Visualizing CNN
what is CNN visulaization
- CNN이 어떻게 잘 동작하는 것인지 살펴볼 수 있다.
- 하나의 디버깅툴이다.
Vanila example : filter visualization

activation을 관찰하려면 초반에 3채널을 가질 때 시각화해야 해석이 용이하다.

필터를 시각화할 수 있다.
필터는 초반에는 색깔, edge같은 특징을 잡는다.

학습이 진행되며 더 상세한 특징을 잡는다.
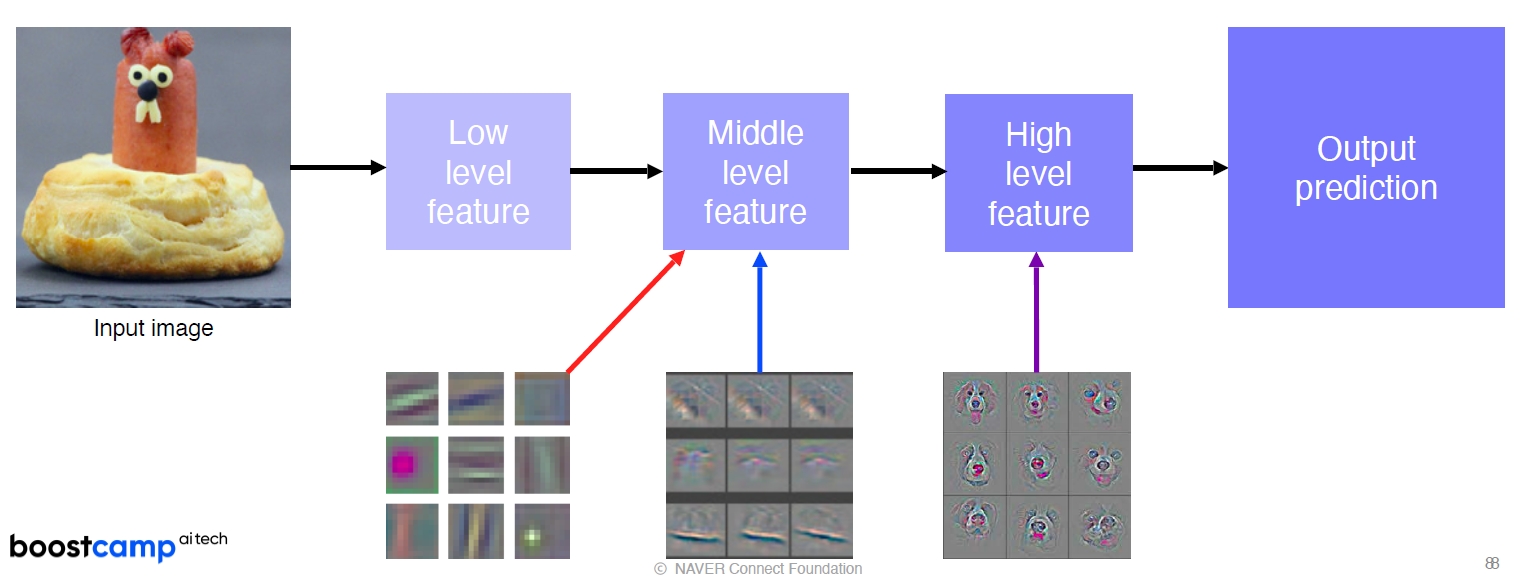
How to visualize neural network
무엇을 관찰하려는지에 따라 모델의 초반부, 후반부 어디에서 시각화가 이뤄지는지도 달라진다.

Analysis of model behaviors
Embedding feature analysis
feature embedding을 관찰하는 것은 고수준의 표현을 관찰하겠다는 것임

- Nearest neighbors in feature space
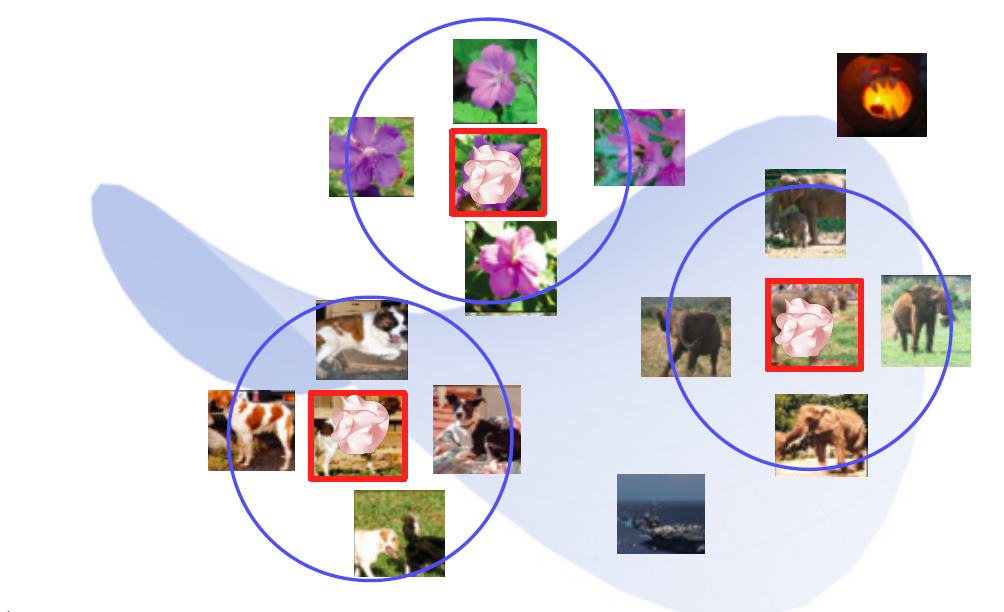
- t-SNE
차원축소를 이용한 것.

Activation investigation
Layer activation
Behaviors of mid- to high-level hidden units
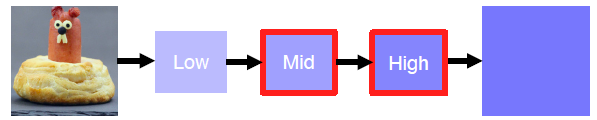
이는 중~후반부를 관찰하는 것

높은 activation을 갖는 부분의 마스크를 시각화
Maximally activating patches
가장 큰 activation을 갖는 노드의 receptive field부분의 이미지 패치를 시각화

Class visualization
Generate a synthetic image that triggers maximal class activation
큰 activation을 끌어내는 방향으로 학습(gradient ascent)하여 이미지 생성
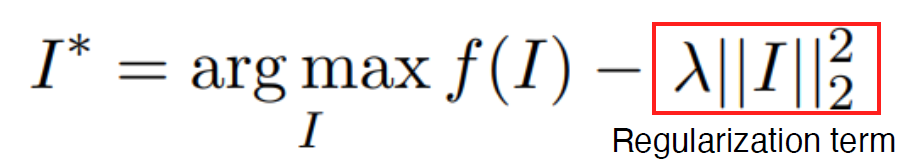
f(I) : 모델에 이미지를 넣은 결과
뒷단에 규제항을 추가하여 0~255를 크게 넘어서지 않도록 조절
1) 더미 이미지를 넣어서 우리가 집중하려는 class의 score를 얻는다.
2) 인풋이미지에 대해서 score가 커지는 방향으로 backpropagation한다.
3) 이미지 업데이트
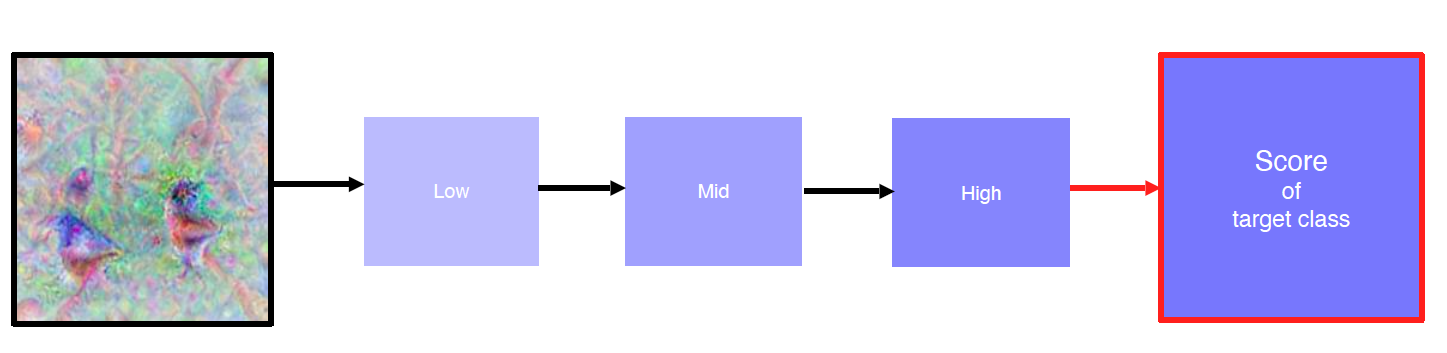
Model decision explanation
Saliency test
Occlusion map
이미지 일부분 가리고 예측 스코어를 본다.
중요한 부분을 가리면 스코어가 작아진다.
모든 픽셀에 대해서 스코어를 예측하고 시각화하면 스코어가 낮은 부분이 중요한 부분이 된다.

via Backpropagation
1) 타겟 이미지에 대한 집중하려는 클래스의 스코어를 얻는다.
2) 클래스 스코어로부터 각 픽셀에 대해 backpropagate
3) gradient magnitude map 시각화(그래디언트를 축적하는 방식으로도 할 수 있다.)
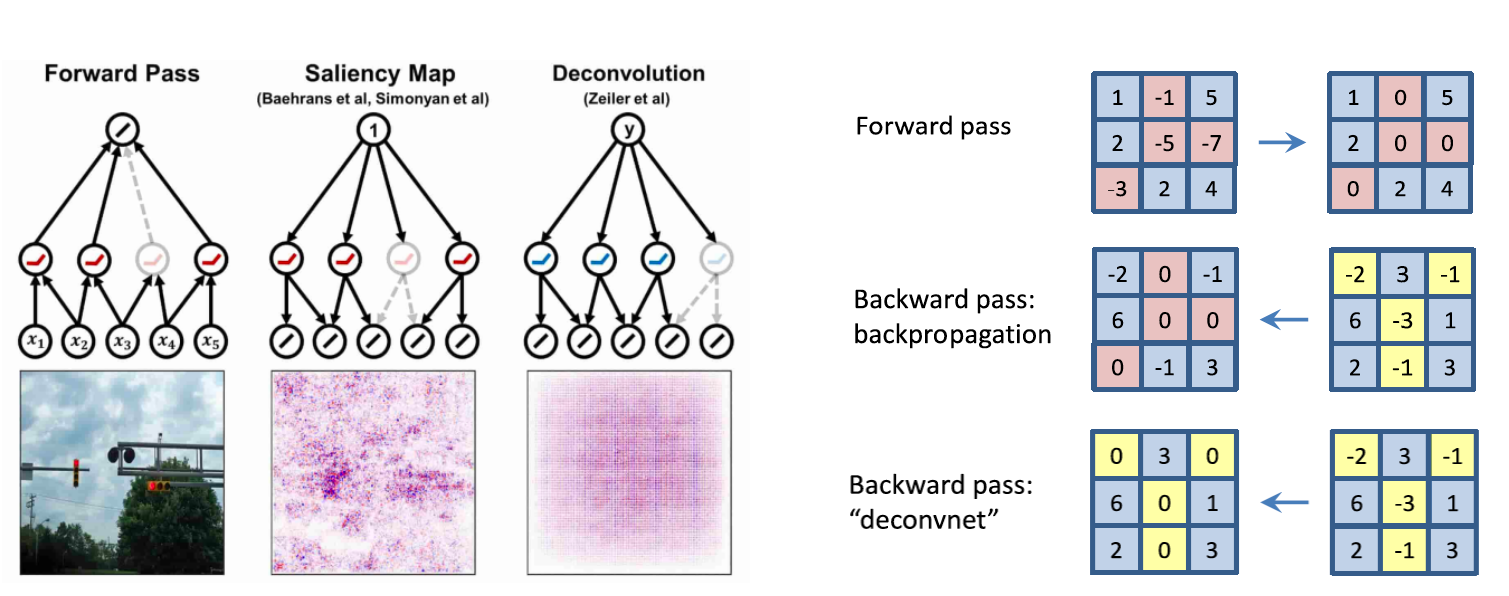
Backpropagate features
- backpropagation
forward할시에 음수였던(비활성화되었던) 부분을 0으로 - deconvolution
backward할시에 음수였던(비활성화되었던) 부분을 0으로 - guided backprop
위의 두방법을 혼합. forward시, backward시 비활성화 부분 모두 0으로
질문
근데 위 방법으로 어떻게 이미지를 그릴 수 있는거지?

Class activation mapping
CAM
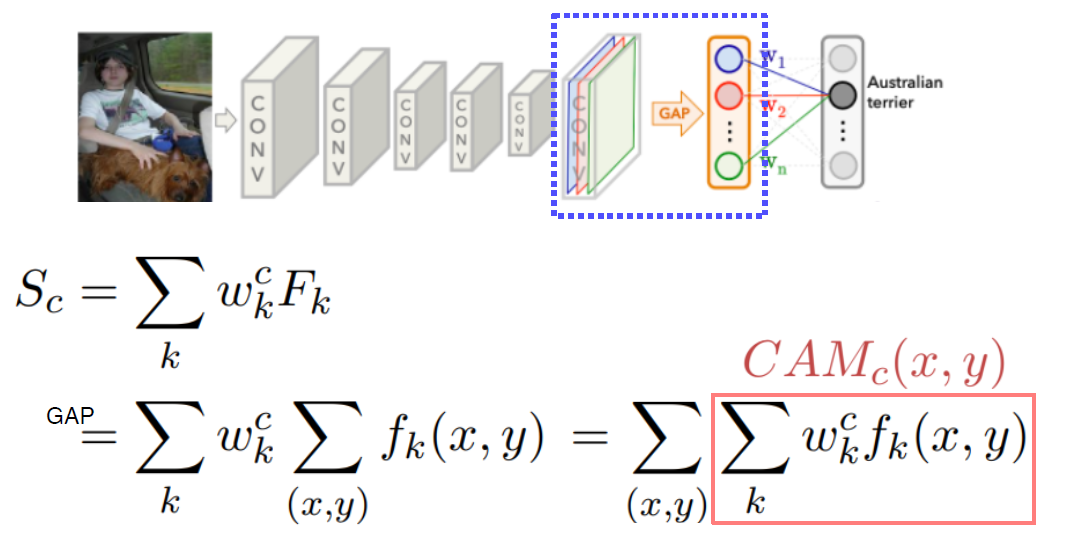
채널별 GAP -> classification layer 구조를 통해 채널별 weight를 구할 수 있음

시각화할때는 gap하기전의 피쳐맵에 대응되는 weight를 곱한다음 합해서 시각화
googlenet은 이미 gap -> fc-layer 구조를 가지고 있어 적용하기 쉽다.
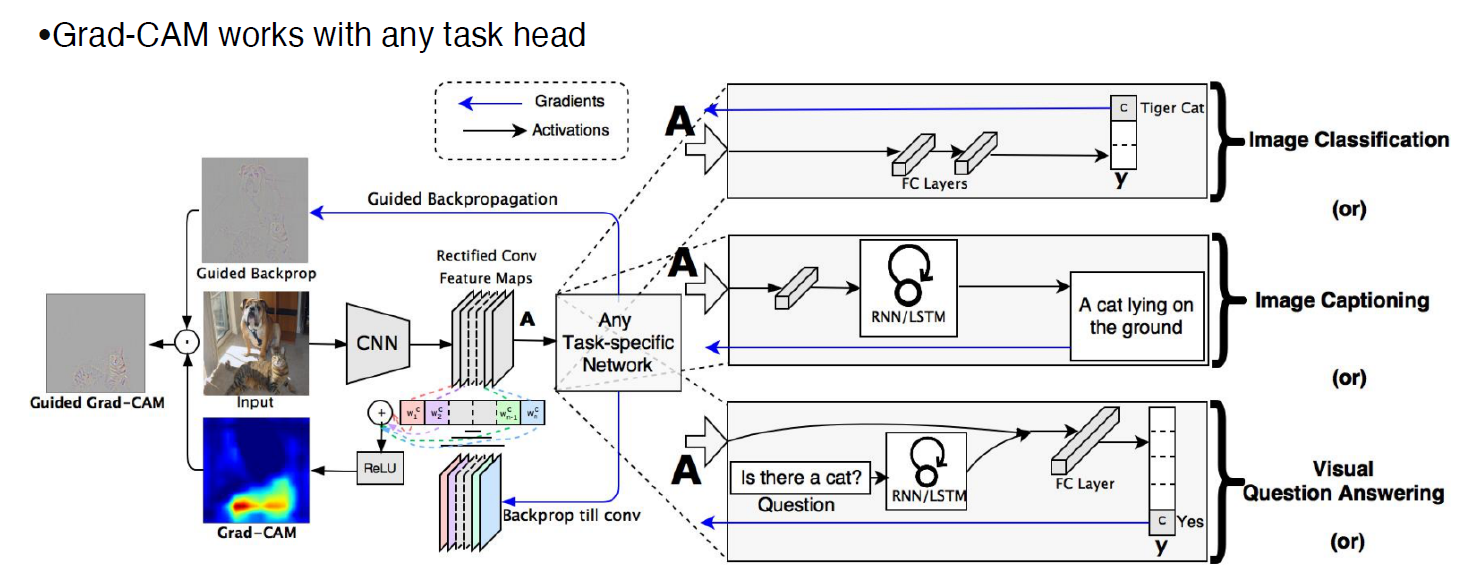
Grad-CAM
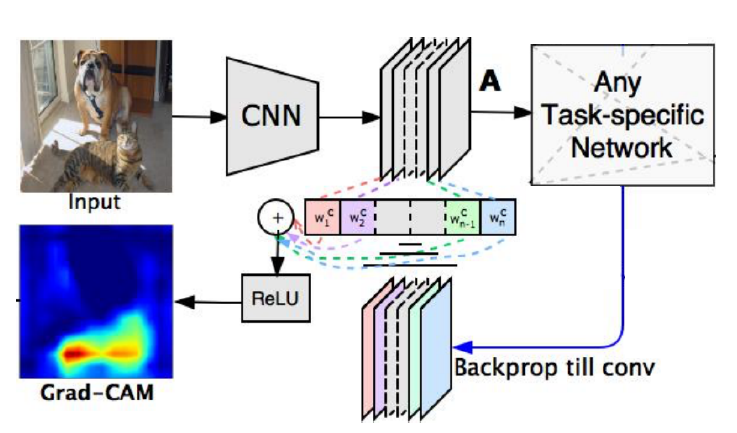
-
gap -> fc-layer 구조를 가지지 않아도 된다.
-
집중하려는 activation layer를 정하고
-
해당 layer의 채널별 gradient를 구해서
-
이를 피쳐맵과 곱해서 시각화
-
해당 레이어까지 Backprop만 하면 되므로 뒤의 구조가 어떻든 상관이 없다.