배경
쿼리의 성능 개선 작업을 진행하기 전
성능 측정용으로 대규모 데이터가 들어있는 테스트 데이터베이스를 만들기로 했습니다.
데이터는 아래와 같은 시나리오로 생성합니다 :
- 각 유저는 강아지를 세마리 등록한다.
- 각 유저는 30일간의 산책 기록을 갖고 있고 매일 한번씩 산책한다.
- 각 산책에 강아지 세마리를 모두 데려간다.
- 각 강아지가 한번씩 배변한다. (대변/소변은 랜덤)
- 각 산책당 사진을 한 장씩 저장한다.
유저가 100명이라고 가정했을 때,
다대다 관계로 인해 특정 테이블은 최대 9000 개의 row를 갖게 됩니다.
10만 유저를 가정하고, 최대 9백만개의 row를 생성하는 것을 목표로 하려고 합니다.
대규모 데이터 생성하기
대규모 데이터의 생성에는 여러가지 방법이 있습니다.
툴을 사용하기도 하는데, 많은 데이터를 생성하려면 유료인 경우가 대부분이고
팀원간 공유하기도 불편할 것 같아
되도록이면 툴을 사용하지 않는 방향으로 찾아보았습니다.
-
엑셀로 만들기
찾아보니 대규모 데이터를 엑셀로 생성한 뒤 csv 형식으로 저장해서 insert 하는 방법도 있었지만
테이블의 추가나, 컬럼 수정과 같은 변경이 있을 때를 고려하면 유지/관리에 어려움이 있을 것 같았습니다. -
코드로 만들기
코드로 만들기에는 런타임중에 대규모의 데이터를 생성하는 과정에서 RAM에 부하가 올 것 같았습니다.
데이터를 일정한 청크로 나누어 생성하고 insert 하게 바꾸면 해결될 문제이긴 했지만, 단지 더미 데이터를 만들기 위해 들어가는 작업량이 너무 크다는 생각이 들었습니다. -
쿼리 사용하기
쿼리를 사용하면 데이터베이스 엔진의 최적화 기능의 수혜를 받을 수 있습니다.
여기서도 프로시저와 Recursive CTE로 갈리는데,
재귀 문법을 사용할 수 있어 쿼리 길이가 짧은 CTE를 선택하였습니다.
CTE(Common Table Expression)란
MySQL에서는 모든 쿼리가 임시 결과를 생성합니다. 이 임시 결과에 이름을 붙인 것이 CTE입니다.
이를 통해 명시적인 테이블 없이 행만 생성할 수 있습니다.
CTE는 WITH 구문으로 만들 수 있으며,
WITH RECURSIVE 구문으로 재귀적으로 생성할 수 있습니다.
INSERT INTO test_table (id, duration)
WITH RECURSIVE cte AS (
SELECT
1 AS id
UNION ALL
SELECT
id + 1
FROM cte
WHERE id < 10000
)
SELECT * from cte;WITH RECURSIVE구문으로 CTE를 만듭니다.- 첫번째
SELECT구문은 초기 값이 됩니다. id를 1로 설정합니다. UNION ALL구문으로 이후 실행되는 쿼리의 결과를 이전 값과 결합합니다.UNION ALL아래SELECT구문은 이전 실행의 결과값을 참조해,WHERE id < 10000조건을 충족할 떄까지 실행됩니다. 즉, 10000 개의 행이 생성됩니다.- 이렇게 만들어진 CTE를 테이블에
INSERT합니다.
데이터 생성시 고려할 점
- 랜덤 데이터
실제와 비슷한 환경을 만들기 위해SELECT,WHERE의 인자가 되는 등 SQL에 직접적으로 쓰이는 컬럼의 경우 랜덤한 데이터를 생성하도록 작성했습니다.
INSERT INTO today_walk_time (id, duration)
WITH RECURSIVE cte AS (
SELECT
1 AS id,
-- 1 ~ 10800 사이의 랜덤한 정수 생성
floor(rand() * 10800) AS duration
UNION ALL
SELECT
id + 1,
floor(rand() * 10800)
FROM cte
WHERE id < 10000
)
SELECT * from cte;enum 또는 boolean의 경우,SELECT CASE문을 사용했습니다.
INSERT INTO dogs (id, name, ... ,gender, ..., is_walking)
WITH RECURSIVE cte AS (
SELECT
1 AS id,
...
'FEMALE' AS gender,
...
false AS is_walking
UNION ALL
SELECT
id + 1,
...
-- 'MALE'과 'FEMALE'중 랜덤으로 생성
CASE
WHEN RAND() < 0.5 THEN 'MALE'
ELSE 'FEMALE'
END,
...
-- true와 false 중 랜덤으로 생성
CASE
WHEN RAND() < 0.5 THEN true
ELSE false
END
FROM cte WHERE id < 10000
)
SELECT * from cte;- 중복을 허용하지 않는 데이터
중복을 허용하지 않아 모든 레코드가 다른 값을 가져야 하는 경우도 있었습니다.
예를 들어 유저 닉네임이 그런 경우였습니다.
아래처럼 고정된 str + id값을 주어 매 행이 다른 값을 가질 수 있도록 했습니다.
INSERT INTO users (id, nickname, ...)
WITH RECURSIVE cte AS (
SELECT
1 AS id,
-- 열 크기 할당
cast('nickname0' AS char(20)) AS nickname,
...
UNION ALL
SELECT
id + 1,
-- 'nickname' + id로 된 데이터 생성
concat('nickname', id),
...
FROM cte
WHERE id < 10000
)- 전체 열의 크기가 첫
SELECT문의 열 크기로 결정되기 때문에,CAST구문으로 충분한 크기를 할당하였습니다.
- 관계형 테이블
다대다 관계를 나타내기 위한 관계형 테이블의 경우, 한 컬럼은 고정되고 다른 컬럼만 증가하는 로직이 필요했습니다. 아래와 같이 구현하였습니다.
INSERT INTO users_dogs (dog_id, user_id)
WITH RECURSIVE cte AS (
SELECT
1 AS dog_id,
1 AS user_id
UNION ALL
SELECT
dog_id + 1,
-- dog_id를 @dog_per_user로 나눈 나머지가 3일 경우에만 user_id를 증가시킨다
CASE WHEN (dog_id + 1) % @dog_per_user = 1 THEN user_id + 1 ELSE user_id END
FROM cte
WHERE user_id < @user_num
)
SELECT * from cte;
SET FOREIGN_KEY_CHECKS = 0;
truncate journals;- users_dogs 테이블은 산책일지와 강아지 간 다대다 관계를 나타내는 테이블입니다.
- dog_per_user 변수는 각 user 당 할당할 강아지의 마리수입니다. 예를 들어 3이라고 하면, 현재 dog_id를 3으로 나눈 나머지가 1일 때만 user_id를 증가시키도록
CASE문을 작성했습니다.
- 다양한 시나리오 반영
어떤 테이블에 어느 정도의 데이터가 있는지에 따라 쿼리 성능이 달라지기 때문에, 여러 시나리오를 반영하고자 변수로 이를 쉽게 조절할 수 있게 했습니다.
-- 테스트 시나리오에 맞춰 변수 지정
SET @user_num = 100;
SET @dog_per_user = 3;
SET @journal_per_user = 1000;
SET @journal_per_day = 3;
SET @journal_dog_row_num_per_user = @journal_per_user * @dog_per_user;
SET @excrements_row_num_per_user = @journal_per_user * @dog_per_user;
더미 데이터 생성 & 삽입
본격적으로 더미 데이터를 생성하고, 삽입해보겠습니다.
1. 데이터베이스 생성하기
더미 데이터를 삽입할 데이터베이스를 생성합니다.
성능 측정 용도로 사용할 것이기에 이름을 performance로 지었습니다.
CREATE DATABASE performance;2. 테이블 생성하기
새로 생성한 데이터베이스에 기존과 같은 구조의 테이블을 만듭니다.
저의 경우 쿼리가 아닌 typeorm으로 테이블을 생성해왔기에 따로 관리하는 DDL이 없는 상황이었습니다.
테이블 정보를 보고 같은 테이블을 만드는 쿼리를 직접 만들 수도 있겠지만, 시간도 오래 걸리고 휴먼 에러 가능성이 높아 다른 방법을 찾아보았습니다.
기존 테이블에 SHOW CREATE TABLE [테이븖명] 명령어를 사용하면 해당 테이블을 생성하는 DDL을 가져올 수 있습니다.
기존에 사용하던 데이터베이스로 이동합니다.
SHOW CREATE TABLE [테이블명]
ex) SHOW CREATE TABLE journals;
---결과
CREATE TABLE `journals` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`distance` int NOT NULL,
`calories` int NOT NULL,
`started_at` datetime NOT NULL,
`duration` int NOT NULL,
`routes` mediumtext COLLATE utf8mb4_unicode_ci NOT NULL,
`memo` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `FK_dcd8f26897887ea1ca19e9b910a` (`user_id`),
CONSTRAINT `FK_dcd8f26897887ea1ca19e9b910a` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci- typeorm에서 설정한 의존 관계와 CASCADE까지 포함되어 있는 모습을 볼 수 있습니다.
주의할 점은, 기존 테이블의 상태까지 가져오기 때문에
FK 등 key 값의 변수명을 동일하게 설정합니다. 또 PK의 시작 값이 기존 DB PK의 다음 값으로 설정됩니다.
예를 들어 위의 경우 AUTO_INCREMENT=11이 포함되어 있는데,
기존 테이블의 journals 테이블에 레코드가 10개 들어있었기 때문에 그 다음 값인 11을 초기값으로 할당하는 것입니다.
변수명은 이전 DB와 동일해도 괜찮지만, AUTO_INCREMENT의 값은 1부터 시작해야 하기 때문에 구문을 지워줍니다.
CREATE TABLE `journals` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`distance` int NOT NULL,
`calories` int NOT NULL,
`started_at` datetime NOT NULL,
`duration` int NOT NULL,
`routes` mediumtext COLLATE utf8mb4_unicode_ci NOT NULL,
`memo` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `FK_dcd8f26897887ea1ca19e9b910a` (`user_id`),
CONSTRAINT `FK_dcd8f26897887ea1ca19e9b910a` FOREIGN KEY (`user_id`) REFERENCES `users` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci이 상태로 DDL을 실행하면 기존과 같은 구조로 테이블이 생성되는 것을 확인할 수 있습니다.
3. cte_max_recursion_depth 설정
실행 전, 최대 재귀 횟수를 지정하는 cte_max_recursion_depth 변수의 값을 생성하고자 하는 행의 갯수만큼 설정해줘야 합니다.
유저 10만, 관계형 테이블을 고려하면 최대 9백만개의 행을 만들 예정이기 때문에 넉넉히 천만으로 설정해줍니다.
SET SESSION cte_max_recursion_depth = 10000000;4. 더미 데이터 삽입 쿼리 실행
Recursive CTE로 데이터 생성 /삽입하는 쿼리를 실행합니다.
결과
용량
데이터 삽입 전
| Database | used_MB |
|---|---|
| performance | 0.3 |
데이터 삽입 후
| Database | used_MB |
|---|---|
| performance | 1943.8 |
0.3->1943.8로1.9408GB증가되었습니다.
소요 시간
약 4분 30초가 소요되었습니다.
성능
데이터를 삽입하는 동안 mysql 도커에 docker stats 명령어를 1초에 한번씩 실행해 소모되는 리소스의 양을 기록해보았습니다.
데이터 삽입 전
| TIMESTAMP | NAME | CPU % | MEM USAGE / LIMIT | MEM % | NET I/O | BLOCK I/O |
|---|---|---|---|---|---|---|
| 2024-06-29 15:03:21 | local-mysql | 0.91% | 516.8MiB / 3.835GiB | 13.16% | 37.5kB / 13.9kB | 78.4MB / 303MB |
| 2024-06-29 15:03:24 | local-mysql | 2.37% | 518.3MiB / 3.835GiB | 13.20% | 37.5kB / 13.9kB | 78.4MB / 303MB |
| 2024-06-29 15:03:26 | local-mysql | 1.64% | 518.3MiB / 3.835GiB | 13.20% | 37.5kB / 13.9kB | 78.4MB / 303MB |
데이터 삽입 중
| TIMESTAMP | NAME | CPU % | MEM USAGE / LIMIT | MEM % | NET I/O | BLCOK I/O |
|---|---|---|---|---|---|---|
| 2024-06-29 15:05:13 | local-mysql | 108.26% | 659.1MiB / 3.835GiB | 16.79% | 37.5kB / 13.9kB | 650MB / 4.83GB |
| 2024-06-29 15:05:15 | local-mysql | 105.47% | 659.2MiB / 3.835GiB | 16.79% | 37.5kB / 13.9kB | 651MB / 4.98GB |
| 2024-06-29 15:05:18 | local-mysql | 114.83% | 660.7MiB / 3.835GiB | 16.83% | 37.5kB / 13.9kB | 673MB / 5.23GB |
| 2024-06-29 15:05:20 | local-mysql | 113.94% | 661.7MiB / 3.835GiB | 16.85% | 37.5kB / 13.9kB | 707MB / 5.44GB |
각각 평균적인 세 번의 기록만 가져왔습니다.
CPU와 메모리의 사용량을 그래프로 나타내면 다음과 같습니다.
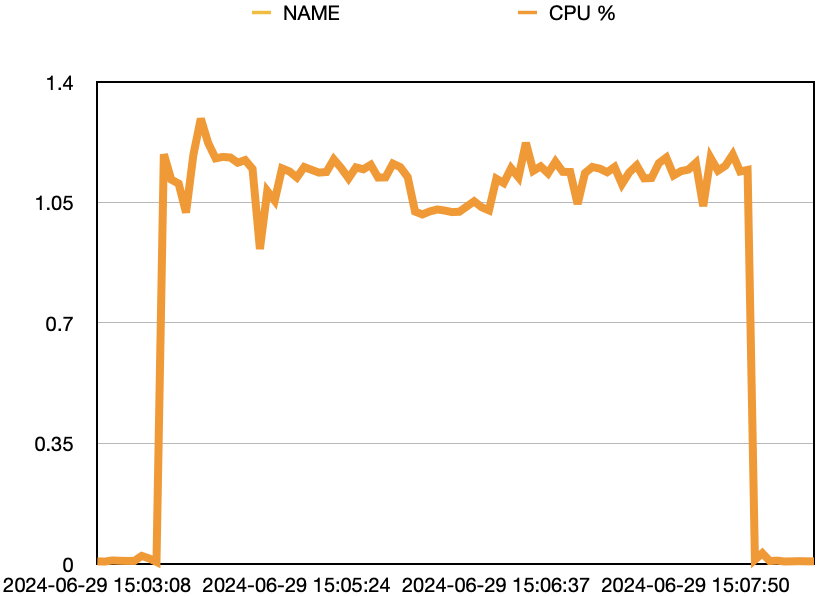
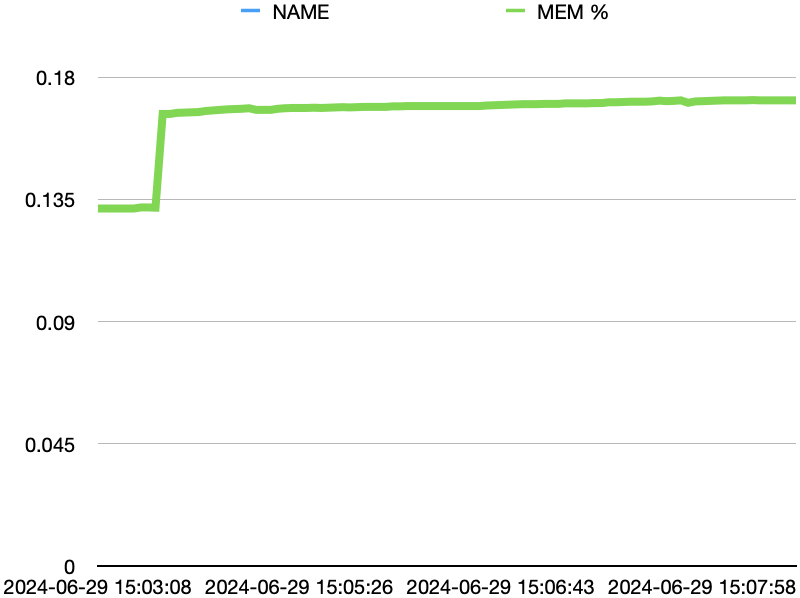
- CPU의 사용량이 급격히 늘었습니다.
- 메모리 사용량은 약 500 M -> 약 650 M로 150M 정도, 퍼센트로는 3% 정도밖에 증가하지 않았습니다.
- BLOCK I/O는 읽기/쓰기 양을 나타내는데, 1초에 간격으로 조금씩 늘어나는 걸로 보아 대규모의 row 생성시 메모리 부하를 막기 위해 내부적으로 데이터를 일정한 단위로 쪼개어 저장하도록 최적화가 되어 있는 것으로 보입니다.
CPU 사용량이 크게 늘어 CPU가 빵빵하지 않은 환경에서는 사용에 주의가 필요해 보입니다.
메모리는 거의 소모되지 않았습니다. 데이터를 쪼개어 작업하도록 최적화가 되어 있는 것을 알 수 있습니다.
Reference
MySQL table로부터 DDL 추출하기
https://developer-joe.tistory.com/113
MYSQL 더미 데이터 넣기
https://velog.io/@sileeee/MYSQL-%EB%8D%94%EB%AF%B8-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%84%A3%EA%B8%B0
MySQL 공식문서 - CTE
https://dev.mysql.com/doc/refman/8.4/en/with.html
MySQL | Recursive CTE (Common Table Expressions)
https://www.geeksforgeeks.org/mysql-recursive-cte-common-table-expressions/
Fill Tables With Large Amounts Of Test Data
https://sqlfordevs.com/fill-table-test-data
