사용이유?
- 배치간의 데이터 분포 차이가 있는 문제
- 여러 레이어의 연산을 거치면서 각 레이어별로 입력되는 데이터의 분포의 차이가 발생할 수 있고, 이는 학습에 방해가 될 수 있음(Internal Covariate Shift 문제)
=> 배치별로 평균과 분산을 구해서 정규화를 시켜주자.
covariate :
covariate shift :
internal covariate shift :
gradient vanishing, learnig rate와의 관계
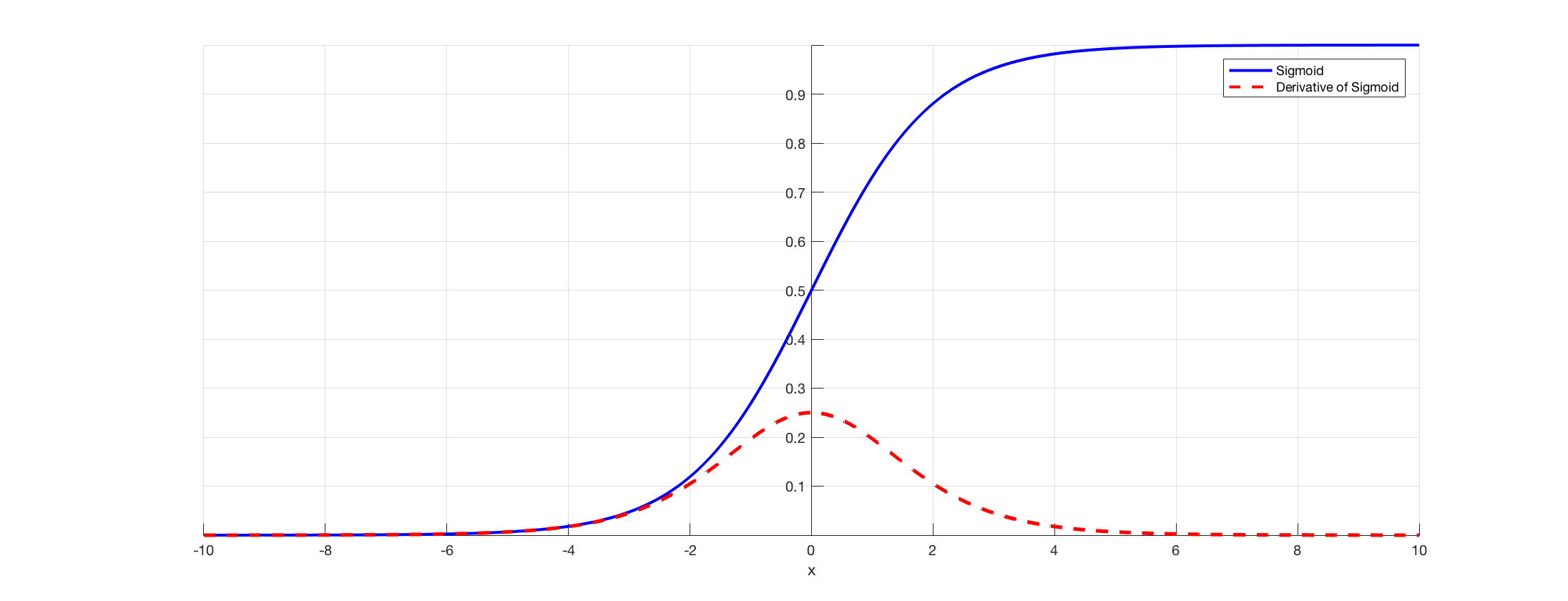
만약에 batch를 뽑아봤는데 sigmoid에서 gradient가 작은 부분인 4이상 영역에만 존재한다고 해보자. 그러면 gradinet vanishing 문제가 유발된다.
-> 이때 BN을 사용하면 배치를 0 근처로 재배치해줄것이고, gradinet vanishing 완화가 가능하다.
-> learning rate관점에서도 데이터가 전체적으로 비슷하게 뭉쳐져 있어서 비슷한 lr을 적용해도 되고, 이는 lr을 보수적으로 작게 설정하지 않아도 되게 함
그러다보니 더욱 수렴이 빨라지고 학습도 잘됌.
BN이 regularization 효과가 있다는 게 뭐지?
https://www.facebook.com/groups/TensorFlowKR/posts/651635698510825/?locale=ko_KR
Regularization
네트워크가 train data에 과적합되지 않도록 randomness를 추가하는 것.
Dropout의 경우엔 일부 뉴런을 특정 확률로 off해서 randomness 추가한다.
BN의 경우엔 하나의 데이터가 여러 무리(minibatch)와 무작위로 묶임. 어떤 친구들과 휩쓸리냐에 따라 매번 정규화 양상이 달라짐(Stochastic Jittering)
https://www.facebook.com/groups/TensorFlowKR/posts/651635698510825/?locale=ko_KR 참고함.
즉 정리하자면
- 정규화를 통해 데이터를 일정 범위로 바꿔서 안정적인 수렴이 가능하여
가중치 초기값 / learning rate의 영향을 덜 받을 수 있다. - 빠른 수렴, 학습 가능
- 랜덤하게 데이터를 묶어서 정규화해서 각 입력의 양상이 다르게할 수 있어서 regularization 효과도 가능
세부적으로 정규화를 어떻게 하는 지?
, 인자

배치의 평균과 분산으로 정규화후 scale factor()를 곱하고 shift factor()를 더한다.
왜 , 를 사용하는가?
평균 0, 분산 1로만 단순히 정규화하는 경우
만약 뒤의 ReLU함수가 배치된다면 음수의 값은 모두 무시될 것이다.
-> 이때 shift를 해준다면 해결가능.
만약 뒤에 sigmoid 함수가 배치된다면 활성화함수의 비선형성을 잃게될 수 있다.
예를 들면 아래 그림과 같이 Sigmoid 함수가 있을 때, 입력 값이 N(0, 1) 이므로 95% 의 입력 값은 Sigmoid 함수 그래프의 중간 (x = (-1.96, 1.96) 구간)에 속하고 이 부분이 선형이기 때문이다. 그래서 비선형 성질을 잃게 되는 것이며, 이러한 성질을 보존하기 위하여 Scale 및 Shift 연산을 수행하는 것이다.

이렇듯 학습에 효율적인 최적의 분포를 만들기 위해 shift, scale factor를 마련하고 조정해준다.
어떤 차원에서 정규화?
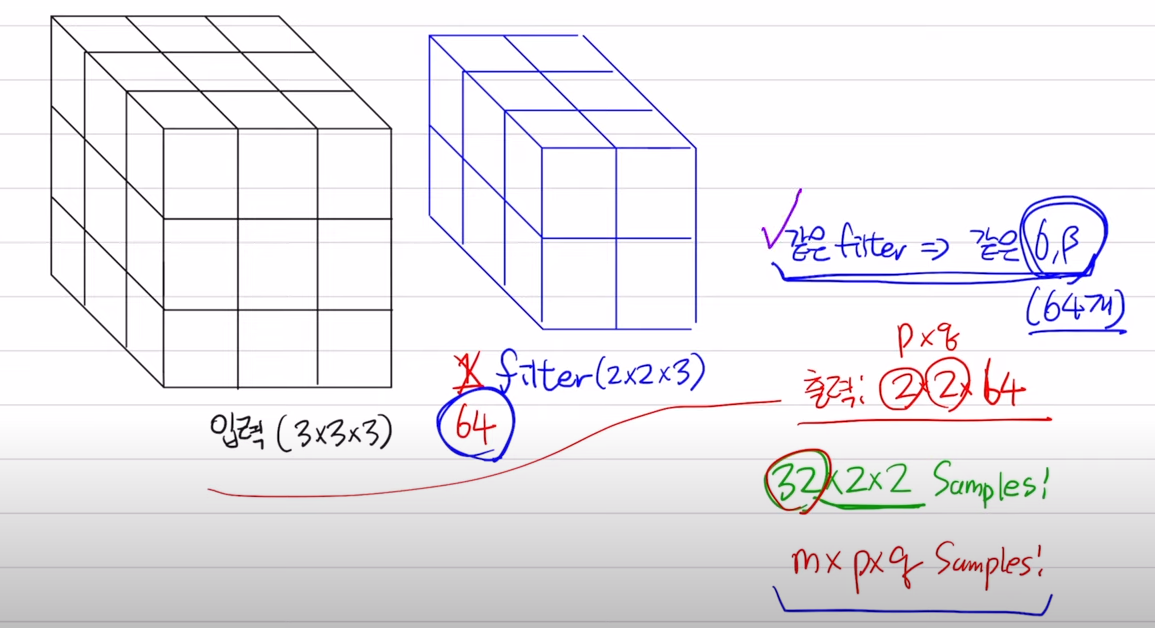
CNN의 경우 필터별 연산 결과를 배치단위로 묶어서 평균낸다.
필터 개수만큼의 감마와 베타를 갖게 되는 것.
3x3x3 입력, 2x2x3필터를 가질때 아웃풋은 2x2가 된다.
-> 배치사이즈가 32라면 위의 연산의 결과물인 2x2아웃풋 32개가 만들어질 것이고 이들을 평균낸다.
-> 즉 필터별로 데이터를 구분해서 평균을 구한다.
train / inference시 차이점
inference시 배치의 평균과 분산을 구할 수 없다.
-> 학습시 저장해둔 평균과 분산을 사용하게 됌
-
모든 평균, 분산을 저장하고 사용하는 방법
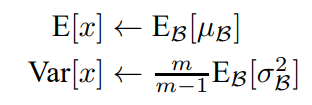
평균의 경우에는 최근 n개 평균의 평균.
분산의 경우에는 최근 n개의 분산에 m/(m-1)를 곱해서 보정해준 분산값을 사용하게된다. -
이동평균을 사용하는 방법
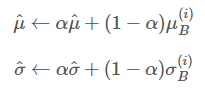
이동평균을 사용하여 모든 배치의 평균/분산값을 저장해두는 것이 아니라 최근 n개의 값을 이용하게 된다.
왜 activation func 앞에 사용하는 거지?
배치 정규화의 목적이 네트워크 연산 결과가 원하는 방향의 분포대로 나오는 것이기 때문에 핵심 연산인 Convolution 연산 뒤에 바로 적용하여 정규화 하는 것이 핵심입니다.
즉, Activation function이 적용되어 분포가 달라지기 전에 적용하는 것이 올바릅니다.
https://gaussian37.github.io/dl-concept-batchnorm/
batch norm은 모든 레이어마다 넣어주는 건가?

그렇다.
각 레이어에 입력되는 데이터의 분포를 맞춰주기 위함이므로.
위의 사진은 resnet의 일부 구조도이다.
batch size가 작을 때 batch norm을 적용해도 되는 것인지?
당연히 안좋다고 한다.
object detection, segmentation의 경우 computation cost때문에 어쩔 수 없이 batch size를 작게 설정할 수 밖에 없는데,
이때 batch단위가 아닌 batch를 누적해 정규화를 실시하는 방법을 사용하기도 한다고 한다.(Cross-Iteration Batch Normalization)
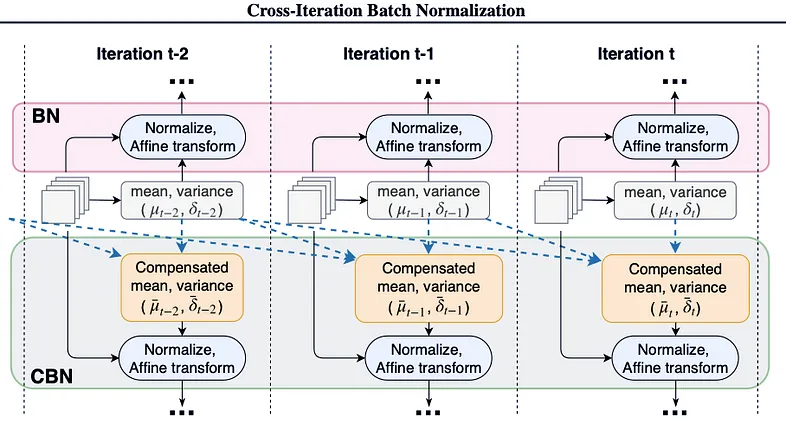
https://eehoeskrap.tistory.com/430
https://gaussian37.github.io/dl-concept-batchnorm/
https://www.youtube.com/watch?v=m61OSJfxL0U

좋은 글이네요. 공유해주셔서 감사합니다.