작성자 : 강지우
참고 : 16.7. Sequence-Aware Recommender Systems
Sequence-Aware Recommender Systems - Caser 모델의 파이토치 구현코드를 리뷰하겠습니다.
전체 코드는 여기를 참고해주세요😊
Model
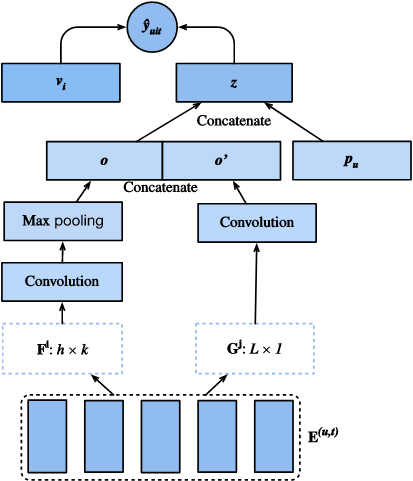
from torch.nn import Conv2d
class Caser(nn.Module):
def __init__(self, num_factors, num_users, num_items, L=5, d=16, # num_factors == k
d_prime=4, drop_ratio=0.05, **kwargs):
super(Caser, self).__init__(**kwargs)
self.P = nn.Embedding(num_users, num_factors) # user's general taste embedding
self.Q = nn.Embedding(num_items, num_factors) # item embedding
self.d_prime, self.d = d_prime, d # vertical / horizontal filter의 갯수
# Vertical convolution layer
self.conv_v = Conv2d(in_channels=1, out_channels=d_prime, kernel_size=(L, 1))
# Horizontal convolution layer
h = [i + 1 for i in range(L)]
self.conv_h, self.max_pool = [], []
for i in h:
self.conv_h.append(nn.Conv2d(in_channels=1, out_channels=d, kernel_size=(i, num_factors)))
self.max_pool.append(nn.MaxPool1d(kernel_size=(L - i + 1)))
self.conv_h, self.conv_v = nn.Sequential(*self.conv_h), nn.Sequential(self.conv_v)
# Fully-connected layer
self.fc1_dim_v, self.fc1_dim_h = d_prime * num_factors, d * len(h) # output dim of vertical conv / horizontal conv
self.fc = nn.Linear(in_features=d_prime * num_factors + d * L, out_features=num_factors) # input : concat of vertical/horzontal conv output, output : z
self.relu = nn.ReLU()
self.Q_prime = nn.Embedding(num_items, num_factors * 2) # another item embedding
self.b = nn.Embedding(num_items, 1)
self.dropout = nn.Dropout(drop_ratio)
def forward(self, user_id, seq, item_id):
item_embs = torch.unsqueeze(self.Q(seq), 1)
user_emb = self.P(user_id)
out, out_h, out_v, out_hs = None, None, None, []
if self.d_prime:
out_v = self.conv_v(item_embs)
out_v = out_v.reshape(out_v.shape[0], self.fc1_dim_v)
if self.d:
for conv, maxp in zip(self.conv_h, self.max_pool):
conv_out = torch.squeeze(self.relu(conv(item_embs)), dim=3)
t = maxp(conv_out)
pool_out = torch.squeeze(t, dim=2)
out_hs.append(pool_out)
out_h = torch.stack(out_hs, dim=1).view(batch_size,-1)
# print(out_v.size(), out_h.size())
out = torch.cat((out_v, out_h), dim=1)
z = self.relu(self.fc(self.dropout(out)))
x = torch.cat((z, user_emb), dim=1) # user_emb : user's general taste embedding
q_prime_i = torch.squeeze(self.Q_prime(item_id))
b = torch.squeeze(self.b(item_id))
res = (x * q_prime_i).sum(1) + b
return res- short-term preference 포착을 위한 vertical / horizontal filter를 적용
- general taste 포착을 위한 user embedding / item embedding
Dataset
class SeqDataset(Dataset):
def __init__(self, user_ids, item_ids, L, num_users, num_items, candidates):
user_ids, item_ids = np.array(user_ids), np.array(item_ids)
sort_idx = np.array(sorted(range(len(user_ids)),
key=lambda k: user_ids[k]))
u_ids, i_ids = user_ids[sort_idx], item_ids[sort_idx]
temp, u_ids, self.cand = {}, np.array(u_ids), candidates
self.all_items = set([i for i in range(num_items)])
[temp.setdefault(u_ids[i], []).append(i) for i, _ in enumerate(u_ids)]
temp = sorted(temp.items(), key=lambda x: x[0])
u_ids = np.array([i[0] for i in temp])
idx = np.array([i[1][0] for i in temp])
self.ns = ns = int(sum([c - L if c >= L + 1 else 1 for c
in np.array([len(i[1]) for i in temp])]))
self.seq_items = np.zeros((ns, L))
self.seq_users = np.zeros(ns, dtype='int32')
self.seq_tgt = np.zeros((ns, 1))
self.test_seq = np.zeros((num_users, L))
test_users, _uid = np.empty(num_users), None
for i, (uid, i_seq) in enumerate(self._seq(u_ids, i_ids, idx, L + 1)):
if uid != _uid:
self.test_seq[uid][:] = i_seq[-L:]
test_users[uid], _uid = uid, uid
self.seq_tgt[i][:] = i_seq[-1:]
self.seq_items[i][:], self.seq_users[i] = i_seq[:L], uid
def _win(self, tensor, window_size, step_size=1):
if len(tensor) - window_size >= 0:
for i in range(len(tensor), 0, - step_size):
if i - window_size >= 0:
yield tensor[i - window_size:i]
else:
break
else:
yield tensor
def _seq(self, u_ids, i_ids, idx, max_len):
for i in range(len(idx)):
stop_idx = None if i >= len(idx) - 1 else int(idx[i + 1])
for s in self._win(i_ids[int(idx[i]):stop_idx], max_len):
yield (int(u_ids[i]), s)
def __len__(self):
return self.ns
def __getitem__(self, idx):
neg = list(self.all_items - set(self.cand[int(self.seq_users[idx])]))
i = random.randint(0, len(neg) - 1)
# user id, time step 만큼의 items, target item, neg item
return (int(self.seq_users[idx]), torch.tensor(self.seq_items[idx]), int(self.seq_tgt[idx][0]),
neg[i])user id, 해당 유저의 time step(L) 만큼의 items, target item, neg item을 반환하는 dataset을 정의합니다.
self.test_seq는 evaluation를 위한 것으로, 각 유저마다 time step만큼의 item을 갖는 array입니다.
Loss
class BPRLoss(nn.Module):
def __init__(self, **kwargs):
super(BPRLoss, self).__init__(**kwargs)
self.sigmoid = nn.Sigmoid()
def forward(self, positive, negative):
distances = positive - negative
loss = - torch.sum(torch.log(self.sigmoid(distances)))
return lossBPR Loss를 사용합니다.
Evaluate
def evaluate_ranking(model, test_input, seq, candidates, num_users, num_items,
devices):
"""
test input : test candidates(key = 유저, val = 유저가 구매한 아이템의 리스트인 dict)
seq : test_seq_iter
candidates : train_candidates 즉 train data의 candidates(key = 유저, val = 유저가 구매한 아이템의 리스트인 dict)
num_users : user수
num_items : item수
"""
ranked_list, ranked_items, hit_rate, auc = {}, {}, [], []
all_items = set([i for i in range(num_users)])
for u in range(num_users):
neg_items = list(all_items - set(candidates[int(u)])) # train data에서 user u가 구매하지 않은 아이템만 모으기
user_ids, item_ids, x, scores = [], [], [], []
[item_ids.append(i) for i in neg_items]
[user_ids.append(u) for _ in neg_items]
x.extend([np.array(user_ids)])
if seq is not None:
x.append(seq[user_ids, :])
x.extend([np.array(item_ids)])
test_data_iter = DataLoader(
ArrayDataset(*x), shuffle=False, batch_size=batch_size, drop_last=True) # test data iter는 batch size만큼 user ids, item ids 넘겨줌
for index, values in enumerate(test_data_iter): # values : (user batch, timestep batch, item batch)
x = [v.to(device) for v in values] # x = [cuda에 올린 item ids]
scores.extend(model(*x).squeeze().tolist())
item_scores = list(zip(item_ids, scores))
ranked_list[u] = sorted(item_scores, key=lambda t: t[1], reverse=True)
ranked_items[u] = [r[0] for r in ranked_list[u]]
temp = hit_and_auc(ranked_items[u], test_input[u], 50)
hit_rate.append(temp[0])
auc.append(temp[1])
return np.mean(np.array(hit_rate)), np.mean(np.array(auc))
# evaluate_ranking(model, test_candidates, test_seq_iter, candidates, num_users, num_items, device)각 유저마다의 hit, auc를 구한 후 이들의 평균을 구하는 함수입니다. 이전 NCF에서와 다른 점은 앞에서 마련해둔 test_seq를 이용해 time step items를 추가하여 model에 넣어준 것입니다.
Train
from tqdm import tqdm
import glob
import os
train_epoch_loss = []
val_epoch_hit_lst = []
val_epoch_auc_lst = []
best_auc = 0
for epoch in tqdm(range(num_epochs)):
train_iter_loss = []
for i, values in enumerate(train_iter):
p_pos = model(values[0].to(device), values[1].to(device).long(), values[2].to(device))
p_neg = model(values[0].to(device), values[1].to(device).long(), values[3].to(device))
loss = loss_func(p_pos, p_neg)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_iter_loss.append(loss.detach().item())
if i%1000 == 0:
print(f'{epoch} epoch {i}th train iter loss: {loss.detach().item()}')
train_epoch_loss.append(np.mean(train_iter_loss))
print(f'{epoch} epoch ALL LOSS : ', np.mean(train_iter_loss))
with torch.no_grad():
model.eval()
# 모든 val data 돌리고 나서 해당 에폭 hit, auc append
hit, auc = evaluate_ranking(model, test_candidates, test_seq_iter, candidates, num_users, num_items, device)
print(f'{epoch} epoch Hit : {hit}, AUC : {auc}')
val_epoch_hit_lst.append(hit)
val_epoch_auc_lst.append(auc)
if auc > best_auc:
best_auc = auc
print(f'New best model AUC : {best_auc}')
if not os.path.exists('seq_model'):
os.mkdir('seq_model')
if os.path.exists('seq_model/best.pth'):
os.remove('seq_model/best.pth')
torch.save(model.state_dict(), 'seq_model/best.pth')
print('best model is saved!')Result
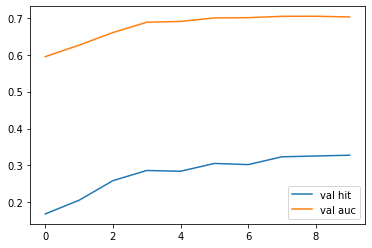
Test data에 대하여 0.7을 넘는 AUC를 보입니다.

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.