🔧 TensorRT-LLM
TensorRT-LLM은 NVIDIA GPU에서 LLM 모델을 TensorRT 엔진으로 최적화하여 추론 속도와 처리량을 획기적으로 향상시키는 기술입니다.
🚀 핵심 개념 요약
- Tensor Parallelism: 가중치 행렬을 다수의 GPU로 분할하여 병렬 처리함

- In-flight Batching: 추론 요청이 도착한 순서와 무관하게 완료된 시퀀스는 즉시 제거하고, 실시간으로 다음 요청을 받아 실행하여 GPU 활용률과 처리량을 극대화
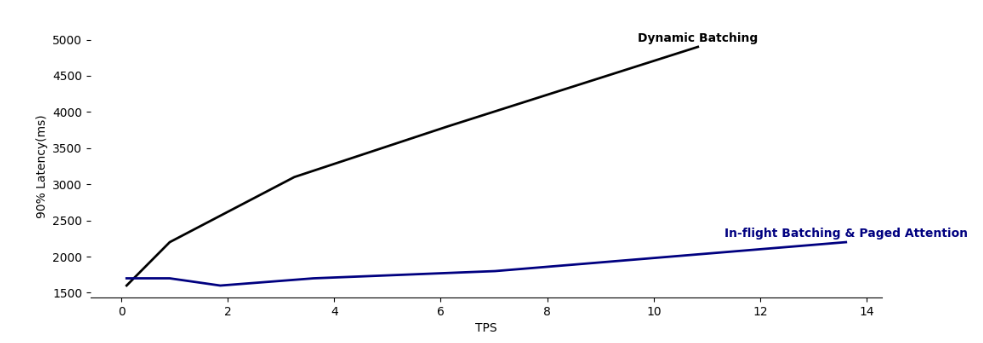
- 위 그래프는 기존 Dynamic Batching에 비해서 Tensorrt-LLM에 쓰이는 In-flight Batching이 Latency가 굉장히 적어 매우 효율적임을 보여준다.
📈 성능 비교
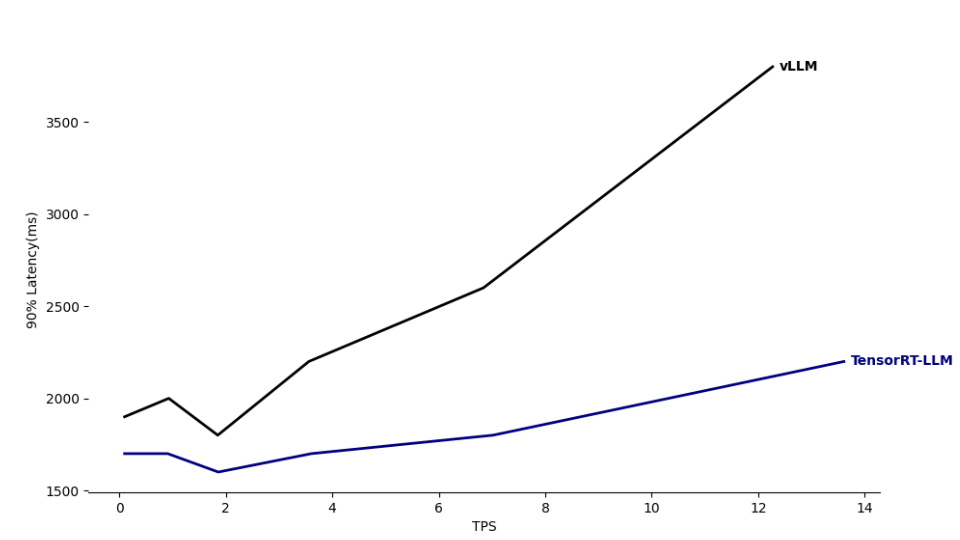
- 위 그래프에서 주로 LLM Inference 추론 최적화에 사용되는 대표적인 두 프레임워크인 vLLM과 Tensorrt-LLM을 비교한 성능표 입니다.
- 그 결과 낮은 트래픽 상황에서 두 모델모두 Latency가 비슷한데, 트래픽이 증가함에 따라 점차 Tensorrt-LLM이 좀 더 효율적으로 요청에 대해서 처리함을 보여줍니다.
- 대표적인 이유가 위 In flight Batch는 입력된 요청에 대해서 완료된 순서로 시퀀스가 끝나다보니, 기존 입력 시퀀스 길이에 따라 페이지를 블록 단위로 관리하는 Paged Attention에 비해 다량의 요청에 대해 효율적으로 처리함을 볼 수 있습니다.
⚙️ LLaMA 모델 TensorRT-LLM 적용
1. 필수 패키지 설치
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM/examples/llama
pip install -r requirements.txt
#### 모델의 토크나이저 및 가중치 다운로드
- Llama3 모델에 TensorRT-LLM으로 추론 최적화를 하기 위해서 해당 모델의 체크포인트가 필요합니다. 그래서 git clone https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct 을 통해 Llama 3.1 8B 모델의 가중치와 토크나이저 파일을 가져옵니다.
- 한국어로 사전학습된 모델의 가중치와 토크나이저를 다운로드하고 싶으시면 https://huggingface.co/원하는Model 로 다운로드를 진행하시면 됩니다.
#### HF LLaMA 체크포인트 변환
```python
python3 ./convert_checkpoint.py \
--model_dir Llama3-Chat_Vector-kor \
--dtype bfloat16 \
--world-size 1 \
--output-model-dir llama-tensorrt- world-size는 분산 훈련에서 사용하는 프로세스 수인데, 해당 값을 늘리게 되면 여러 프로세스를 사용하여 훈련 속도를 높일 수 있습니다.
HF 체크포인트 TensorRT 엔진 빌드
trtllm-build --checkpoint_dir llama-3-8b-ckpt \
--gemm_plugin float16 \
--output_dir ./llama-3-8b-engine- plugin에 지정된 정밀도로 활성화 하도록 옵션을 지정할 수 있습니다. float16, bfloat16, auto, disable 등의 옵션값이 있습니다.
- 추가로 workers parameter가 있는데, 추론에 필요한 GPU 인수를 추가하여 병렬 빌드를 활성화하여 엔진 빌드 프로세스를 더 빠르게 만들 수 있습니다.
- 만약에 AssertionError : Engine building failed, please check the error log라는 오류가 발생하면, plugin.py 파일에서 dataset 함수가 존재합니다. 해당 함수의 init=False라는 값을 모두 True로 변경하면 위 문제를 해결할 수 있습니다.
Tensorrt-LLM 실행
python3 ../run.py --engine_dir ./llama-3-8b-ckpt --max_output_len 1024 --tokenizer_dir ./Llama3-Chat_Vector-kor --input_text "대한민국의 수도는 어디인가요?"
# result
"<|begin_of_text|>대한민국의 수도는 어디인가요?"
Output [Text 0 Beam 0]: " 서울입니다. 서울은 대한민국의 수도이자 정치, 경제, 문화의 중심지입니다. 서울은 한강을 중심으로 남쪽은 강남, 북쪽은 강북으로 나뉘어져 있습니다. 강남은 서울의 남쪽 지역으로 고층 빌딩과 아파트가 많고, 강북은 서울의 북쪽 지역으로 오래된 건물과 주택이 많습니다. 서울은 대한민국의 수도이기 때문에 많은 사람들이 살고 있습니다. 서울의 인구는 약 1,00만 명으로 대한민국 전체 인구의 약 20%를 차지하고 있습니다. 서울은 대한민국의 정치, 경제, 문화의 중심지이기 때문에 많은 사람들이 서울로 몰려들고 있습니다. 서울은 대한민국의 수도이기 때문에 많은 사람들이 살고 있는 만큼 많은 문제점도 가지고 있습니다. 서울의 인구가 너무 많기 때문에 교통 체증, 주택난, 환경오염 등의 문제점이 발생하고 있습니다."- 위와 같이 결과가 잘 출력됨을 볼 수 있습니다.
- 지금까지 TensorRT-LLM으로 모델 추론 최적화를 수행해보았는데, 다음에는 Triton 서버로 배포하는 방법에 대해 알아보도록 하겠습니다.

NLP Developer
python3 ./convert_checkpoint.py \
--model-dir Llama3-Chat_Vector-kor \
--dtype bfloat16 \
--world-size 1 \
--output-model-dir llama-tensorrt
에서 --model_dir 형태로 언더바로 수정해야할 것 같습니다. 제가 사용한 tensorrt 0.11.0, 0.9.0에서는 --world_size 인자가 없다고 에러나는데 혹시 tp_size와 다른 인자인지 여쭤봅니다.