[논문 리뷰] Multi-Modal Dialog State Tracking for Interactive Fashion Recommendation
머신러닝/딥러닝 지식
MULTI-MODAL INTERACTIVE RECOMMENDATION
Multi-Modal Interactive Models

Multi-Modal Interactive Models이란 유저와 recommender system이 상호작용하며 유저가 원하는 상품을 찾는 것이다.
위의 사진과 같이
유저는 찾고 싶은 target item이 있고,
추천모델은 추천한 아이템에 대한 유저의 text feedback을 기반으로 다시 추천을 제공한다. (과거에 추천한 아이템을 제외하고 추천한다.)
이 과정을 유저가 원하는 상품을 찾을 때까지 반복한다.
limitations
기존의 Multi-Modal Interactive Model은 RNN계열(GRU, LSTM 등), Transformer 계열의 모델을 이용한다.
이러한 모델들은 하나의 modality를 처리하기 위한 모델이기에, image와 text를 동시에 처리하기 위해 이들을 concat하여 처리하는 것이 일반적이다.
이럴 때 다음과 같은 한계점이 발생한다.
limitation 1
첫번째 한계점은 기존 GRU/LSTM-based model이 multi-modal 정보를 단순히 concat하며 처리하기에 각각의 modality를 처리하는 측면이 부족하다는 것이다.
limitations 2
두번째 한계점은 기존 transfomer-based model은 original image와 text를 인풋으로 하여 과거부터 현재까지의 dilag state의 abstract representation을 파악하는 것이 부족하다는 것이다.
THE MMRAN MODEL
MMRAN 모델은 아래의 세 가지 요소로 구성된다.
Text & Image encoder
Text Encoder
text encoder는 1D-CNN이고,
유저의 natural language feedback은 이며, 사전에 구축된 패션관련 단어사전을 이용하여 각 단어의 one-hot vector가 입력이 된다.
수식으로는 이 되겠다.
BERT와 같은 모델을 사용하지 않은 이유는
1. 연구들과 같은 조건에서 비교하기 위해서,
2. 구축되어 있는 패션 단어사전이 BERT에 비해 더 규모가 작고 패션 분야에 집중되어 있기 때문이라고 한다.
Image Encoder
이미지 인코더는 pre-trained ResNet101을 사용한다.
이전 추천 결과였던 이미지는 이고 이를 인코딩한다.
GRN
Gated Recurrent Network(GRN)은 기본적으로 LSTM의 구조와 유사하다.
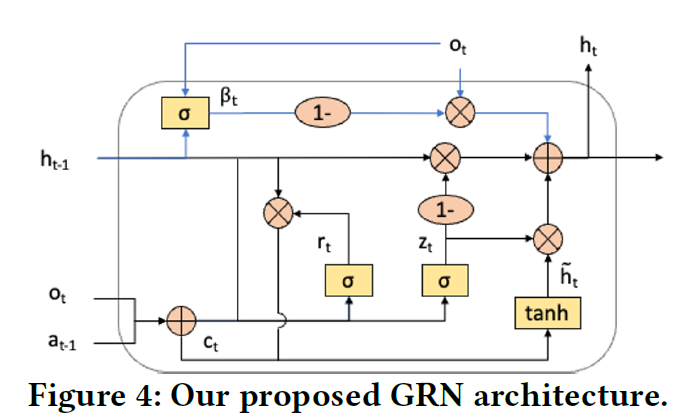
feedback gate
는 현재 textual feedback인 의 영향력을 조절하는 게이트이다.
이는 현재 textual feedback와 이전 hidden state의 관계성을 파악한다.
는 이전 스텝의 visual recommendation 과 현재 스텝의 text feedback의 representation이다.
,
와 는 각각 update gate, reset gate로 와 의 관계성을 파악한다.
는 앞선 와 게이트를 이용하여 임시 hidden state를 만든 것이다.
앞선 요소를 모두 이용하여 최종 hidden state를 만든다.
MAN
Multi-head Attention Network(MAN)은 모델이 multi-modal interactions의 전체 history를 고려할 수 있도록 한다.

앞선 GRN의 hidden state는 MAN의 입력이 된다.
최종 state는 다음과 같이 얻어진다.
최종 state의 softmax distribution이 가장 가까운 K nearest neighbor를 최종 추천하게 된다.
Training
User Simulator
MMRAN모델을 학습하기 위해선 유저의 피드백이 필요하다. 저자는 유저 피드백 대화를 만드는 것이 비용이 많이 드는 작업이기에 user simulator를 이용한다.
VL-Transformersm를 이용하는데, 이는 candidate image와 target image의 차이점을 파악하고 이에 대한 caption을 생성한다.
은 caption을 위한 word sequence를 뜻한다.
Triplet Loss
MMRAN을 학습하는 데에 triplet loss를 사용한다.
는 positive item, 는 negative item, m은 margin을 의미한다.
EXPERIMENT

RQ1
MMRAN이 다른 모델에 비해 SOTA성능을 확보했는가?
GRU,LSTM,Transformer 계열의 여타 다른 모든 모델에 비해 우수한 성능을 보인다.
RQ2
GRN 구조가 Limitation1을 해결하여 multi-modality를 잘 처리했는가?
MAN구조가 없는 MMRAN w/o MAN 모델이 DM-LSTM, DM-SL models(RNN계열 모델)에 비해 모든 metric에서 높은 성능을 보인다.
extra feedback gate가 성능차이의 핵심이라고 판단된다.
RQ3
MAN 구조가 Limitation2를 해결하여 dialog state를 더욱 잘 tracking하는가?
MMIT(transformer계열모델)에 비해 유의미한 성능향상을 보이며
과거 interection의 representation을 GRN으로 추출해 입력한 것이 본래 image/text representation을 입력으로 한 것에 비해 더욱 좋은 성능을 보인다.

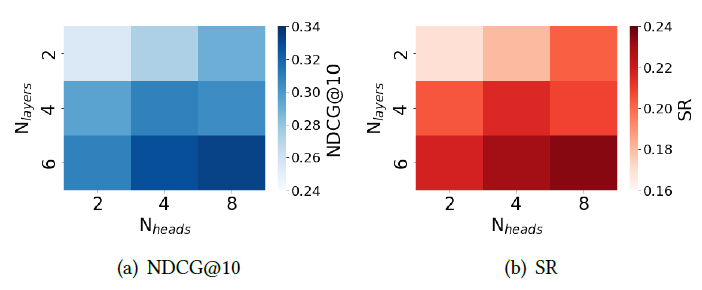
MAN에서 layer 개수는 6, head 개수는 8일때 가장 성능이 좋았다고 한다.
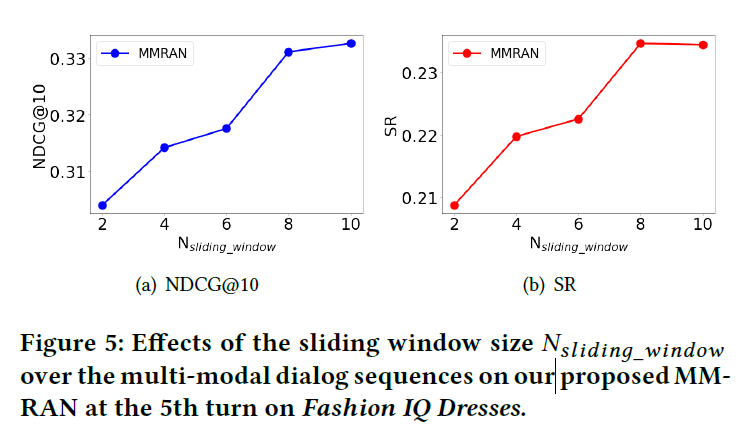
sliding window size가 클수록 좋은 성능을 보인다.
