작성자 : 강지우
출처 : 16.6. Neural Collaborative Filtering for Personalized Ranking
오늘은 Neural Collaborative Filtering for Personalized Ranking의 구현 코드를 리뷰하겠습니다.
전체코드는 여기에서 확인가능합니다.
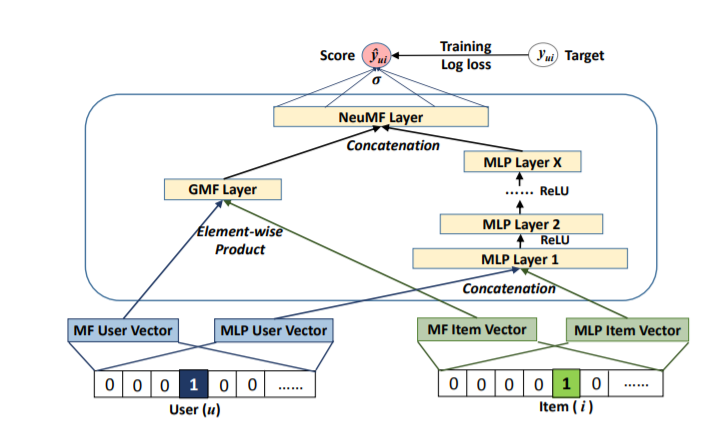
Model
class NeuMF(nn.Module):
def __init__(self, num_factors, num_users, num_items, nums_hiddens,
**kwargs):
super(NeuMF, self).__init__(**kwargs)
self.P = nn.Embedding(num_users, num_factors) # GMF의 user
self.Q = nn.Embedding(num_items, num_factors) # GMF의 item
self.U = nn.Embedding(num_users, num_factors) # MLP의 user
self.V = nn.Embedding(num_items, num_factors) # MLP의 item
layers = []
before_layer = num_factors*2
for num_hiddens in nums_hiddens:
layers.append(nn.Linear(before_layer, num_hiddens, bias=True))
layers.append(nn.ReLU())
before_layer = num_hiddens
self.mlp = nn.Sequential(*layers)
self.prediction_layer = nn.Linear(before_layer*2, 1, bias=False)
def forward(self, user_id, item_id):
p_mf = self.P(user_id)
q_mf = self.Q(item_id)
gmf = p_mf * q_mf
p_mlp = self.U(user_id)
q_mlp = self.V(item_id) # (batch, 1, 10)
mlp = self.mlp(torch.cat((torch.squeeze(p_mlp, 1) , torch.squeeze(p_mlp, 1)), dim=1)) # (batch size, 20) -> (batch_size, 10)
con_res = torch.cat((torch.squeeze(gmf), mlp), dim=1)
pred = self.prediction_layer(con_res)
return nn.Sigmoid()(pred) # sigmoid node는 1, 0~1사이의 값위의 그림의 구조를 가지는 모델 클래스입니다.
- GMF와 MLP부분의 임베딩을 각각 마련
- GMF는 element wise product
- MLP는 concat후 노드수를 줄여가며 dense layer 통과
(NCF 원 논문에서는 64 -> 32 -> 16 -> 8 노드수를 가집니다.) - GMF와 MLP를 concat후 dense layer 통과, 최종 score를 예측합니다.
Dataset
class PRDataset(Dataset):
"""
return user id, 구매한 item id, 구매하지않은 item id
"""
def __init__(self, users, items, candidates, num_items):
self.users = users
self.items = items
self.cand = candidates
self.all = set([i for i in range(num_items)])
def __len__(self):
return len(self.users)
def __getitem__(self, idx):
# 해당 인덱스의 고객이 구매한 아이템을 제외한 전체 아이템
neg_items = list(self.all - set(self.cand[int(self.users[idx])]))
indices = random.randint(0, len(neg_items) - 1)
return self.users[idx], self.items[idx], neg_items[indices]personalized ranking을 위한 데이터셋 클래스입니다.
한 유저에 대한 negative, positive item을 반환합니다.
LOSS
class BPRLoss(nn.Module):
def __init__(self, **kwargs):
super(BPRLoss, self).__init__(**kwargs)
self.sigmoid = nn.Sigmoid()
def forward(self, positive, negative):
distances = positive - negative
loss = torch.sum(torch.log(self.sigmoid(distances)))
return loss위는 Bayesian Personalized Ranking Loss를 구현한 것입니다.
positive와 negative의 상대적인 거리를 넓히는 방향으로 최적화될 수 있게합니다.
평가지표
Hit rate at k
전체 사용자 수 중 예측에 성공한 유저의 수
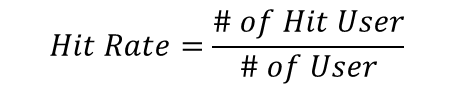
: 전체 유저의 수
: cutoff기준
: 특정 유저
: ground truth 아이템()의 유저 에서의 rank
- 유저마다 구매한 아이템 한개씩 빼놓은 후
- 모델 학습 후 예측
- 예측결과를 소팅 후 상위 l개안에 빼놓았던 아이템이 들어있으면 +1, 이를 전체 유저수로 나눈다.
AUC(D2L Ver.)
: item set
: candidate items of user
: ranking of the ground truth item of user (ideal ranking is 1)
def hit_and_auc(rankedlist, test_matrix, k):
"""
rankedlist : key=user_id, value=(item_ids, scores)인 score순으로 정렬된 dict
test_matrix : test candidates(key = 유저, val = 유저가 구매한 아이템의 리스트인 dict)
k : top k
"""
hits_k = [(idx, val) for idx, val in enumerate(rankedlist[:k])
if val in set(test_matrix)]
hits_all = [(idx, val) for idx, val in enumerate(rankedlist)
if val in set(test_matrix)]
max = len(rankedlist) - 1
auc = 1.0 * (max - hits_all[0][0]) / max if len(hits_all) > 0 else 0
return len(hits_k), auc유저마다 hit, auc를 구하는 함수
rankedlist : 한 유저의 test data에 대한 추천 결과 sort한 것
test_matrix : test set item 리스트
hit rate = 한 유저의 구매할 것이라고 예측된 아이템 중 실제 구매된 아이템 수
auc = (한 유저의 구매아이템 전체 개수 - hit한 아이템의 가장 높은 순위) / (한 유저의 구매아이템 전체 개수)
그런데, 원래 AUC 계산식과 다르다는 의문이 들었습니다.
비슷한 맥락으로 의문을 가진 댓글에 대한 답변은 아래와 같았습니다.
Moreover, in the hit_and_auc function we try to find whether the item the net “recommend” is in the top-k list or what’s the rank of that “recommendation” in the hits_al list(which is sorted by the score given by the net),which is corresponding to the way we calculate the AUC (
find out how many false recommendations rank before the ground truth)
GT의 rank보다 상위 rank에 얼마나 많은 잘못된 아이템을 추천하는지 파악한다는 면에서 일맥상통한다고 말하고 있습니다.
위의 AUC 계산법은 해당 교재에서 AUC라고 이름 붙인 것으로 보입니다. 엄밀한 의미에서 널리쓰이는 AUC와 성격이 다른 듯 합니다.
원래 AUC의 정의에 따른 recsys_AUC
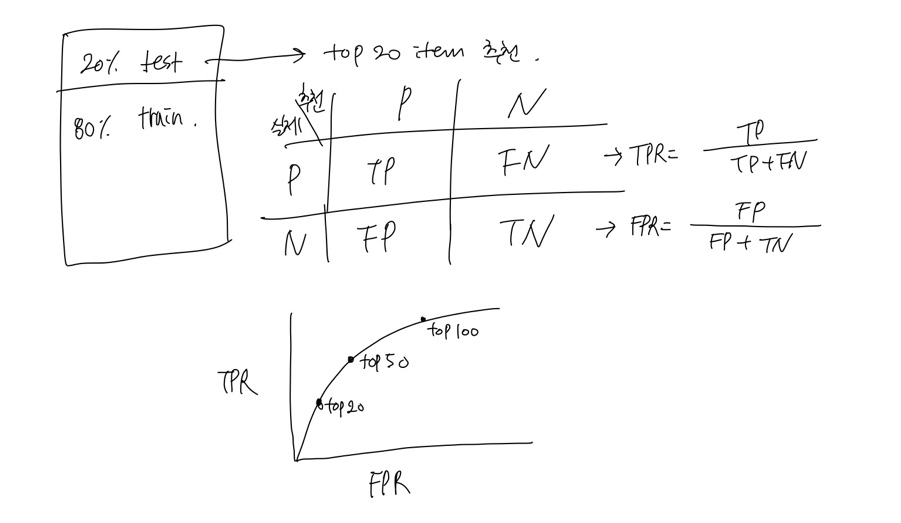
한 유저에 대해 Top-20개 아이템을 추천한다면 train set 80%, test set 20% 설정한 후
80%데이터로 학습 후, 20%의 test set에 대한 구매여부를 예측할 것입니다.
이때 실제 구매를 했으며, 추천도 이뤄졌다면 TP
실제 구매를 하지 않았으며, 추천도 이뤄지지않았다면 TN
실제 구매를 했으나, 추천이 이뤄지지 않았다면 FN
실제 구매를 안했으나, 추천이 이뤄졌다면 FP
이를 통한 FPR, TPR을 구할 수 있을 것입니다. 이제 Top-N에서 N을 바꿔가며 그래프를 그려보면 ROC-Curve를 구할 수 있습니다.
Evaluate
def evaluate_ranking(model, test_input, seq, candidates, num_users, num_items,
devices):
"""
test input : test candidates(key = 유저, val = 유저가 구매한 아이템의 리스트인 dict)
seq : None
candidates : train_candidates 즉 train data의 candidates(key = 유저, val = 유저가 구매한 아이템의 리스트인 dict)
num_users : user수
num_items : item수
"""
ranked_list, ranked_items, hit_rate, auc = {}, {}, [], []
all_items = set([i for i in range(num_users)])
for u in range(num_users):
neg_items = list(all_items - set(candidates[int(u)])) # train data에서 user u가 구매하지 않은 아이템만 모으기
user_ids, item_ids, x, scores = [], [], [], []
[item_ids.append(i) for i in neg_items]
[user_ids.append(u) for _ in neg_items]
x.extend([np.array(user_ids)])
# if seq is not None:
# x.append(seq[user_ids, :])
x.extend([np.array(item_ids)]) # x = [user ids array, item ids array]
test_data_iter = DataLoader(
ArrayDataset(*x), shuffle=False, batch_size=20, drop_last=True) # test data iter는 batch size만큼 user ids, item ids 넘겨줌
for index, values in enumerate(test_data_iter): # values : (user batch, item batch)
x = [v.to(device) for v in values] # x = [cuda에 올린 item ids]
scores.extend(model(*x).squeeze().tolist())
item_scores = list(zip(item_ids, scores))
ranked_list[u] = sorted(item_scores, key=lambda t: t[1], reverse=True)
ranked_items[u] = [r[0] for r in ranked_list[u]]
temp = hit_and_auc(ranked_items[u], test_input[u], 50)
hit_rate.append(temp[0])
auc.append(temp[1])
return np.mean(np.array(hit_rate)), np.mean(np.array(auc))모든 유저에 대한 Hit Rate, AUC를 측정하고 이들의 평균을 반환합니다.
Train
lr, num_epochs, wd, optimizer = 0.01, 10, 1e-5, 'adam'
loss_func = BPRLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = lr, weight_decay=wd)BPR Loss, adam optimizer를 사용합니다.
from tqdm import tqdm
import glob
import os
train_epoch_loss = []
val_epoch_loss_lst = []
val_epoch_hit_lst = []
val_epoch_auc_lst = []
best_auc = 0
for epoch in tqdm(range(num_epochs)):
train_iter_loss = []
for i, values in enumerate(train_iter):
p_pos = model(values[0].to(device), values[1].to(device))
p_neg = model(values[0].to(device), values[2].to(device))
loss = loss_func(p_pos, p_neg)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_iter_loss.append(loss.detach().item())
if i%500 == 0:
print(f'{epoch} epoch {i}th train iter loss: {loss.detach().item()}')
train_epoch_loss.append(np.mean(train_iter_loss))
print(f'{epoch} epoch ALL LOSS : ', np.mean(train_iter_loss))
with torch.no_grad():
model.eval()
val_epoch_loss = 0
for i, values in enumerate(test_iter):
p_pos = model(values[0].to(device), values[1].to(device))
p_neg = model(values[0].to(device), values[2].to(device))
loss = loss_func(p_pos, p_neg)
val_epoch_loss += loss.detach().item()
# 모든 val data 돌리고 나서 해당 에폭 loss, hit, auc append
hit, auc = evaluate_ranking(model, test_candidates, None, candidates, num_users, num_items, device)
val_epoch_hit_lst.append(hit)
val_epoch_auc_lst.append(auc)
val_epoch_loss /= len(test_iter)
val_epoch_loss_lst.append(val_epoch_loss)
if auc > best_auc:
best_auc = auc
print(f'New best model AUC : {best_auc}')
if not os.path.exists('ncf_model'):
os.mkdir('ncf_model')
if os.path.exists('ncf_model/best.pth'):
os.remove('ncf_model/best.pth')
torch.save(model.state_dict(), 'ncf_model/best.pth')
print('best model is saved!')
한 유저에 대한 pos item, neg item에 대한 rating을 예측
둘 사이의 loss를 잰후 loss가 줄어드는(거리가 넓어지는) 방향으로 최적화 하는 과정입니다.
한 에폭마다 hit rate, auc를 측정합니다.
Result
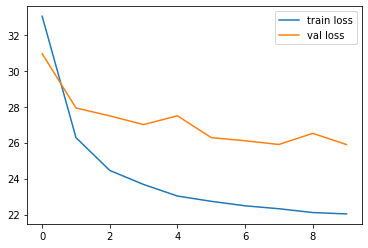
loss가 줄어들며 학습되는 모습을 볼 수 있습니다.
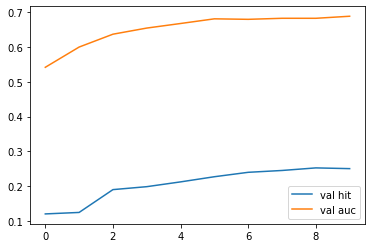
AUC가 0.5를 넘어 0.7 수준까지 올라가는 것을 볼 수 있습니다.
