💡 Prompt 없이 Chain-of-Thought?
- 구글 딥마인드의 "Chain-of-Thought Reasoning without Prompting" 논문을 소개해보도록 하겠습니다.
✨ 배경
-
LLM에게 복잡한 문제 해결을 유도할 때 보통 "Let's think step by step"처럼 Chain-of-Thought(CoT) 프롬프트를 넣거나, 사전 파인튜닝된 모델을 사용해야 한다고 알려져 있습니다.
-
하지만 Google DeepMind는 "프롬프트 없이도 모델이 스스로 CoT 추론을 할 수 있다면 어떨까? 라는 방식으로 접근합니다.
🧠 핵심 아이디어: 디코딩 전략만으로 CoT 유도

-
기존 방식은 Greedy Decoding으로 가장 확률 높은 토큰만을 선택했습니다.
-
그러나 논문에서는 Top-k 디코딩을 적용해, 여러 후보 토큰을 기반으로 다양한 reasoning 경로를 생성합니다.
-
이러한 다양한 경로 중 일부는 자연스럽게 단계적 추론(CoT) 형태를 띠며, 모델의 내재된 reasoning 능력이 드러나게 됩니다.
🔍 주요 실험 결과
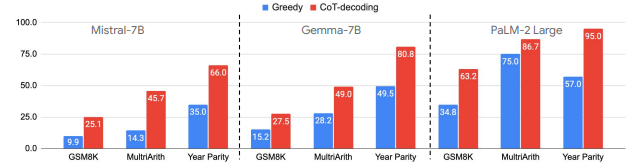
-
CoT Decoding
- Greedy 대신 Top-k 디코딩으로 다양한 추론 경로를 탐색, 일부 경로는 자연스럽게 Chain-of-Thought 형식을 따름
-
모델 확신도와 추론의 관계
- CoT 형태로 추론한 경로일수록 모델의 확신도(logprob)가 높았고, 정답률도 향상됨
-
다양한 벤치마크에서 성능 향상
- GSM8K(수학), CommonsenseQA(상식), LogiQA(논리) 등에서 Greedy보다 더 높은 정확도를 보임
🧩 실용적 시사점
✅ 프롬프트 설계 부담 감소
- 복잡한 프롬프트 없이도 디코딩 전략만으로 추론을 유도할 수 있습니다.
✅ 모델의 순수한 추론 능력 측정
- CoT 디코딩은 모델이 본래 갖고 있는 reasoning 능력을 확인할 수 있는 좋은 실험 도구가 됩니다.
✅ 다양한 모델에 적용 가능
- Instruction tuning이 되지 않은 pretrained 모델에도 적용할 수 있어, Gemma, LLaMA, Mistral, Phi 등 오픈소스 모델에 폭넓게 활용 가능합니다.
📌 마무리
-
이 논문은 단순히 디코딩 방식만 바꿨을 뿐인데도 놀라울 만큼 CoT 스타일 추론이 자연스럽게 등장한다는 점에서 매우 인상 깊습니다.
-
프롬프트 없이 CoT를 구현하고 싶다면 이 방식은 꼭 실험해볼 가치가 있습니다.
🔗 참고 자료
논문: CoT-Reasoning_without_Prompting
GitHub 구현: CoT without Prompting by Garrett Allen

NLP Developer