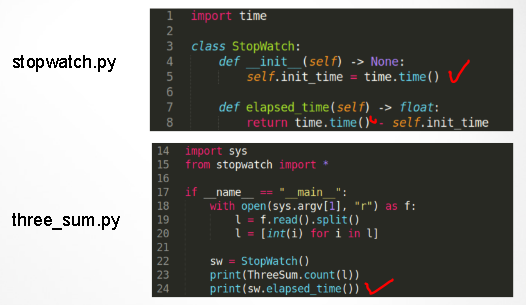
0. 시간측정 코드구현
1. 과학적 방법 (scientific method)
수학적 분석기법은 특정 시스템에 의존적이지 않음
실제 시스템이 수학적 분석과 유사하게 동작하는지 확인하기 위해
실험적 분석 기법은 반드시 필요
- 알고리즘의 성능을 예측하고 비교하는 체계
- 과학적 기법의 순서
- 자연계의 어떤 현상을 관찰 (observe)
지속적 관찰을 통해 일관성있는 모델을 가정 (hypothesize)
가정을 통해 특정 이벤트를 예측 (predict)
실험을 통해 가정이 맞는지를 검증 (verify)
반복적인 실험을 통해 가정이 우연이 아님을 입증 (validate)- 원칙
실험은 재현가능해야 함 (reproducible)
가정은 거짓임이 입증가능해야 함 (falsifiable)- 실험대상
자연계가 아닌 인간이 만든 컴퓨터!
2. 실험적 분석 (empirical analysis) 기법
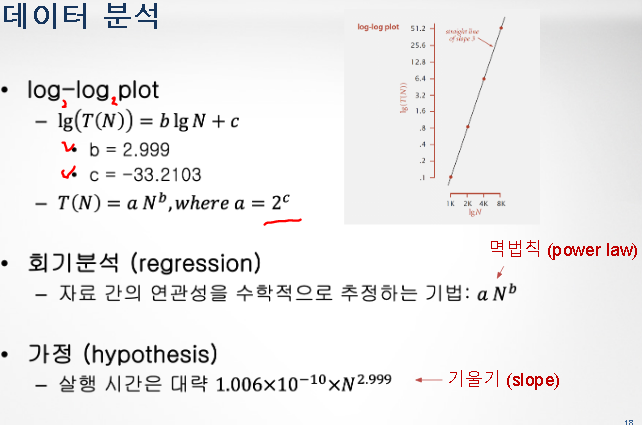
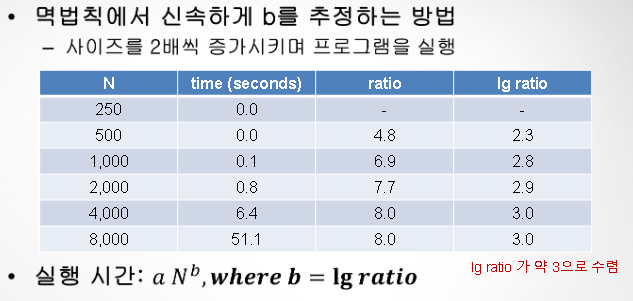
멱법칙을 가정하고 실험을 통해 실행 시간에 따른 가설을 세움
모델링을 통해 입력 데이터 크기에 대한 실행 시간 예측 가능
예시 : 3 sum 문제

- 입력 사이즈에 대한 time 측정 후, 표 및 그래프 정리
- N - T(N)
- log 스케일 변환 후 그래프 표현 => 1차함수 됨!
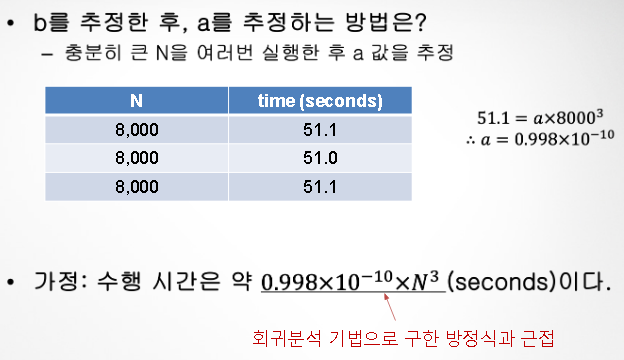
- log 계산 후, log(T(N)) ⇨ T(N) 유도 후 가정 수립
- 예측 케이스 선정 후 예측값(by 수식) 설정
- 실제 시뮬레이션 후, 실제값과 예측값 비교

Doubling Hypothesis (입력사이즈 및 분포 선정)
개선된 3-Sum

3. 수학적 분석 (mathematical analysis) 기법
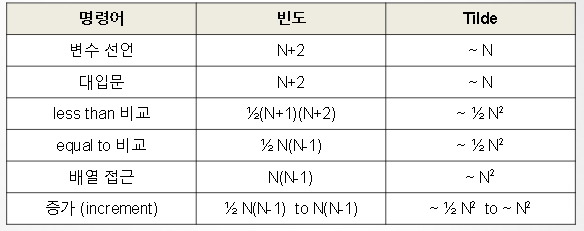
알고리즘에 사용되는 명령어의 종류와 빈도를 분석
Tilde 표기법을 이용하여 분석을 단순화
모델링을 통해 알고리즘의 성능 해석 가능
- 입력의 사이즈가 커질수록, 명령어들의 사용빈도에 대한 계산이 복잡해진다.
- 따라서, 이를 비용모델과 Tilde기호로 단순화하자!

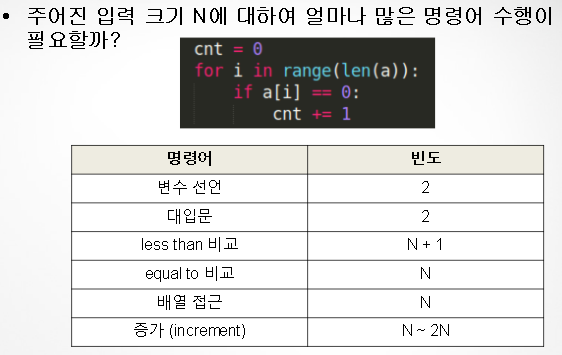
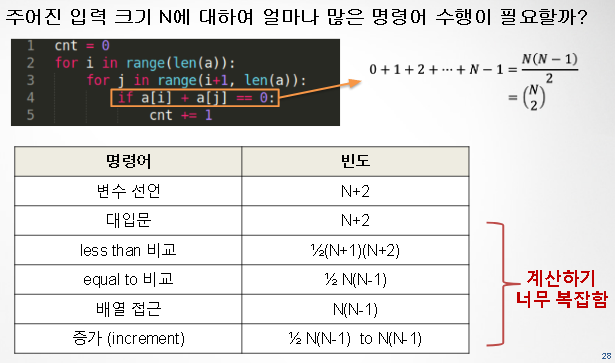
단순화 1. 비용 모델을 정의한다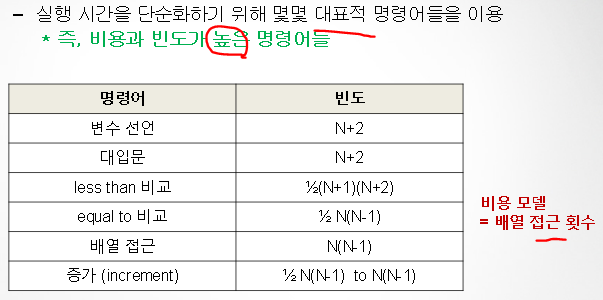
단순화 2: Tilde 기호로 단순화한다.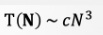
- 입력 사이즈에 대한 실행시간을 추정
- 낮은 순서의 항(내림차순 정리 전제)은 무시
- 크기가 매우 크면, 무시해도 결과에 영향 X
- 크기가 매우 작은 경우, 실행시간 안중요
- Big-O에서 계수정보를 추가한 것!
- 이론적으로 수학적 모델링 가능하나, 매우 복잡하여 전문가만 필요
- 대부분 분야에서는 Tilde 기호 활용, 근사치에 기반한 모델링으로 충분!
참고

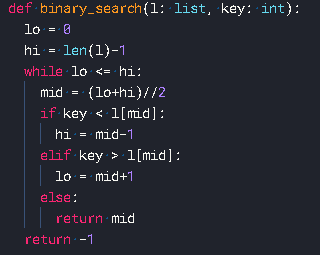
이진 탐색 (binary search) 알고리즘
- 전제 : 정렬됨 / 키는 반드시 배열의 최소값-최대값 사이에 존재
- 목표 : 주어진 키의 인덱스 위치 탐색
- 알고리즘 : 반으로 계속 쪼갠다 ; 배열의 중간값과 키 비교 !!
- 작으면 왼쪽으로
- 크면 오른쪽으로
- 동일하다면 해당값을 리턴
수학적 분석
알고리즘 분석의 다양한 종류
Big Oh, Big Omega, Big Theta 개념 

목표 : 최적의 알고리즘 개발
(특정 성능 보장, 다른 알고리즘보다 최적)
방법 : 상수계수 무시 + 최악 케이스에 집중
예제1

예제2
알고리즘 설계 방법
시작
- lower bound 제공, 동작 가능 알고리즘 개발
Gap
- upper 낮추고, lower 높인다
↳ 새로운 알고리즘 제시 / 이론적 증명 어려움주의사항
- 최악에 지나치게 집중 X (확률 낮음)
- 지나치게 개략적인 성능보다는 정확한 성능예측 요망
주의 : 알고리즘 성능 개력 분석을 위해 Tilde 표기를 사용!

c0d3_wh1t3