💭 To CoT or Not to CoT?
Chain-of-thought는 수학과 기호 추론에서만 효과적인가?
🧠 논문에서 전달하고자 하는 핵심 메시지
1. CoT는 만능 전략이 아니다
- 최근 LLM의 추론 성능을 끌어올리기 위해
Test-Time Scaling과 함께 Chain-of-Thought(CoT) 방식이 널리 사용되고 있습니다. - 그러나 이 논문은 모든 작업에서 CoT가 이점을 주는 것은 아니며, 작업의 성격에 따라 효과가 극명하게 갈린다고 주장합니다.
📊 주요 실험 결과
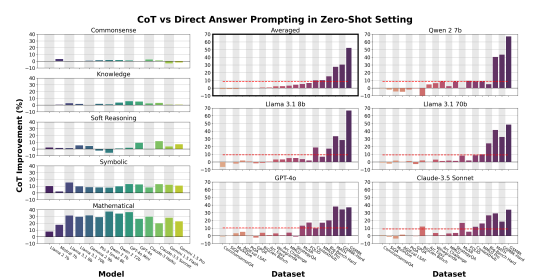
✅ CoT가 효과적인 작업 유형
- 📐 수학 문제 (예: MATH, GSM8K)
- 🧩 논리 퍼즐 (예: LogiQA, ReClor)
- 🧮 기호 조작 (예: 공식 전개, 도형 추론 등)
이러한 작업은 모두 단계별 계산, 명시적 추론 과정이 필요한 작업입니다.
CoT는 이런 구조화된 reasoning path를 제공함으로써 추론 능력을 크게 향상시킬 수 있습니다.
❌ CoT가 효과가 미미하거나 오히려 방해가 되는 작업
- 📚 일반 언어 이해 (예: BoolQ, OpenBookQA)
- 🧠 상식 기반 추론 (예: CommonsenseQA, PIQA)
이들 작업은 CoT처럼 단계적인 reasoning이 아니라, 배경 지식, 상식, 문맥 이해를 기반으로 합니다.
CoT를 넣는 것이 오히려 추론의 일관성을 해치고 noise가 될 수 있습니다.
📌 실험 결과가 주는 시사점
-
CoT는 수학·논리·기호 추론과 같은 '상징적 reasoning' 작업에 특화되어 있으며, 모든 태스크에서 무조건적인 성능 향상을 보장하지 않습니다.
-
특히 요즘 각광받는
DeepSeek R1,GPT-4-o1-preview같은 모델에서 Test-Time Scaling + CoT 전략이 흔히 사용되고 있지만,
이 논문은 그런 전략이 도메인에 따라 매우 다르게 작동할 수 있음을 경고합니다.
✅ 결론 및 나의 인사이트
최근 개인적으로 다음과 같은 의문을 갖고 있었습니다.
과연 DeepSeek, GPT-4-o1 등의 모델에 CoT를 넣는다고 해서 모든 QA 작업, 특히 도메인 특화 QA에서도 효과가 있는가?
하지만 이 논문을 통해 "그렇지 않다"는 근거 있는 해석을 얻을 수 있었습니다.
💡 따라서 이제는 CoT 전략 자체보다
"내 작업은 CoT가 필요한 symbolic reasoning인가, 아니면 background knowledge 기반인가?"
를 먼저 따져보는 것이 중요하다고 느꼈습니다.
또한, 프롬프트 설계보다도 정확한 데이터셋 구성과 작업 구조화에 초점을 맞춰야 할 것 같습니다.
🔗 참고
- 📄 논문 원문: arXiv:2409.12183
- 🧪 관련 키워드:
CoT,symbolic reasoning,test-time scaling,language understanding,LLM eval

NLP Developer