Self attention
각 단어를 query, key, value로 만든다. 이는 각각 행렬을 곱해서 만드는 것.
여기서
query는 지금 주인공인 벡터이다. 다른 단어와의 관계성을 파악하려고하는 벡터이다.
key는 query와 dot product해서 관계성을 파악하려고 하는 대상이 되는 벡터이다.
value는 query와 key의 dot product 결과를 softmax를 통해 score를 만들고 이를 value 벡터와 곱하여 최종 결과물이 완성된다.
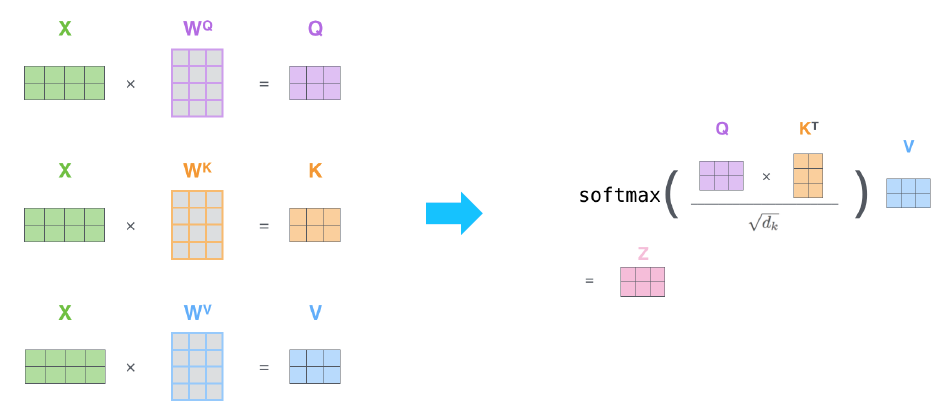
Scaled dot product attention
query와 key의 dot product과정에서 두 벡터의 dimension이 얼마나 큰지에 따라서 softmax 결과가 달라진다.
dimension이 클수록 softmax 결과가 한쪽으로 치우치게 되기에 dimension의 크기로 나눠주는 scaling 작업을 하게된다.
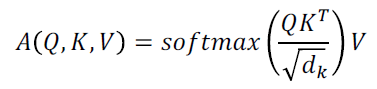
self attention의 복잡도
attention연산은 rnn에 비해 메모리는 많이 들지만 시간은 단축된다.
또한 한 단어와 모든 단어의 관계를 한꺼번에 행렬연산을 통해 계산하기에
rnn에서 단어와 단어간의 거리가 멀어지는 경우를 피할 수 있다.(연관성있는 단어간의 거리가 먼 경우)

Multi-head attention
Multi-head attention은 self attention을 여러 버전으로 진행하는 것이다.
각각 다른 버전의 Q, K, V 행렬을 만들어 각 버전의 scaled dot product attention을 수행하여 인코딩 결과를 만든다.
그리고 이를 concat하여 최종 결과물을 만든다.
concat한 결과물은 head개수만큼 차원이 늘어났기에 이후 다른데에서 쓰이기 위해 선형변환을 통해 차원을 변형한다.
Residual connection
Multi-head attention의 결과물과 인풋 벡터를 더해서 다음 레이어에 넣는 것이다.
Layer normalization
- 각 단어벡터 내의 평균과 분산으로 벡터 내 값을 정규화
- 각 차원의 값을 affine trasformation한다.

Positional encoding
attention 과정은 모든 단어간의 dot product를 하는 과정이기에 단어의 순서성을 고려하지 못한다.
I am a student 와 am I a student문장에서 각 단어의 인코딩 결과가 같다.
그렇기에 순서성을 고려하기 위해 Positional encoding을 입력에 더해준다.
Positional encoding은 아래 그림처럼 몇번째 단어의 각 차원에 해당하는 값을 여러 sin cos함수를 이용하여 정해놓고 이를 더해주는 것이다.
그림에서 x축이 몇번째 단어인지를 뜻하고 각 그래프는 각 차원에 매칭된다.

Warm-up learning rate scaduler
학습의 양상에 따라 learning rate를 조절하는 것이다.
optimal point에 가까워졌을때 lr이 너무 클 경우 계속 수렴하지 못할 수 있기에 이때는 lr을 작게 줄이는 식이다.
Decoder의 전체적인 구조
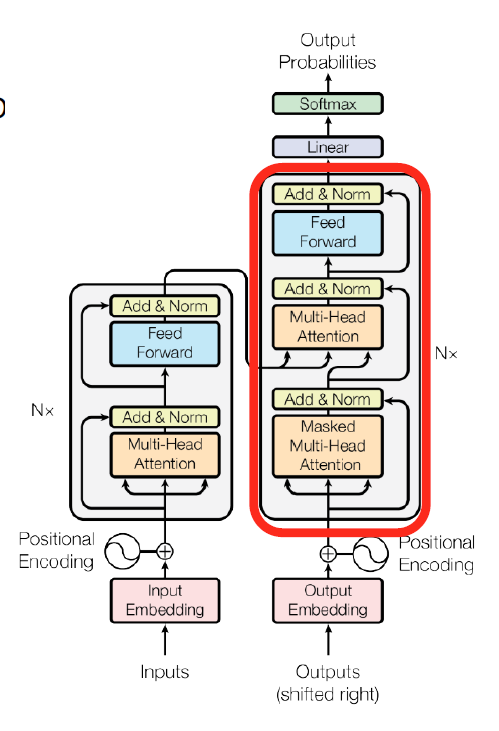
오른쪽으로 shift된 입력을 넣고 이를 masked multi-head attention해서 결과물을 query로 하고 인코더 결과물을 key, value로 해서 multi-head attention을 진행한다.
이후엔 fead forward, linear, softmax를 통해 최종 단어를 예측한다.
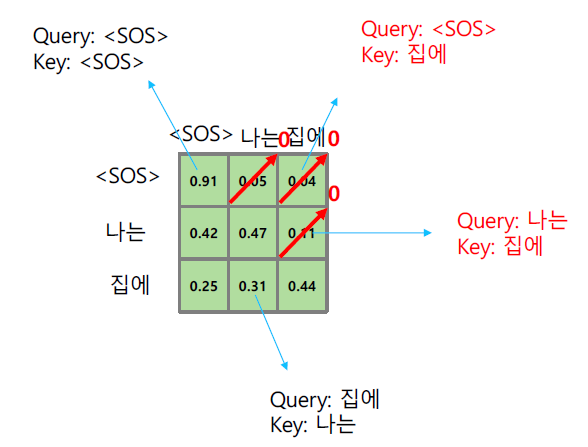
Masked multi head attention
Masked multi head attention은 디코더에서 미래에 등장할 단어와의 연관성을 보는 것을 막기위해 해당 시퀀스에서 뒤의 단어와의 dot product 값은 삭제하고, 삭제하고 남은 값을 합이 1이 되도록 다시 조정하여 이를 softmax하는 것이다.
해야할것
- 전체구조도에서 모든 과정에서의 차원 계산하기
자료출처 : 네이버 부스트캠프 학습자료
