
Gemma3
- google에서 3월 12일 최첨단 LLM 모델 gemma3를 발표 했습니다.
- 모델의 파리미터는 1B, 4B, 12B, 27B으로 가지는데, 이번에는 멀티모달리티 도입하여 시각적인 이해를 할 수 있는게 이전 Gemma2와 비교해서 큰 차이점 입니다.
모델 아키텍처
-
이전 Gemma2 모델과 차별적인 점은 총 4가지이며, 대표적으로 Tokenizer, Context Length, Attention 연산, Tool-call이 있습니다.
-
주요 특징:
-
Tokenizer
- 기존에는 256k의 토큰을 가지고 있어 다른 sLLM에 비해 뛰어난 다국어 이해 능력을 보였으며, 이번 Gemma3에서는 262k 토큰을 학습하여 다국어 지원을 더욱 강화했습니다.
-
Context Length
- 기존 Gemma2는 8k context length로 제한되어 있어,RAG와 같은 검색 기반 시스템에서 Top-k 검색 길이에 한계가 있었습니다. 반면, Gemma3는 128k 컨텍스트 길이를 채택하여 장문 입력 처리 성능이 크게 향상되었습니다.
-
Attention 연산
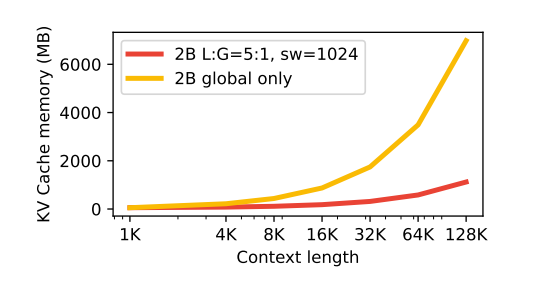
- 기존 Gemma2는 글로벌과 로컬 어텐션을 1:1 비율로 수행해 모든 단어 또는 일부 단어에 대해 주기적으로 어텐션을 적용했습니다. Gemma3는 1k 길이 기준 5회 로컬 + 1회 글로벌 어텐션 구조로 성능과 효율성을 모두 개선하였습니다.
-
Tool-call 지원
- Gemma3는 다른 최신 sLLM들과 마찬가지로 Tool-call 기능을 기본 지원합니다. 이를 통해 외부 API 또는 계산 도구 호출이 가능하며, 에이전트 RAG 구조나 복합 Task 수행에 더욱 유리합니다.
-
-
결론적으로, Gemma3는 다국어 처리, 장문 입력 대응, 고효율 어텐션 구조, 그리고 외부 도구 호출 능력까지 갖춘 강력한 차세대 sLLM입니다.
BenchMark
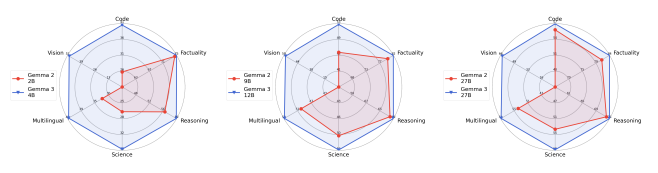
- Gemma 3의 새로운 사후 학습 레시피(Post-training Recipe)는 수학, 채팅, 명령어 추종, 다국어 능력에서 상당한 개선을 가져왔습니다. 이러한 특정 영역에서의 개선은 주요 애플리케이션 분야에서 모델의 성능을 향상시키기 위한 사후 학습 단계에서의 집중적인 노력을 시사합니다.
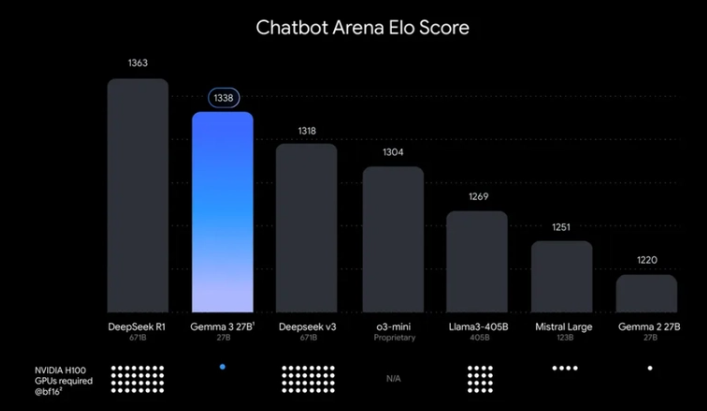
- 위 벤치마크를 통해 Gemma3는 Reasoning 모델이 아니지만, 추론형 모델에 비해서도 성능이 매우 훌륭한 편이고, 다른 100B이상 모델과 비교해도 높은 성능을 발휘하는데, 이것은 Google의 Knowledge Distillation이 효과적으로 수행되었음을 확인할 수 있습니다.
Gemma3 사용해보기
사용한 패키지 버전
- torch == 2.5.0
- transformers == 4.50.1
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-4b-it",
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])-
Gemma3는 강력한 다국어 기능뿐 아니라, 멀티모달리티(시각적 이해)까지 지원합니다. 이를 통해 향후에는 소형 4B 모델을 기반으로 문서 이해 능력을 학습시켜 VLM 기반 RAG 시스템에서 Document Parser를 최적화하는 방식도 유효할 것입니다.
-
⚠️ 단, 1B 모델은 다국어 지원이 되지 않으므로 한국어 기반 작업을 수행하려면 4B 이상의 모델을 사용하는 것을 권장합니다.

NLP Developer