MobileNet에서 사용된 Depth wise seprable convolution에 대해서 설명한다.
Depth-wise convolution
k = kernel
c = in_channel
m = out_channel
이라고 할 때,
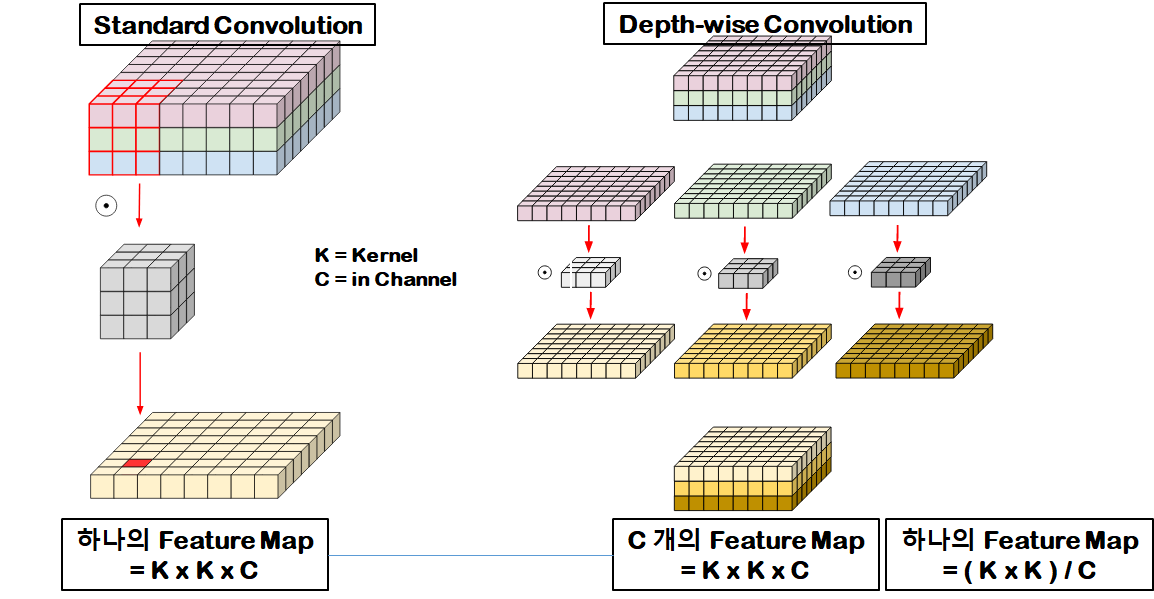
일반적인 convolution은
(k x k x c) x m 개의 parameter를 가진다.
이때 in_channel == out_channel이라면
(k x k x c) x c 개의 parameter를 가지고, c개의 feature map을 얻는다.
depth-wise convolution은
(k x k) x c 개의 parameter를 가지고, c개의 feature map을 얻는다.
c, 즉 in_channel배의 파라미터수를 줄였다.
Q. Deth-wise conv는 꼭 in_channl==out_channel 이어야 하는건가?
-> 맞다! 그 경우에만 성립된다.
separable convolution
separable convolution == 1x1 convolution == point-wise convolution
channel수를 조절할 때 사용된다.
parameter 수는 (1 x 1 x c) x m 개
Depth-wise seprable convolution
위의 두가지를 결합한 것이다.
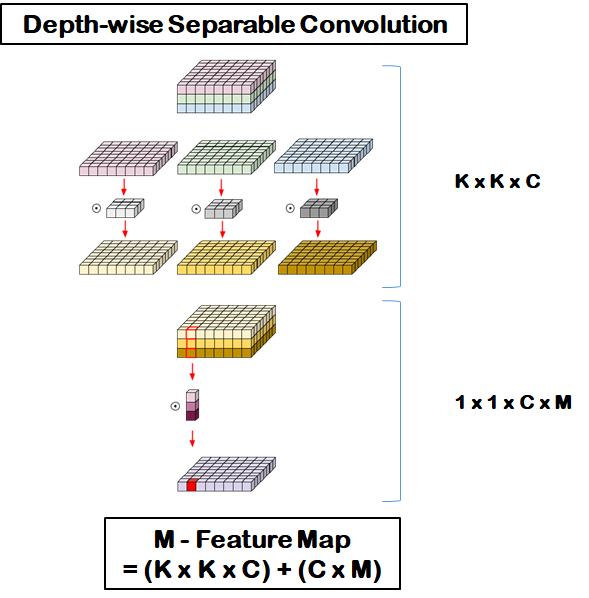
in_channel만큼의 output을 내고 이를 1x1 conv로 채널수를 늘리는 것이다.
즉 (k x k) x c + (1 x 1 x c) x m 개의 parameter를 갖는다.
kkc + cm = c(kk + m)
만약 일반적인 convolution이었다면
(k x k x c) x m
kkcm = c(kkm)
kkm 에서 kk+m으로 덧셈이 곱셈으로 바뀌게 된다.
