자료구조 & 알고리즘이란
자료구조 & 알고리즘이라는 수업은, CS 전공자라면 누구든 들어볼 법한 강의다. 직관적으로, 이 수업을 수강하면 주어진 데이터를 활용하여 원하는 결과값을 얻기까지의 과정, 절차를 어떻게하면 효율적으로 기획할 수 있을 것인가에 대한 고민을 할 수 있을 것 같다. 다양한 문제 상황에서 어떠한 알고리즘, 자료구조가 적합한지는 상황에 따라 상이하다. 따라서, 여러가지 자료구조와 알고리즘을 학습하여 주어진 상황에 맞는 것을 선별하는 능력을 길러야한다. 어떻게? 수업 때 배운 내용을 적용하면서 !
자료구조 : 정보를 저장하는 방법 _ 데이터의 구성과 조작
알고리즘 : 문제를 해결하는 절차, 방법
-> 알고리즘이 자료구조를 이용하여 문제 해결 !
ex) 정렬 알고리즘을 구현하기 위해, 배열과 연결리스트와 같은 자료구조가 사용된다.
자료구조와 알고리즘을 공부해야하는 이유? (참고사항)
- 높은 활용성과 파급력
- 유구한 역사를 가졌으나 여전히 많은 기회의 영역
- 좋은 알고리즘 이외에 풀 수 없는 문제들이 존재
- 지적 욕구를 충족하기 위해
- 전문적인 프로그래머가 되기 위해
- 21세기 과학의 핵심
- 취업 시장에서 수요가 높고 급여가 높음
기회의 영역이다!
이전에 정리해둔 알고리즘 수업자료)
기초 알고리즘 정리
CS50 정리
효율족인 알고리즘 설계 과정
- 문제 모델링
- 알고리즘 설계
- 정확성, 효율성(연산 속도 / 메모리 사용량 등) 분석
- 문제 발생 시 이유 분석
- 알고리즘 개선
- 만족할 때까지 위 과정 반복
UNION_FIND
>> 자료구조와 알고리즘의 조합
: 그래프 알고리즘 (원소들간의 연결 重)
: Disjoint-Set를 표현하는 자료구조
-> 공통의 원소 無 "상호 배타"적인 부분집합으로 이루어진 데이터
문제 상황 : Dynamic connectivity
: 그래프의 연결상태가 동적으로 변하는 상황에서,
두 노드가 현재 연결되어 있는가?
명령어
1. union : 두 객체 연결해라
-> 두 객체가 포함된 연결 요소의 합집합으로 기존 연결 요소를 대체
-> 연결요소의 갯수가 줄어든다!
2. connected(find) : 두 객체가 연결되었는지 여부 파악해라
->True, False
- 객체 : 0 ~ n-1 로 구성
; 배열 인덱스 가능하도록!
; symbol table, search 알고리즘과 연결 가능 - connected는 다음과 동치관계이다.
- Reflexive: p is connected to p (자기자신 연결)
- Symmetric: if p is connected to q, then q is connected to p (연결은 쌍방향)
- Transitive: if p is connected to q and q is connected to r, then p is connected to r (3개 연결) - 연결요소_Connected components : 상호연결된 객체의 최대 집합(연결된 것끼리 '덩어리' 구성, 그렇지 않으면 독립된 '덩어리')
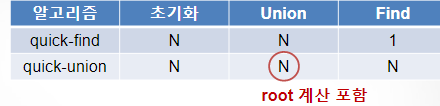
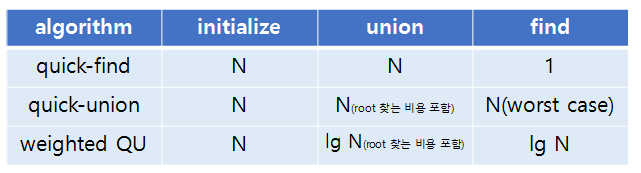
Quick-find
1. 동작 방식 : union(a,b)
- 선으로 2개 연결
- b의 id 값을 따로 적어둠
- a과 연결된 모든 수에 b의 id값 할당
2. 성능분석
- Cost model: 배열 접근 횟수 (FOR 읽고 쓰기)

Quick-find ►► Union이 느림!
: N개의 명령어 to N개의 객체 ►► N**2 번 배열 접근
►► Quadratic (2차)
문제점
- Union 비쌈 (이 연산이 적을 때, 적합한 알고리즘)
- Tree가 flat, BUT 유지보수 hard
- Union 연산이 많아질수록 시간 복잡도가 O(N^2)으로 증가
- 대규모 데이터에서 성능 BAD (소규모 데이터에 용이)
Quick-union
Union연산 많을 때, 대규모 데이터 처리에 용이
Union 연산 효율성 by Tree 구조
1. 동작 방식 : union(a,b)
a와b의 root가 기준이다 !!
id == 부모노드
- a의 root와 b의 root 연결 b의 루트가 위쪽
- a의 id에 부모노드 할당
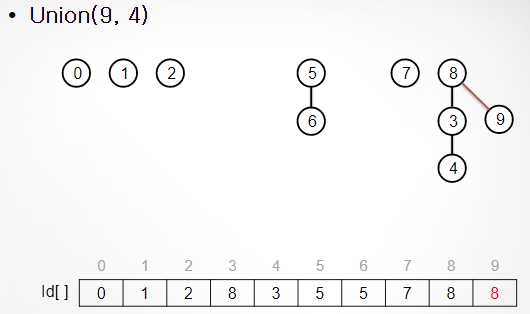
2. 성능분석
문제점
- Find 비쌈
- Tree가 길어짐
- Tree 한 쪽으로 치우치면, 성능 bad
- 루트노드 찾는데 불필요한 탐색 요망됨
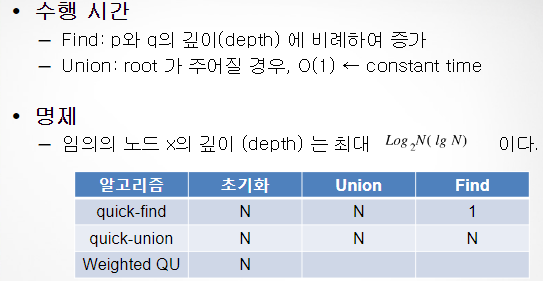
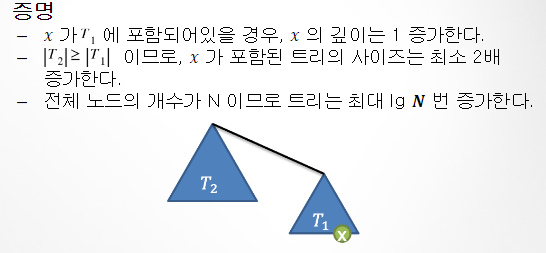
개선1 : Weighted quick-union 알고리즘 성능분석
for 트리 균형 유지
- 각 트리의 사이즈 (객체의 수) 를 유지
- sz[i]: root가 i 인 트리의 객체 수를 저장하는 배열
- a의 root와 b의 root 연결
if (a 트리 크기) == (b 트리 크기)
: 기준 : a
else : 작은 트리를 큰 트리에 연결 >>> 전체 밸런스 유지
- Quick-union은 이와 관계없이,
: b가 기준- 자식노드의 id에 부모노드 할당
분석
- 자료 구조
- Quick-Union 과 동일
- sz[i]: root가 i 인 트리의 객체 수를 저장하는 배열- Find: Quick-Union 과 동일
- Union
- 작은 트리의 root를 큰 트리의 root에 연결
- sz[i] 를 업데이트
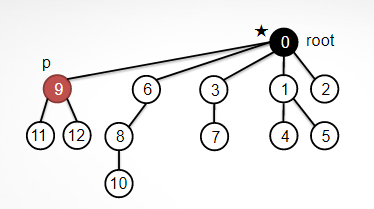
개선2 : Path compression를 이용한 Quick-Union 구현
트리 불균형하면 경로 압축 제대로 X
- P의 root 구하기
- 올라가면서, 모든 노드의 id를 root로 할당
- 기존 id의 값은 부모노드였음 !!
前
後
파이썬 구현
- Two-pass implementation
- 별도의 loop를 만들어서 경로상에 있는 노드들의 id 값 (parent id)을 root로 변경
# -*- coding: utf-8 -*- # UTF-8 encoding when using korean class QuickUnion: def __init__(self, N: int) -> None:\ # initialize union-find data structure with N objects (0~N-1) self.ids = list(0 for i in range(N)) # 리스트의 길이가 N인 배열 for i in range(len(self.ids)): self.ids[i] = i # 각 노드의 id 초기화 self.sizes = [1] * N def _root(self, i: int) -> int: # find root of i # 1. Two-pass implementation while (i != self.ids[i]): i = self.ids[i] # i가 업데이트 ! return i def connected(self, p: int, q: int) -> bool: # are p and q in the same component? return self._root(p) == self._root(q) # p와 q의 root가 같은지 확인 def union(self, p: int, q: int) -> None: # add connection between p and q root_of_p = self._root(p)#노드 p의 root root_of_q = self._root(q)#노드 q의 root # weighted quick union algorithm here if root_of_p == root_of_q: return if self.sizes[root_of_p] < self.sizes[root_of_q]: self.ids[root_of_p] = root_of_q self.sizes[root_of_q] += self.sizes[root_of_p] else: self.ids[root_of_q] = root_of_p self.sizes[root_of_p] += self.sizes[root_of_q]
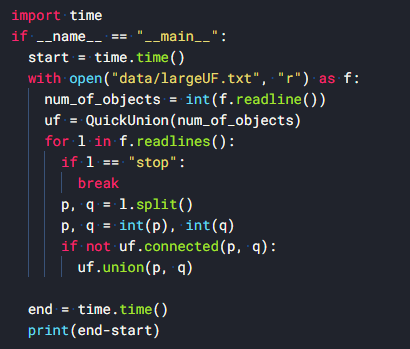
- Simpler one-pass variant (시간 더 빠름! )
- 경로상에 있는 노드들의 id 값을 grand parent 값으로 변경 (즉, id[id[i]]
- 노드를 하나 건너 하나 탐색 → 총 경로가 절반으로 압축
def _root(self, i: int) -> int: # root의 id는 root이다 ! while (i != self.ids[i]): # 루프!!! self.ids[i] = self.ids[self.ids[i]] # 한줄 추가 i = self.ids[i] # i가 업데이트 ! return i
Wost Case
- WQUPC : 비선형 (실제론 선형에 가까움. 실험적.)
Union-find 알고리즘 응용
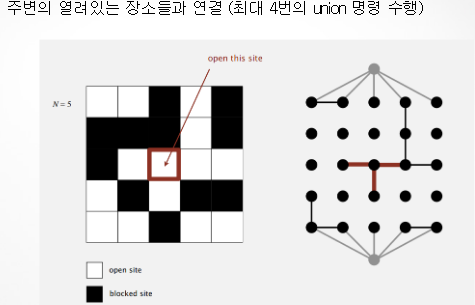
Percolation (투과)
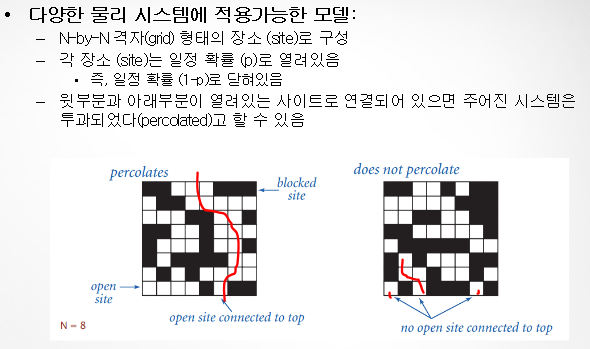
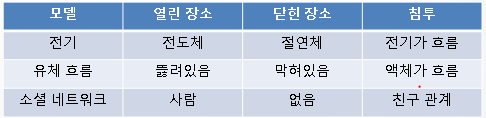
Dynamic connectivity 방법을 이용하여 투과 역치값을 추정
- 투과 역치값 p*
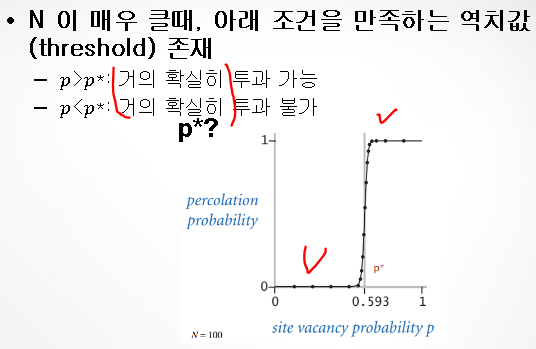
이는 오직 오직 시뮬레이션을 통해서 알려진 숫자
몬테 카를로 (Monte Carlo) 시뮬레이션
투과 가능한지 확인하는 방법 (find)
1. 스마트폰 패턴 그리기
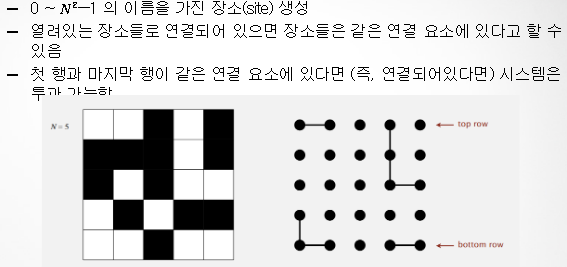
2. 최상, 최하단에 가상의 장소 추가 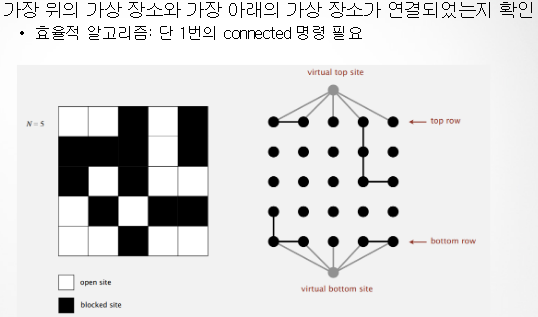
새로운 장소 열기 (union)