
LOSS
label smothing loss
train, eval
- model.train()
- model.eval() : dropout, batch normalize시 꼭 필요
- with no grad
model, loss, optimizer
위의 3요소가 어우러져서 학습이 이뤄진다.
model의 파라미터를 받아서 loss측정하고 loss.backward()해서 파라미터의 grad update
optimzer에서 업데이트된 grad를 정의된 방법에 맞춰서 optimizer.step()
gradient accmulation
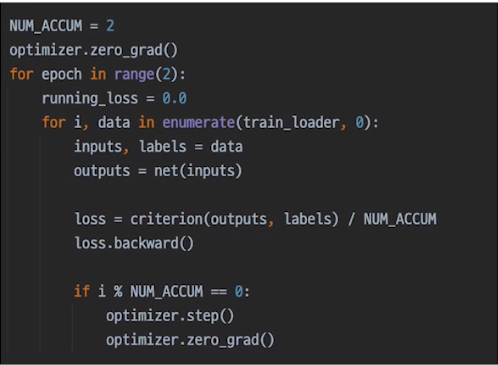
valloss로 체킹하며 저장
.png)
voting
- soft voting : 각 모델이 예측한 확률을 평균내서 예측
- hard voting
cross validation
TTA
여러 변형을 준 테스트 데이터에 대한 예측을 보팅해서 최종 예측
Hyperparameter tuning
- optuna
training visulization
- wandb
- tensorflow board
jupyter, idle
- idle 는 main에 config 정의하고 한번에 똭 돌림
귀중한 tip
- 캐글 노트북 볼 때 코드보다 설명글을 주의 깊게 봐라
- 캐글 노트북 볼 때 작은 부분부터 이해하면서(ex. .loc슬라이싱) 봐라 그래야 나중에 자신의 코드를 짤때 응용가능하다.
- paper with codes
- 공유하면서 성장할 수 있다.

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.