해시테이블
key, value 구조로 해시함수를 이용하여 데아터를 저장하는 삽입 삭제 탐색 모두 O(1) 시간복잡도를 갖는 자료구조
파이썬에서 딕셔너리가 해시 테이블이다.
- 해시함수로 키값을 인덱스로 매핑하는데에 충돌을 막기위해 큰 공간 복잡도 소요
- 충돌이 발생한 경우 최악엔 O(N) 시간 복잡도
해시테이블을 구성하는 건 해시 함수와 배열이다.
해시함수는 key를 받아 실제 어디에 저장할 지 배열의 인덱스 값을 반환한다.
배열은 실제로 데이터가 저장되는 곳이다. 이를 버킷(bucket)이라고 한다.
왜 해시함수가 필요할까?
key에 해당하는 value를 특정 크기의 배열에 집어넣어야 하기 때문이다.
아래처럼 키,밸류 값을 버킷 안에 마음대로 섞어버려서 넣어버리게 도와주는 것이다.
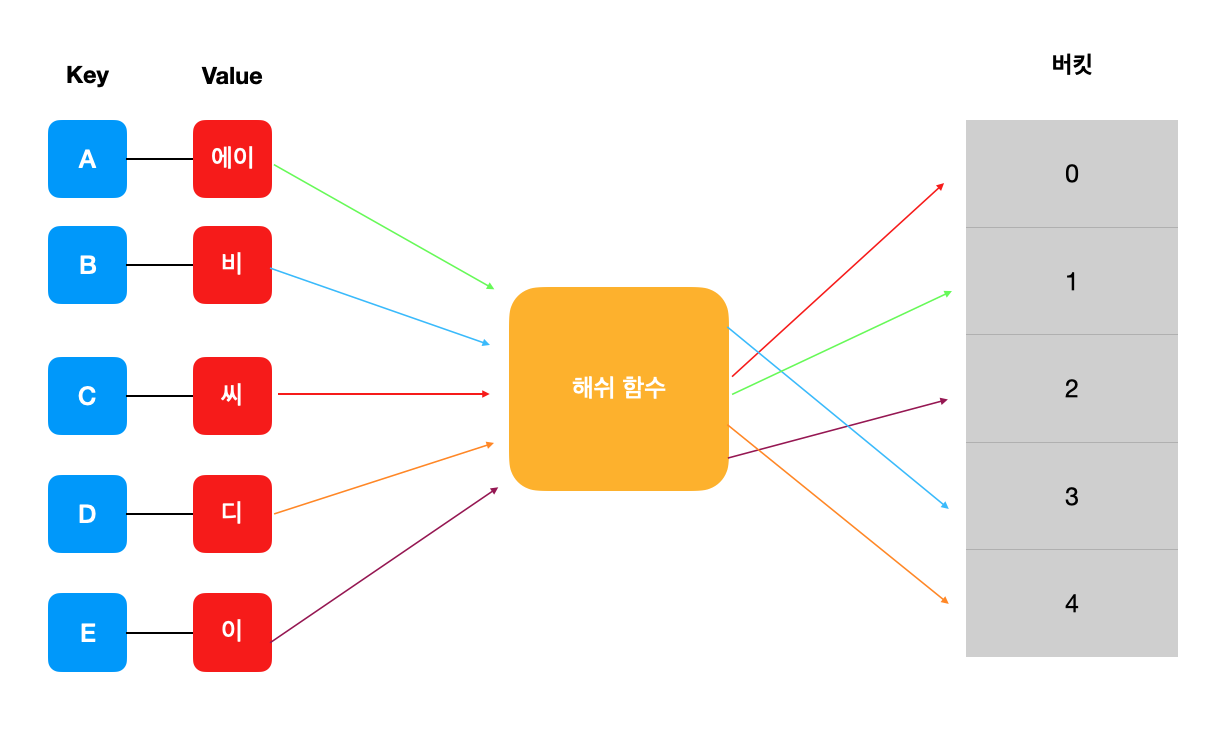
그런데 왜 마음대로 섞을까?
그냥 입력 순서대로 저장하면 되는 것 아닌가? -> 그러면 배열 자료구조와 같아지는 것이다. 입력 순서대로 배열에 저장하게되면 다 저장한 후, 특정 key의 값을 찾아야하는 상황에서 key에 대응되는 value가 어떤 인덱스에 위치하는지 해시 함수 없이 어떻게 찾을 것인가?
즉 해시함수는 특정 계산식으로 인덱스를 알려주기에 직접 배열을 탐색할 필요 없이 자료의 위치를 알 수 있다.
공간으로 시간을 사는 방법
해시 함수
그렇다면 해시 함수를 어떻게 만들어야할까?
우선 해시함수는
- key를 배열크기 안의 인덱스로 매핑
- 지정해주는 인덱스가 중복되지 않게 해야한다.
Division method
버킷사이즈 - (key값%버킷사이즈) 로 계산한다.
이 때 버킷의 사이즈는 소수로 정하고, 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 한다.
Digit Folding
key값이 문자열일 때의 방법.
각 문자의 ASCII 코드값의 합을 인덱스로 사용한다.
만약 이 값이 버킷사이즈를 초과하면 division method로 나눠서 사용한다고 한다.
만약 FOMA라면 F:70, O:79, M:77,A:65 = 291이 인덱스로 되는 것
Multiplicaiton method
k : 숫자로 된 key값
A : 0~1 사이의 실수
m : 2의 제곱수
floor(kA % 1) m 의 결과값을 사용한다.
k가 100 , A가 0.12345 , m이 2³ 이라면
1000.12345%1 8 = 2.76 이므로 인덱스는 2가 됩니다.
Universal hashing
여러 종류의 해시함수의 집합 중 무작위로 선택해서 인덱스를 만들어 사용
해시 충돌
해시함수를 최대한 잘 마련해도 다른 key값이 같은 해시값을 가지는 상황이 발생할 수 있다.
예를 들어 Key 값을 13 으로 나눈 나머지를 Index 로 사용하는 해시 테이블이 있다고 가정해보자. 또한 이 해시 테이블에는 현재 Key 가 5인 값이 들어가 있는 상황이다.
이 해시 테이블에 Key 가 18 인 데이터를 저장하려 해보자. 하지만, 18 의 해시 값도 5, 즉 Index 가 중복되기 때문에 충돌 (Collision) 이 발생한다.
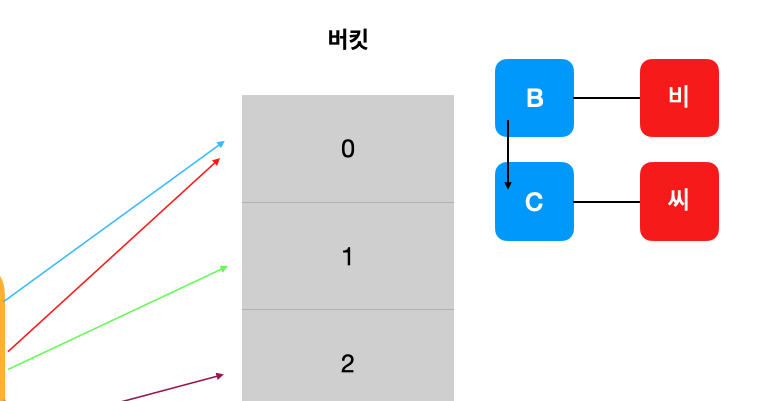
Chaining
연결리스트를 이용해 충돌이 발생한 값을 같이 저장하는 방법
각 버킷에 대응하는 링크드 리스트를 생성하고, 버킷이 링크드 리스트의 가장 앞 노드를 바라보게끔 하여 충돌을 방지하는 방법이다. 해시 충돌이 발생했을 때 그저 같은 버킷 링크드 리스트의 마지막 노드로 해당 값을 추가해주기만 하면 된다.
Open Addressing
빈 버켓을 찾아서 충돌 발생한 값을 저장하는 방법
Chaining 방법과 다르게 한 버킷에는 하나의 Value 만 저장하며, 해시 충돌 시 Key 를 재해싱(rehasing) 하여 빈 버킷에 데이터를 저장하는 방법이다.
빈 버켓을 찾는 방법에 따라서 아래와 같이 나뉜다.
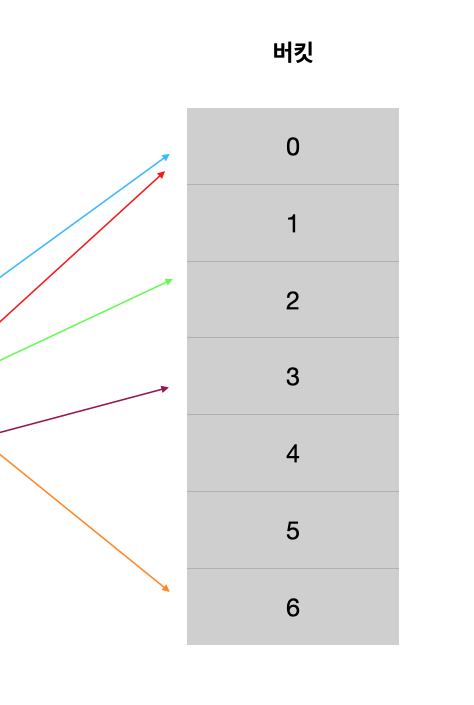
Linear Probing
중복이 발생한 버킷에서 가장 가까운 버킷 찾아서 넣어주는 방법
Quadratic Probing
빈 버킷을 찾을 때까지 현재 인덱스의 제곱 뒤의 인덱스의 버킷을 확인하는 방법

Double Hasing Probing
비어있는 버킷 찾을 때까지 다른 해시함수 시도하는 방법
h1(k)→ 충돌 → h1(k)+1h2(k)→충돌→ h1(k)+2h2(k)→충돌→h1(k)+3*h2(k)→... 로 진행합니다.
예를 들면 h1(k) = key % 7 , h2(k) = 5 - (key%5) 설정하였다면 아래와 같이 비어있는 인덱스를 탐색하게 됩니다.

정리
- 해시테이블은 해시함수로 key, value 구조를 지원해 빠른 삭입 삭제 탐색이 가능하게 한다.
- 해시함수를 만드는 방법은 나머지를 이용하는 방법, 아스키코드의 값의 합을 이용하는 방법등이 있다
- 해시충돌이 발생할 때는 liked list를 이용하는 방법과 다른 빈 버킷을 찾는 방법이 있다.
출처
