INDEX는 말 그대로 책의 맨 처음 또는 마지막에 나오는 색인이라고 할 수 있다.
컬럼의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들어 두는 것.

INDEX 장단점
장점
- 검색 속도가 무척 빨라질 수 있다. (항상 그런것은 아니다.)
- 해당 쿼리의 부하가 줄어들어서, 결국 시스템 전체의 성능이 향상 된다.
웹페이지에 로딩 시간이 3초 이상이 걸리면 대부분의 유저들이 이탈한다고 한다. 그만큼 속도가 중요하다는 것이다. 엄청 많은 데이터가 있을 때 INDEX가 없다면 쿼리 하나에 1~2초씩 걸릴 것이고 그렇게 되면 프론트엔드에 화면을 렌더링 하는데는 3초 이상이 걸리게 될 것이다. INDEX를 만들면 엄청 빠른 시간에 쿼리가 수행 될 수 있으므로 전체 시스템의 성능이 향상된다고 볼 수 있다.
단점
- 인덱스가 데이터베이스 공간을 차지. 대략 10%정도의 추가 공간이 필요.
- 처음 인덱스 생성시 시간이 많이 소요될 수 있다.
- 데이터의 변경 작업이 자주 일어날 경우 오히려 성능이 나빠질 수도 있다.
책의 찾아보기를 보면 뒤에 새로운 페이지를 만든다. 그만큼 저장공간의 소요가 더 크다는 것이다. 그런 작업 때문에 10%정도의 추가 공간이 필요하고, 인덱스 생성시 시간이 많이 소요될 수 있는 것이다.
효율적인 INDEX
- WHERE 절에 자주 등장하는 컬럼을 인덱스로 설정
- ORDER BY 절에 자주 등장하는 컬럼을 인덱스로
- SELECT 절에 자주 등장하는 컬럼들을 잘 조합해서 인덱스로 구성
- JOIN이 자주 사용되는 열에 인덱스를 생성해주는 것이 좋다.
INDEX는 저장공간, CUD속도를 희생하여 READ 즉 SELECT의 속도를 높이는 것이라 볼 수 있다. SELECT 절에서 많이 사용되는 WHERE, ORDER BY절에 자주 등장하는 컬럼을 INDEX로 사용하면 빠르게 가능하다. 그리고 SELECT 절에 자주 등장하는 컬럼들을 잘 조합해서 INDEX로 만들어두면 INDEX 조회 후 다시 데이터에서 조회할 필요가 없으므로 빠르게 검색이 가능하다.
데이터의 중복도
중복도가 높다 = 분포도가 낮다 = Cardinality가 낮다. = 나타나는 데이터의 종류가 별로 없다.
중복도가 낮다 = 분포도가 높다 = Cardinality가 높다 = 나타나는 데이터의 종류가 많다.
중복도가 높은 경우, 인덱스를 사용하는 것이 효율이 없지는 않지만 어차피 데이터를 읽기 위해 많은 페이지를 읽어야 하는 것은 마찬가지.
예를 들어 성별이라는 컬럼에 INDEX를 만들어두면 남,여 밖에 없기 때문에 중복도는 높고 분포도는 낮다. 데이터의 종류가 별로 없기 때문에, 남자를 검색할 때 절반이나 되는 ROW를 검색해야하고 결국 모든 ROW를 검색하는 table full scan이 더 나을지도 모른다. index를 봤다가 데이터를 봤다가 x 100000 을 하는게 더 느릴 수 있기 때문이다. 더군다나 인덱스 관리 비용이나 INSERT 구문으로 인한 성능 저하등을 고려하면 반드시 필요하지는 않다.
INDEX가 안 되는 쿼리
INDEX를 만들어 둔다고 모든 쿼리에서 INDEX를 활용하는 것은 아니다 인덱스가 안되는 쿼리를 알아봤다.
- 컬럼을 가공
- ex) WHERE SUBSTR(ORDER_NO, 1,4) = ‘2019’ -> WHERE ORDER_NO LIKE ‘2019%’
- 인덱스 컬럼의 묵시적 형변환(같은 타입으로 비교해야함)
- ex) WHERE REG_DATE = ‘20190730’ -> WHERE REG_DATE = TO_DATE(‘20190730’, ‘YYYYMMDD’)
- 인덱스 컬럼 부정형 비교.
- ex) WHERE MEM_TYPE != ‘10’ -> WHERE MEM_TYPE IN(‘20’, ‘30’)
- %가 앞에 위치.
- or 조건 사용 -> UNION ALL로 대체
INDEX 주의점
인덱스를 마구잡이로 생성하면 안 된다.
SELECT는 빨라지지만 INSERT나 UPDATE는 느려진다.
Clustered INDEX라면 정렬이 된 상태로 저장이 되기 때문에 어느 자리에 insert할지 찾아서 저장을 한다.
그리고 테이블에만 insert하는게 아니라 index에도 insert 해야 해서 느려진다.
INDEX를 탄다고 무조건 속도가 빨라지는 것은 아니다.
INDEX 손익분기점
테이블이 가지고 있는 전체 데이터양의 10% ~ 15%이내의 데이터가 출력 될 때만 INDEX를 타는게 효율적이고, 그 이상이 될 때에는 오히려 풀스캔이 더 빠르다.
Clustered INDEX
- 클러스터형 인덱스 생성 시에는 데이터 페이지 전체가 다시 정렬된다.
- 이미 대용량의 데이터가 입력된 상태라면 클러스터형 인덱스 생성은 심각한 시스템 부하를 줄 수 있다.
- 인덱스 자체의 리프 페이지가 곧 데이터이다. 그러므로 인덱 스 자체에 데이터가 포함되어있다고 볼 수 있다.
- 보조 인덱스 보다 검색 속도는 더 빠르다. 하지만 입력/수정/삭제는 더 느리다.
- 테이블에 한개만 생성할 수 있다. 어느 열에 클러스터형 인덱스를 생성하냐에 따라 달라질 수 있다.
- MySQL에서는 Primary Key가 있다면 Primary Key를 Clustered INDEX로, 없다면 UNIQUE 하면서 NOT NULL인 컬럼을, 그것도 없으면 임의로 보이지않는 컬럼을 만들어 Clustered Index로 지정한다.
Secondary Index
- 보조 인덱스의 생성시에는 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성.
- 보조 인덱스의 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소값(RID)
- 클러스터형 보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 덜 느리다.
- 보조 인덱스는 여러 개 생성할 수 있다. 함부로 사용할 경우에는 오히려 성능을 떨어뜨릴 수 있다.
테이블 구조
INDEX가 없을 때
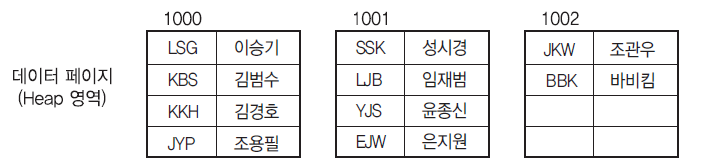
인덱스가 하나도 없으면 각각의 데이터페이지에 정렬 없이 순서대로 들어가게 된다.
Clustered Index만 있을 때
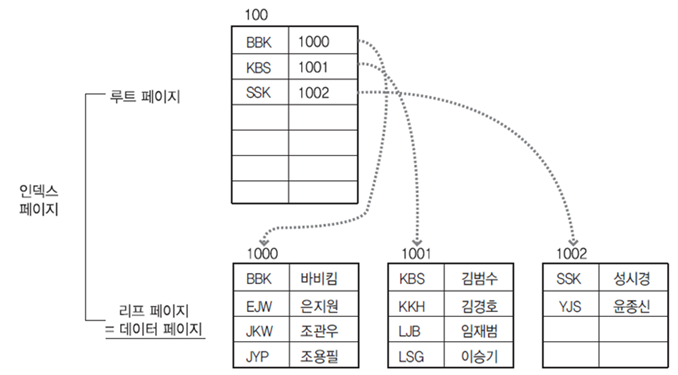
Clustered Index만 있을 경우에는 B-Tree (정확하게는 B+-Tree가 맞는 듯)를 사용하게 된다.
루트 페이지가 생기고 중간 중간 브랜치 페이지가 있으며, 맨 마지막인 리프페이지에는 정렬된 상태로 데이터들이 저장된다. Clustered Index는 영어사전과 비슷하다고 생각하면 된다. ABCDE... 등등이 INDEX고 딱 그페이지를 펼쳤을 때 바로 정보들이 있다. 그것과 똑같다. Clustered Index 또한 Index가 곧 Data이다. B-Tree를 사용하고, 정렬이 되어있기 때문에 검색은 무척 빠르지만, 삽입 삭제 등을 할 때, 페이지 분할이나 추가적인 정렬이 필요해 성능이 오히려 나빠진다.
Secondary Index만 있을 때
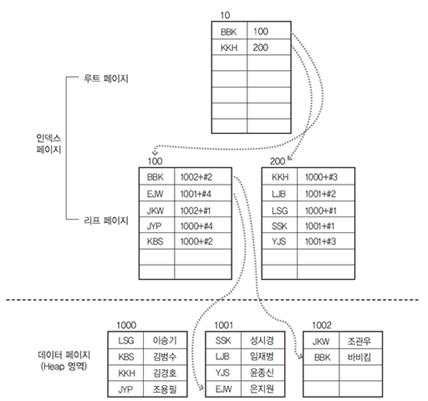
Secondary Index만 있을 경우에는 데이터 페이지는 INDEX가 없을 때와 똑같고 책 마지막의 찾아보기 같은 페이지가 따로 생긴다고 생각하면 된다. 이것 또한 B-Tree를 사용하며 리프 페이지는 INDEX를 기준으로 정렬이 되어있고, key로 index를 value로 데이터의 위치(ROW ID => RID)를 가지고 있다. 리프페이지가 데이터페이지가 아니기 때문에 Clustered Index보다 시간이 조금 더 걸린다고 볼 수 있다. 하지만 이런 경우는 거의 없다.
Clustered Index, Secondary Index 둘 다 있을 때
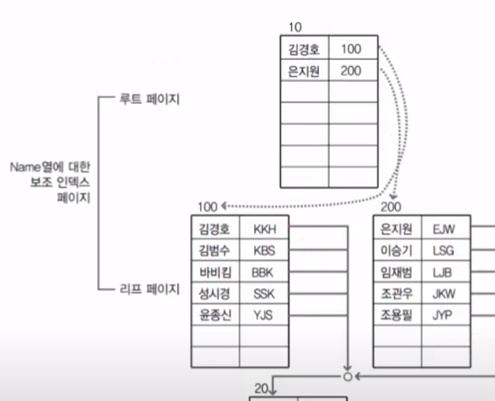
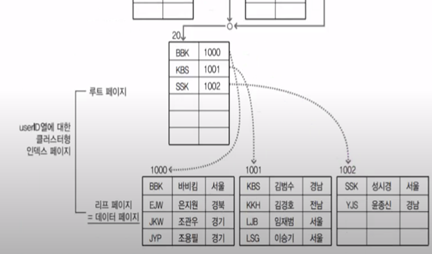
(그림 두개를 잘 이어서 보길 바람..)
Clustered Index는 위와 그대로 생긴다. Secondary Index 또한 그대로 생기지만, 이번엔 데이터의 주소가 아닌 PK를 저장한다. 왜 RID를 저장하지 않고 PK를 저장할까? RID를 저장한다면 Index를 끝까지 탐색하고 데이터로 바로가니깐 3페이지만 읽으면 데이터를 찾을 수 있다. PK를 저장해서 루트페이지도 읽고 리프 페이지를 읽어야하니 4페이지를 읽게된다. 오히려 성능이 저하되게 되는데 왜 그런 것일까?
그 이유는 데이터의 RID를 저장하게 되면 삽입 삭제를 할 때 INDEX의 PAGE가 완전 뒤집어져야하기 때문이다. 데이터를 추가하게 되면 데이터가 정렬되어야 하기 때문에 RID가 바뀌게 될 것이고 엄청나게 많은 데이터들의 RID가 바뀌게 될지도 모른다. 그렇게 되면 Secondary INDEX 페이지 또한 싹 갈아엎어야한다. 하지만 PK를 저장해 놓는다면 약간의 정렬만 하면 된다.
검색으로 얻는 이득 보다, 삽입 삭제시 잃는 성능이 더 크기 때문에 RID말고 PK를 저장하게 하였다.
성능 비교
데이터가 300만개 있을 때를 비교해보았다.
INDEX가 없을 시

INDEX 있을 때

INDEX 있음에도 엄청 많은 데이터를 처리할 때![]
결론
- WHERE 절에서 사용되는 열에 인덱스를 만들어야 한다.
- WHERE 절에 사용되더라도 자주 사용해야 가치가 있다.
- 데이터 중복도가 높은 열은 인덱스를 만들어도 별 효과가 없다.
- 외래 키를 지정한 열에는 자동으로 외래 키 인덱스가 생성
- JOIN에 자주 사용 되는 열에는 인덱스를 생성해주는 것이 좋다.
- INSERT/UPDATE/DELETE가 얼마나 자주 일어나는지를 고려해야한다.
- 클러스터형 인덱스는 하나만 생성된다.
- 사용하지 않는 인덱스는 제거하자.
참고
https://12bme.tistory.com/138
호눅스님 강의
이것이 MySQL이다 강의
SQL전문가 정미나 유튜브
