Instruction-Tuning
- 작년 초, LLAMA가 처음 등장하고, Alpaca를 통해 Instruction-Tuning을 하여, 언어 모델이 사람처럼 답변을 할 수 있도록 미세조정하는 방법이 등장한 이후, 데이터셋의 품질이 중요해지고 있습니다.
- 하지만 양질의 데이터셋을 구축하기 위해서는 OpenAI처럼 엄청난 비용과 시간을 투자해야합니다.
- 이번에는 양질의 Instruction Dataset을 생성하는 방법에 대해 알아보고자 합니다.
1. Evol-Instruct
- 작년에 나온 방법론으로, In-depth Evoving과 In-breadth Evolving 방식으로 나뉩니다.
- In-depth Evolving에서는 제약 조건 추가, 심화, 구체화, 추론 단계 증가, 입력 복잡화의 다섯 가지 유형의 작업이 포함되어 있습니다.
- In-breadth Evolving은 주제 범위, 기술 범위 및 전반적인 데이터 세트의 다양성을 강화하는 것을 목표로, 제공된 명령어를 기반으로 완전히 새로운 명령어를 생성하는 작업입니다.
- 응답을 생성할 때, 아래와 같이 총 4단계를 포함합니다.
- 원래 명렁어와 비교하여 새로운 정보를 제공하지 않은경우
- 생성하기 어려운 지시일경우
- 생성된 응답에 구두점과 불용어가 포함된 경우
- 사용된 프롬프트가 반복 사용된 경우
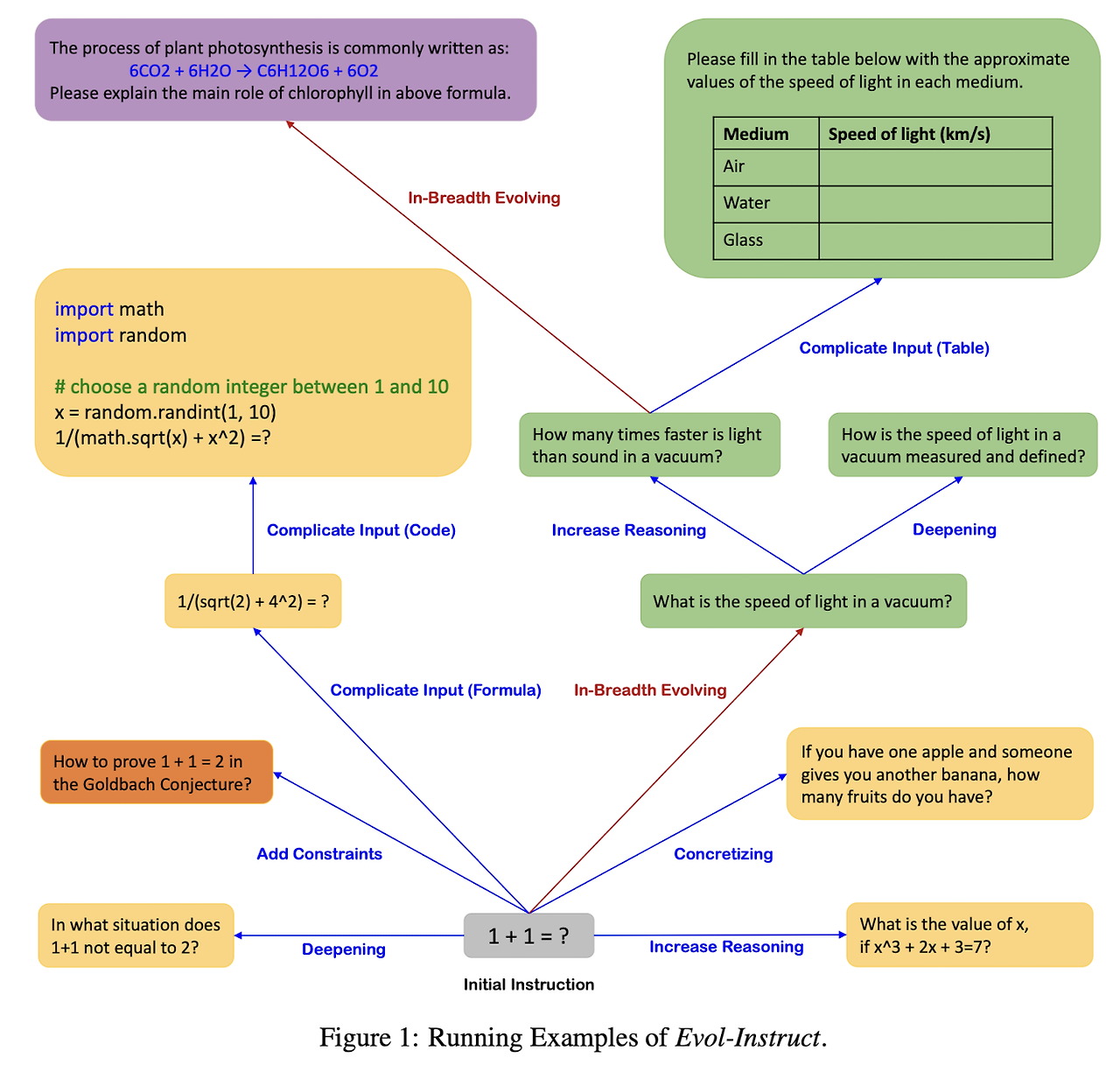
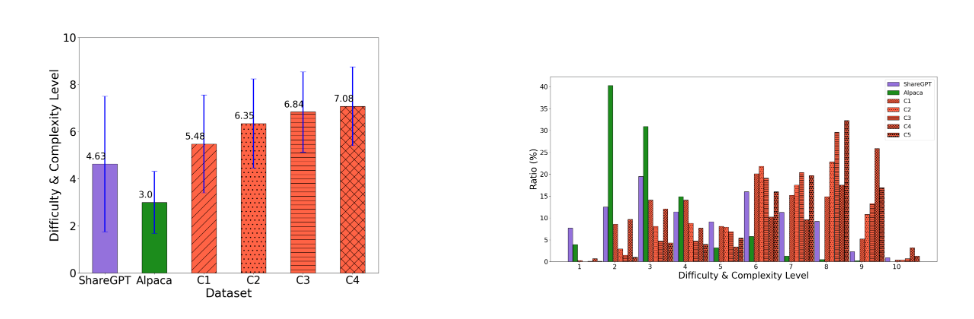
- 결과적으로, 각 지시의 난이도와 복잡도 수준이 높아, 심도있는 인간의 지시보다 더 높은 성능을 발휘함.
- Alpaca에 비해 좀 더 큰 주제의 다양성을 포함함.
2. Magpie
- 비교적 최신에 나온 방법론으로, 미세조정된 LLM 모델에서 Instruction Dataset을 추출하여, 고품질 합성 데이터셋을 생성하는 방법이다.
- Magpie를 통해 LLAMA3 모델에서 300K의 고품질 학습 데이터를 추출하여, SFT 미세조정한 결과 10M개의 SFT+DPO로 학습한 기존 LLAMA3와 비슷한 성능을 보였습니다.
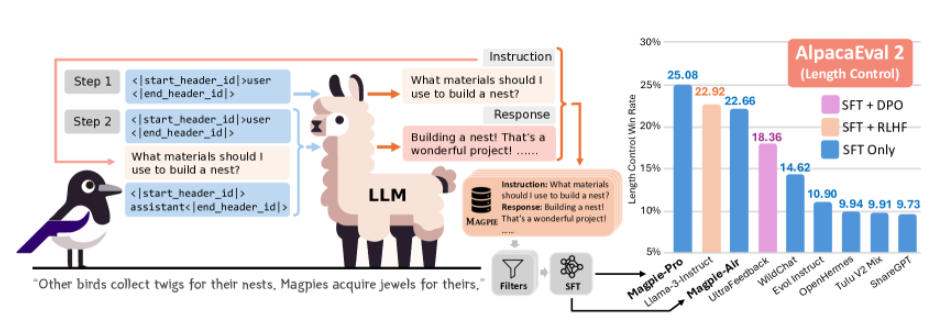
- Magpie는 학습된 LLM에는 사전 쿼리 템플릿, 쿼리, 사후 쿼리 템플릿 3가지 핵심 구성요소가 포함이 되는데, LLaMA-2는 [INST]라는 사전 쿼리 템플릿을 [/INST]라는 사후 쿼리 템플릿을 포함함
- 사전 쿼리 템플릿은 <lm_head> user </lm_head> 이런 형식으로 구축을 하여 Instruction을 생성함.
- 그 후, Instruction에 대해서 Output을 생성하는데, meta info를 통해 Instruction 단계에서는 task 분류, 품질, 난이도, 중복에 따른 필터링을 수행하고, Output에서도 품질 필터링을 사용하여 보다 더 다양한 고품질 QA를 생성할 수 있게 됨.
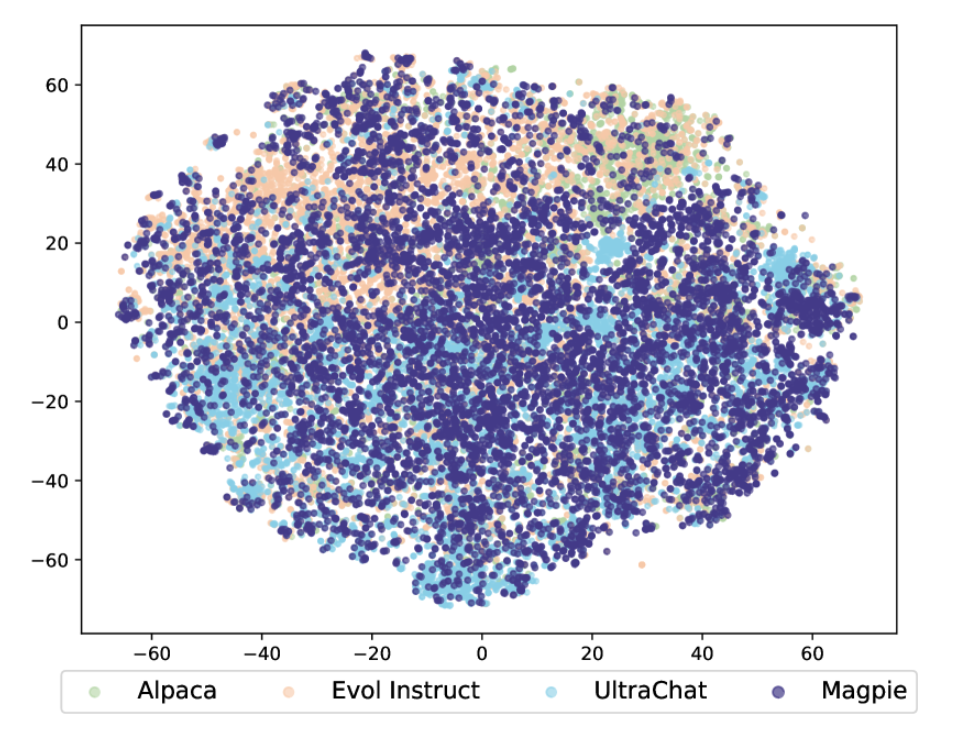
- 위처럼 Mapie는 Alpaca, Evol Instruct, UltraChat에 비해 다양한 도메인의 주제를 포괄함을 볼 수 있다.
- 그래서 저도 최근에는 Magpie로 수집한 영어 데이터셋에서 일부를 한국어로 번역하면서 미세조정 시, 추가하여 학습하고 있습니다.
- 특정 Task에 대한 미세조정 시, 특정 Task에 대한 성능은 올라가지만, 그 외 나머지 Task에 대한 성능은 떨어지는 경우가 있는데, 여기서 Magpie처럼 다양한 도메인을 포괄하는 데이터셋을 추가해주게 된다면 해당 문제를 해결할 수 있다.
Reference

NLP Developer