양을 저장 불가능
이건 Redis의 한계점 그자체
이 한계를 어떻게 극복할까?🤔
1. 캐시된 데이터와 DB 데이터 불일치
캐시와 DB의 데이터를 일치시키기 위해, 데이터를 쓸 때마다 Redis와 DB에 동시에 업데이트하면?
→ 데이터는 일치할 것. 그러나 성능이 느려질 것
그렇다고 성능 향상을 위해 DB의 데이터만 업데이트하면 캐시와 DB의 데이터가 불일치할 것
이것은 기회 비용(Trade Off)😶
따라서 데이터 조회 성능 개선 목적으로 Redis를 쓰는 경우에는 데이터 일관성을 포기하고 성능 향상을 택한다. 그럼 Write Around 전략을 고수한다는 건가?🤔
따라서 캐시를 적용하기 위해 적절한 데이터란?
- 자주 조회되는 데이터
- 잘 변하지 않는 데이터
- 실시간으로 정확하게 일치하지 않아도 되는 데이터
잘 변하지 않는 데이터는 캐시된 데이터와 DB의 데이터가 불일치하는 경우가 적으니까
캐시 데이터는 불일치할 가능성이 있기 때문에 일치하지 않아도 되는 데이터에 대해서 캐시 적용
But,
정확하게 일치하지 않아도 되는 데이터라고 할지라도, 장기간 데이터가 불일치하는 건 문제가 될 수 있으므로 적절한 주기로 데이터 동기화 필요
→ Redis의 TTL기능(만료 시간 설정 기능) 활용
동기화? DB의 데이터를 Redis에 저장된(캐시된) 데이터와 일치시키는 것
TTL을 설정하면?
일정 시간이 지나면 데이터는 캐시에서 삭제
그럼 특정 사용자가 조회를 하는 순간 Cache Miss 발생(Cache Aside에 의해)
DB의 데이터를 새로 조회해와서 캐시에 데이터 저장
= 데이터 갱신 → 데이터가 일치
완전히 극복은 아니지만 어느정도 보완 가능
2. 캐시에 저장할 수 있는 공간이 비교적 협소
마찬가지로, Redis의 TTL기능(만료 시간 설정 기능) 활용을 활용하여, 캐시의 공간 효율적으로 사용
자주 조회되지 않는 데이터는 만료 시간에 의해 데이터가 삭제(이후 저장되는 확률이 드묾)
자주 조회되지 않는 데이터는 Cache Miss도 일어나지 않겠지만,
Cache Miss가 일어나서 캐시에 데이터가 저장되더라도
이후로도 자주 조회되지 않기 때문에 캐시에서 데이터가 삭제
→ 즉 자연스럽게 Redis, 캐시라는 공간에는 자주 조회되는 데이터만 남을 것
요약
Cache Aside, Write Around 전략을 사용할 때 주로 TTL을 같이 활용
📢 캐싱으로 조회 성능을 하기 전에 해야 하는 것?🤔
데이터 조회 성능을 개선하는 방법
- SQL 튜닝
- 캐싱 서버 활용 (Redis 등) ,,,배우는 중
- 레플리케이션 (Master/Slave 구조)
- 샤딩
- DB 스케일업 (CPU, Memory, SSD 등 하드웨어 업그레이드)
많은 성능 개선 방법 중 'SQL 튜닝'을 왜 먼저 고려해야 할까?
1. 금전적, 시간적, 관리 비용 발생
SQL 튜닝을 제외한 나머지 방법은 추가적인 시스템 구축 필요
→ 금전적, 시간적 비용 추가로 발생
그리고, 복잡해진 시스템 구조로 인해 관리 및 유지보수 비용 증가
그에 비해 SQL 튜닝은 기존의 시스템 구축 혹은 변경 없이 성능 개선 가능
2. 근본적인 문제 해결 방법
SQL 자체가 비효율적으로 작성되었다면, 아무리 시스템적으로 성능을 개선하더라도 한계 존재
→ SQL 튜닝을 통해 기본적으로 성능을 향상시킨다면 시스템적인 성능 개선이 필요하지 않거나, 훨씬 간단하게 성능 개선 효과
현업 서비스에서는 Redis 캐싱을 쓰면서까지 성능을 극단적으로 끌어올리는 경우는 많지 않고, DB에서 SQL 튜닝만 잘해도 어지간한 성능은 향상
→ 성능이 부족하다고 느껴지면, Redis부터 도입하는 게 아니라 SQL에서 내가 비효율적으로 작성하지 않았는지 먼저 확인!
즉, DB 성능 개선 방법들 중 가장 저렴하고, 효과 있는(가성비가 좋은) 방법이 SQL 튜닝
그 후에도 개선이 필요하고 대안이 필요하면 다른 방안을 고려
이 강사님께서 SQL 튜닝과 관련하여 자신의 또 다른 강의를 추천해주셨다.
비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)
할인하길래 구매해봤다😶 언제 보려나🤧
