
EDA
- EDA란 맞고 틀린 게 없는 서술형 답안같은것
- 내가 알고싶은 것을 PYHTON, Excel, 직접 눈으로 등등 보는 것이 모두 EDA다.
마스크 데이터셋에서 내가 궁금한 것은
-
인풋 아웃풋
한사람당 7장의 사진.
다른 종류의 마스크 착용사진 5개, 코스크 or 턱스크 1개(incorrect), 아무것도 안쓴 사진 1개 -
데이터셋의 구조
파일은
id_gender_race_age_mask1~5
id_gender_race_age_incorrect_mask
id_gender_race_age_normal
으로 구성
-> 변수별로 따로 모델을 구성한다고 하면 각 사람들의 폴더경로에서 해당변수의 label을 추출해야한다.
- 데이터의 클래스별 분포
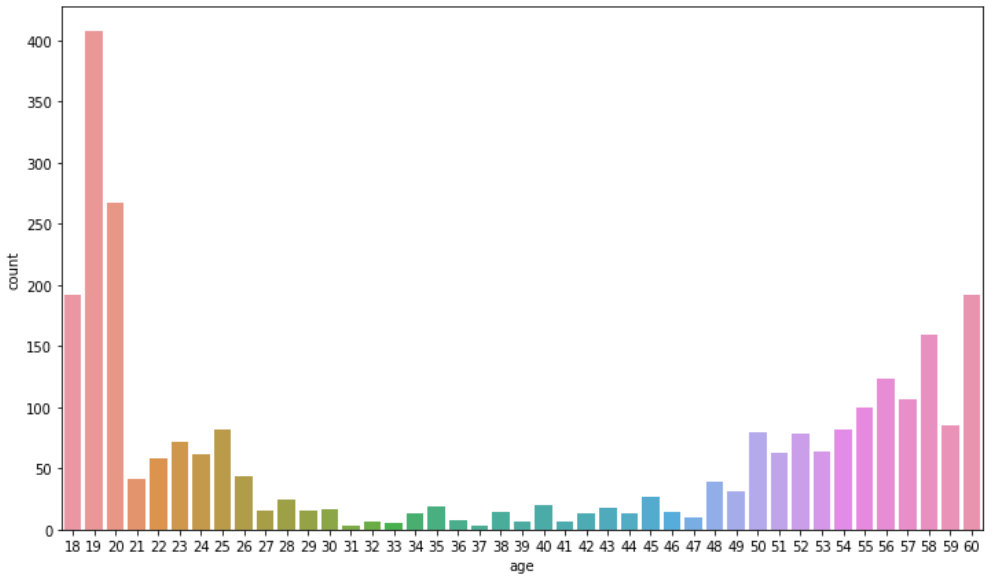
20대 이하가 가장많다. 제일 적은 데이터는 3~40대 50장 이하임 다른 연령대에 비해 7배?는 더 적은듯
3~40대 예측이 힘들 것 같다.
-> 불균형한 데이터를 보완하는 sampler, loss에서 가중치주는 방법을 써볼 수 있다.
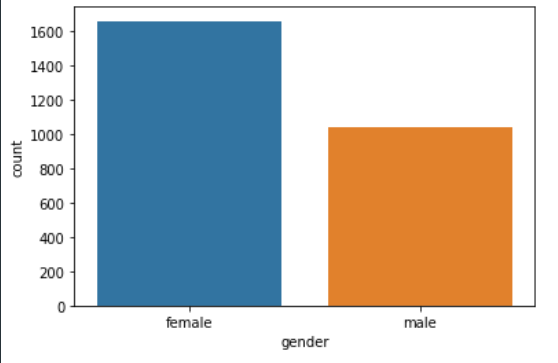
성별도 1:1은 아님
-
incorrect와 아예 안쓴 것의 차이
incorrect는 코가 안가려져 있거나 코, 입이 안가려져 있음 -
마스크의 종류는 한가지인가?
아니다. 마스크 착용 사진 5장이 모두 다른 마스크이며 사람마다 종류는 다 다르다. 두건과 같은 종류도 있다. -
중복되는 이미지가 있는지?
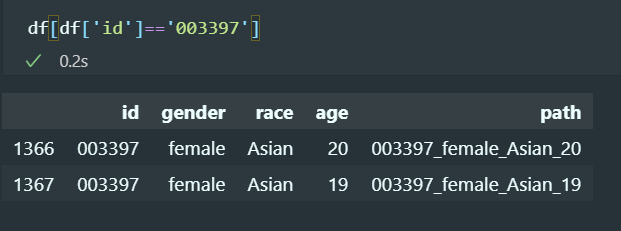
한장 있음
- 이미지의 크기
size = (384, 512)
cnt = 0
img_dir = '/opt/ml/input/data/train/images'
for idx, d in enumerate(os.scandir(img_dir)):
if os.path.isdir(d.path) and not d.name.startswith('.'):
for f in os.scandir(d.path):
if os.path.isfile(f.path) and not f.name.startswith('.'):
im = Image.open(f.path)
if im.size == size:
cnt += 1
print(f.path)모두 사이즈가 (384, 512)

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.