
Semantic segmentation
픽셀단위로 분류하는 것
인스턴스 단위가 아닌 semantic category를 파악
semantic segmentation architectures
Fully Convolutional Networks(FCN)
- end to end
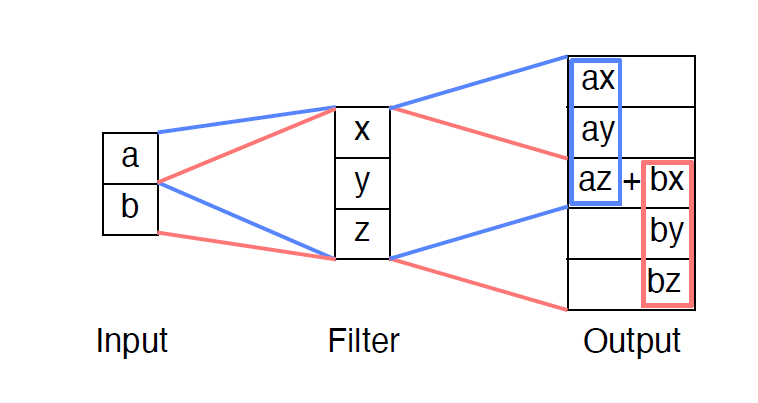
Fully connected layer vs Fully convolutional network
- fc layer : 공간정보 반영 x
- fully convolution layer : 1x1 커널 사용, 공간 정보 반영
Upsampling
-
Transposed convolution
중간중간 규칙적으로 겹치는 부분이 있어 체크보드 무늬가 형성된다.(Checkerboard artifacts) -
Upsampled and convolution
Checkerboard artifacts를 피하는 방법은 upsampling(unlearnable) -> conv(learnable)하는 것이다.

그래서 FCN은 Upsampled and convolution을 사용한다.
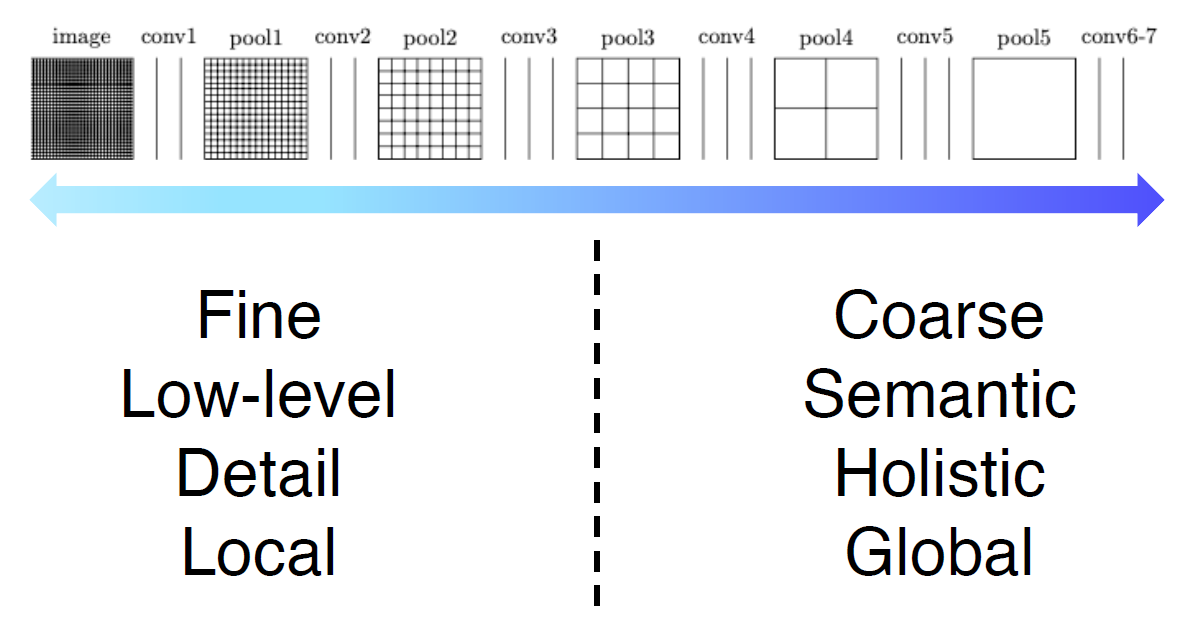
Low layer에서는 국소적인 부분
High layer에서는 receptive field가 넓어져서 넓은 부분을 볼 수 있다.
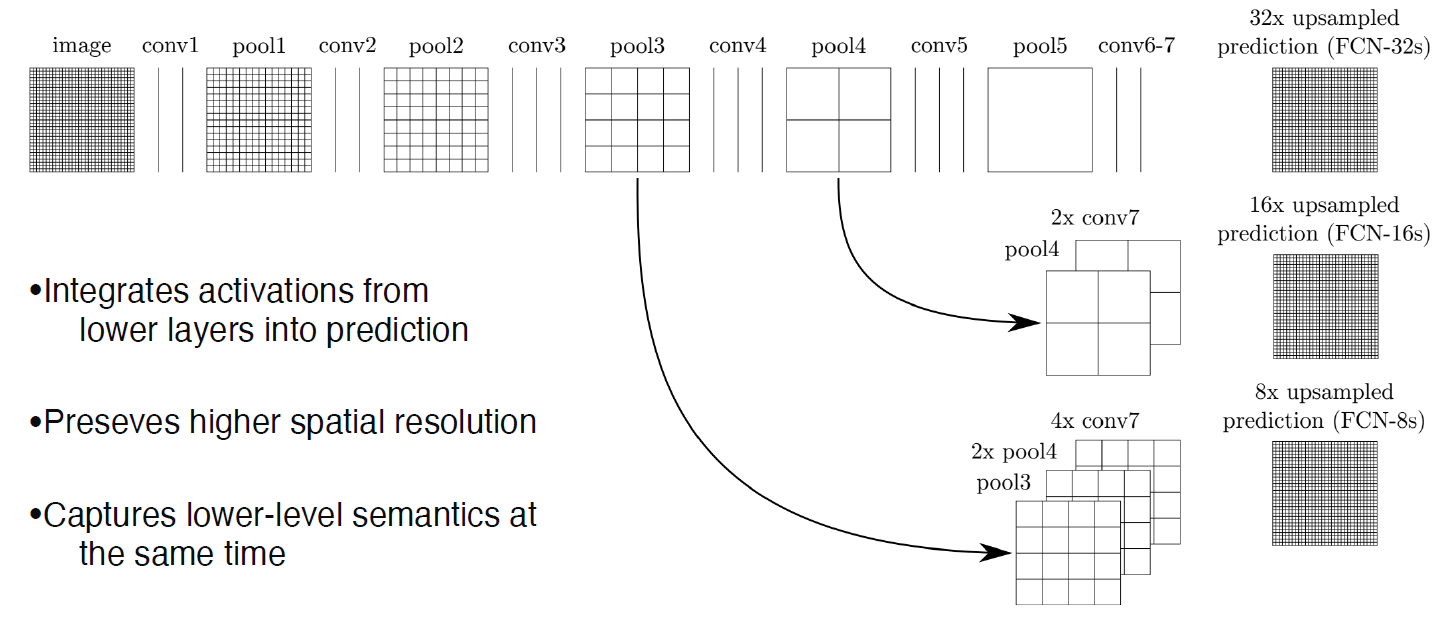
- 그래서 중간 레이어, 말단 레이어를 concat해서 upsampling해서 output 생성
Hypercolumns for object segmentation
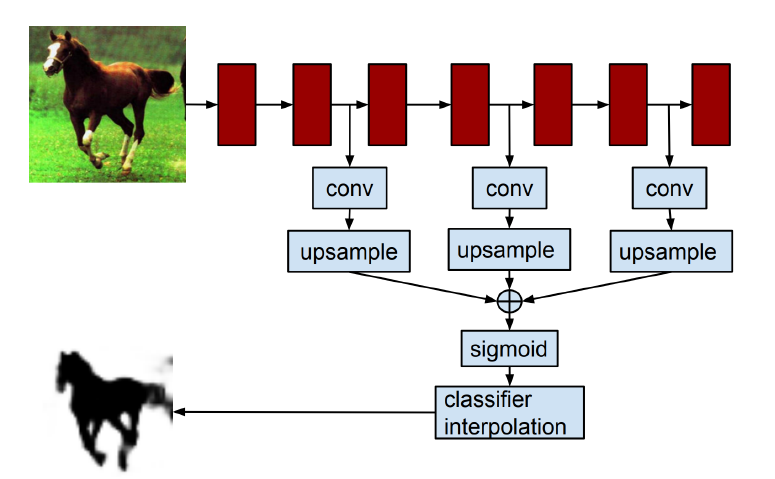
해당 논문도 중간, 말단 레이어를 합치는 시도
그러나 전처리를 따로 해서 넣어야 했다.
U-Net
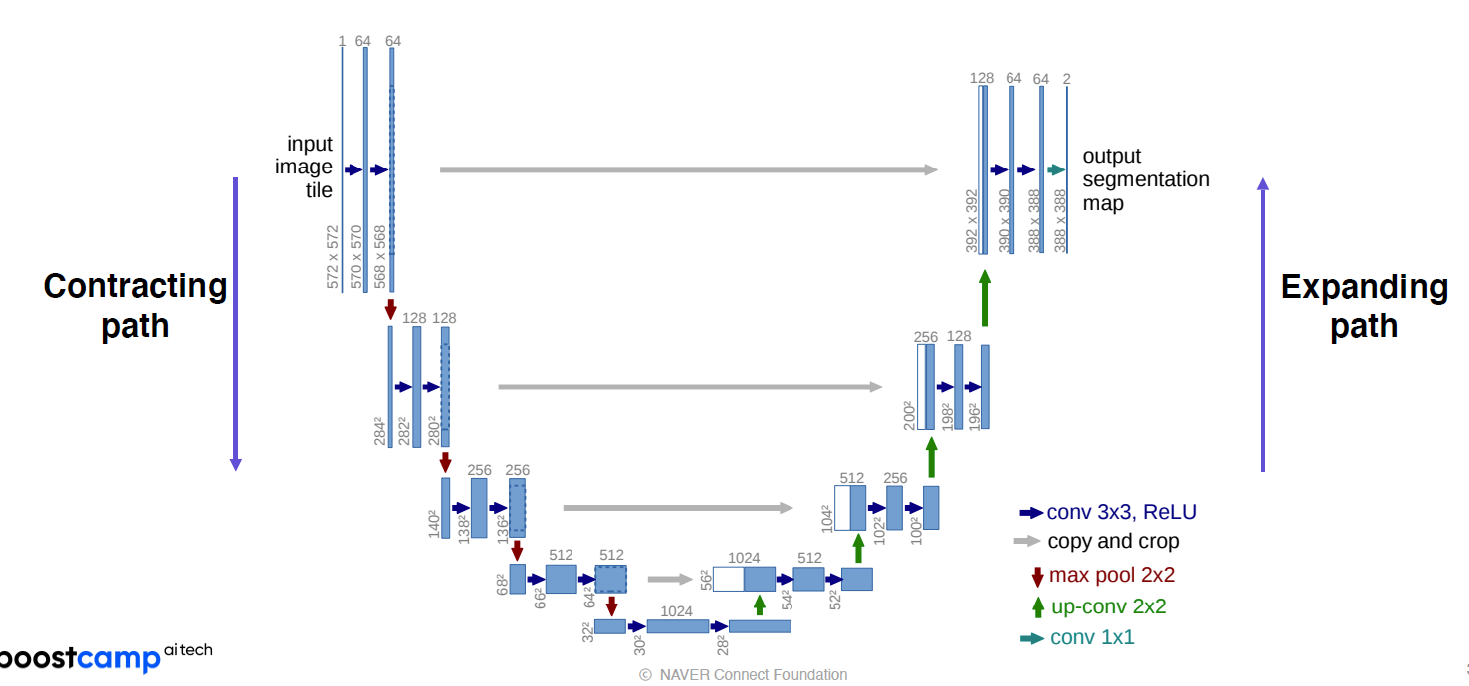
위는 전체 구조 대칭적이다 줄였다 늘렸다하는 구조
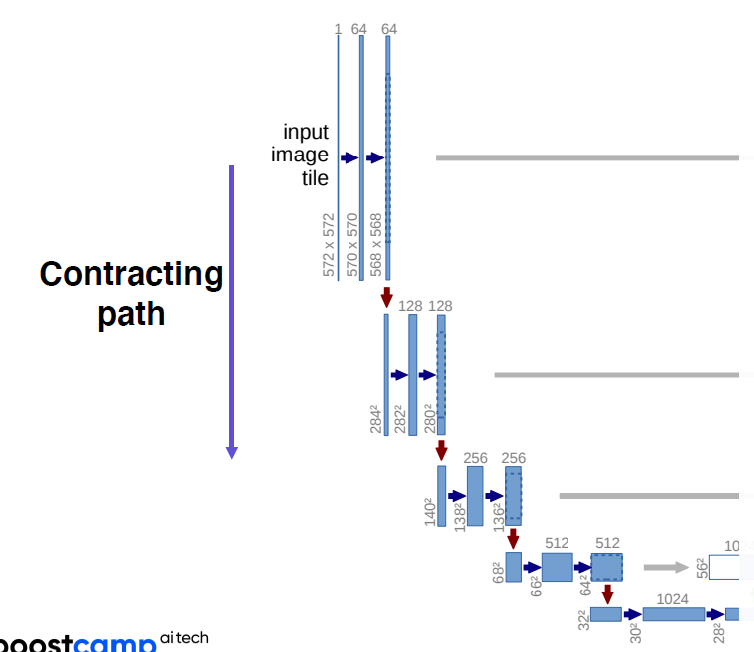
- 내려갈수록 채널은 늘어나고
- 피쳐맵은 줄어든다
- 일반적인 conv
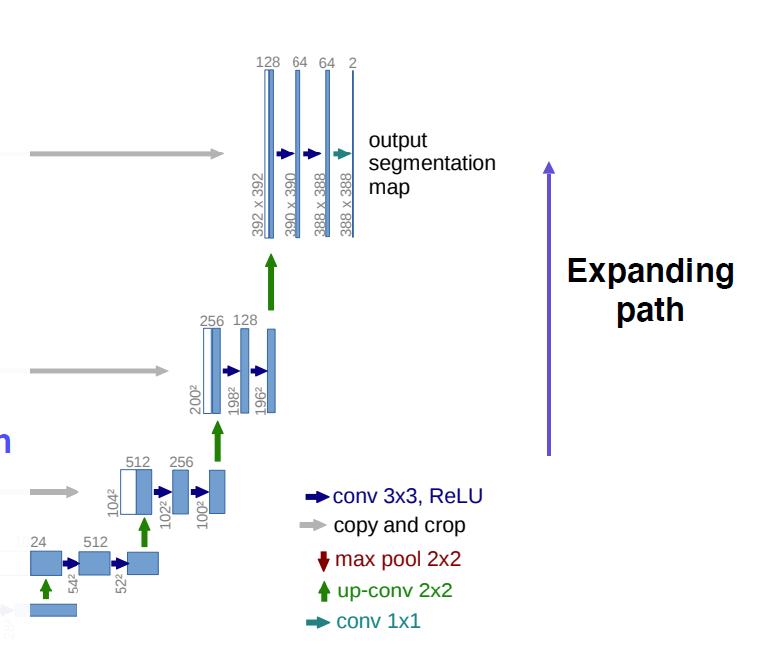
- 올라갈수록 채널 줄어들고
- 피쳐맵은 커진다
- 이때 encoder에서의 해당단계의 피쳐맵을 concat
-> localized information 제공 - 주의할점
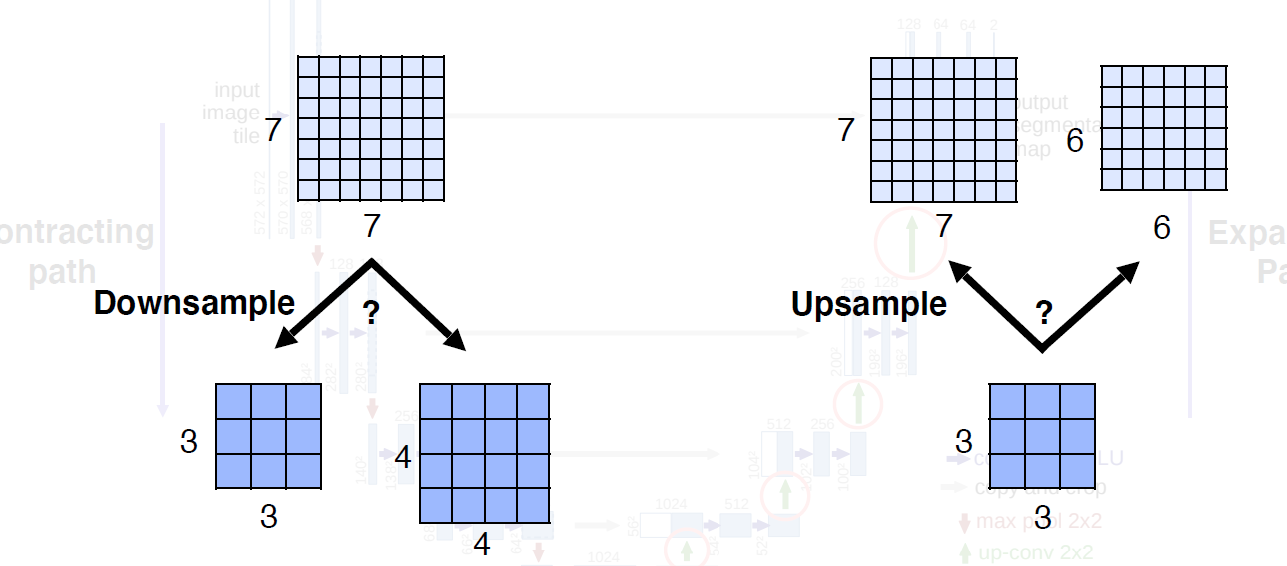
어떤 단계에서든 홀수크기의 피쳐맵 형성하면 안된다
concat할때 안맞는다
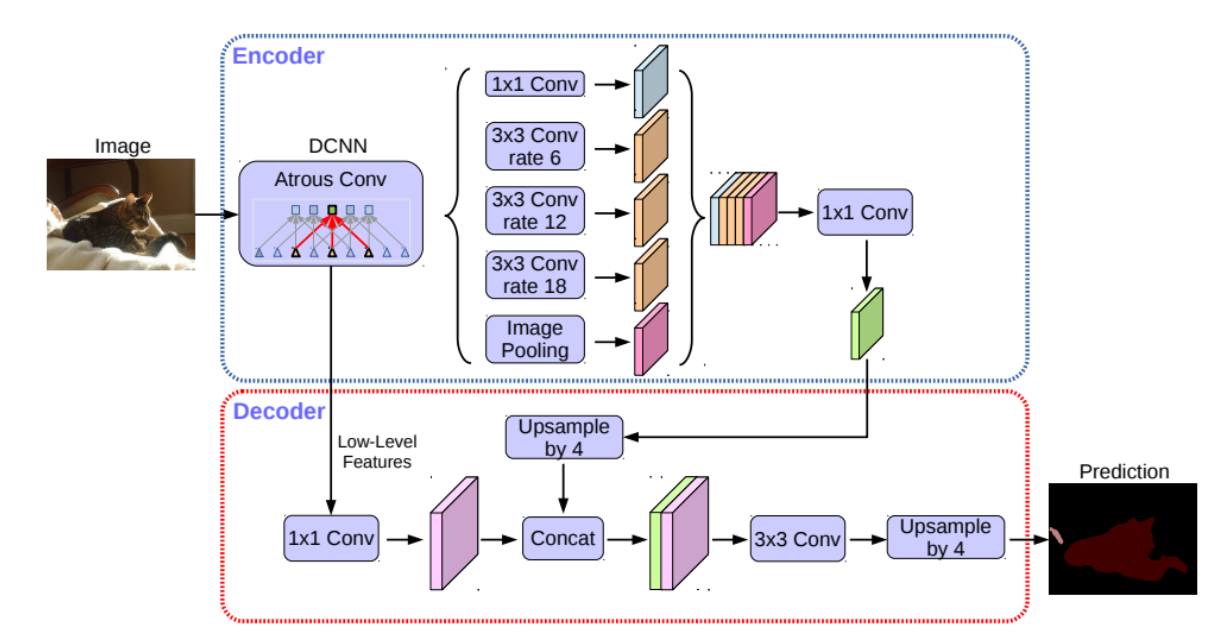
DeepLab
- Conditional Random Fields (CRFs)
- Dilated convolution
- Depthwise separable convolution
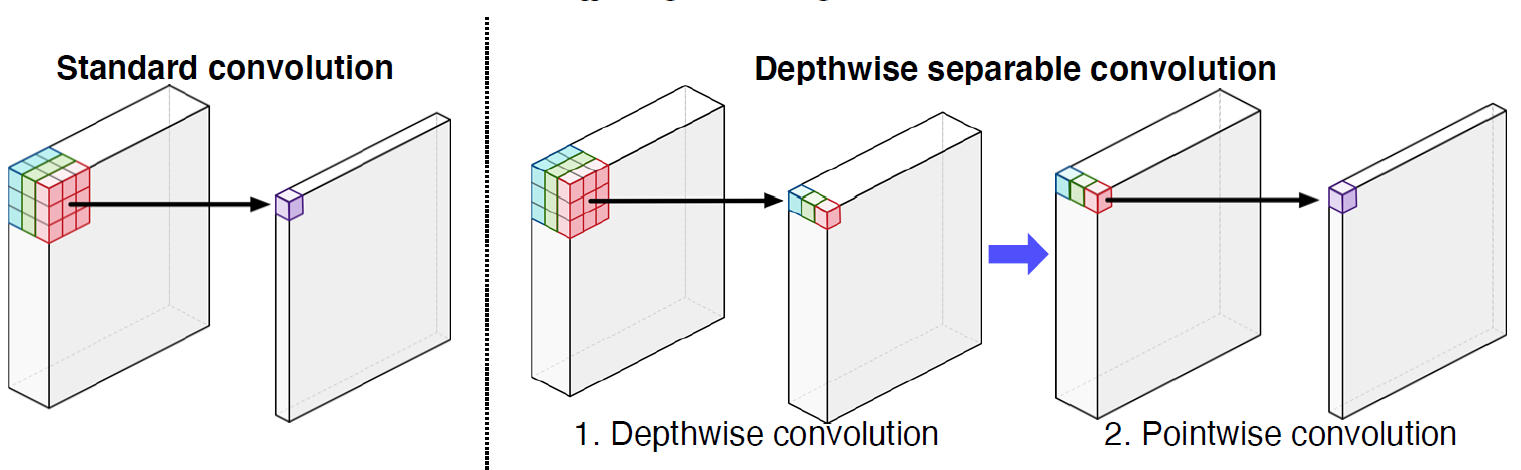
채널마다 내적후 1x1 conv 적용, 비로소 하나의 채널로 합쳐짐
Deeplab v3+
- Dilated convolution
- Depthwise separable convolution
두 요소 사용
과제
-
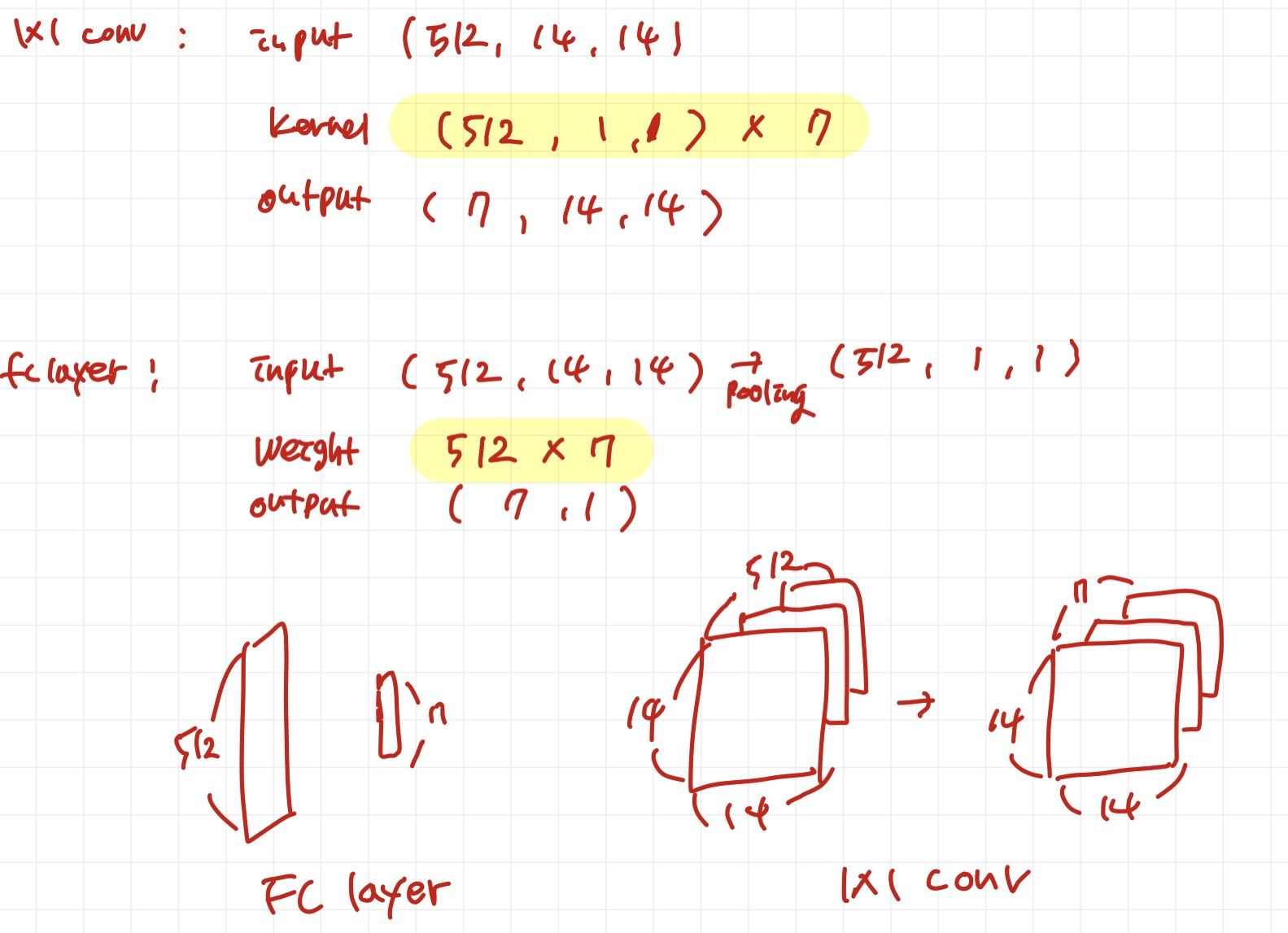
vgg backbone -> gap -> classifier(num_class)
-
vgg backbone -> 1x1 conv
둘의 weight 크기는 같다.
1의 weight를 2의 1x1 kernel의 weight로 넣어준다.
아래의 인풋은 vgg output을 말한다.
추가 problem shooting
-
layer의 weight는 layer.weight로 받으면 된다.
nn.parameter 객체가 반환된다. -
weight를 지정할때는 parameter객체를 넣어야한다.
(torch.reshape을 해주니까 tensor가 되어서 이걸 parameter로 바꿔야했다.) -
그런데 weight에서 bias는 어떻게 되는 거지?
bias=True가 디폴트인데,,
-> Linear source code에서 보면 알 수 있듯이 bias, weight는 layer 모듈의 attribute이고, parameter 객체이다.
