
⚡ vLLM: 고속 LLM 추론 프레임워크
- LLM을 활용한 서비스가 급증하면서, 모델 서빙 최적화에 대한 관심도 높아지고 있습니다.
- 그중 vLLM은 Hugging Face 대비 최대 24배 빠른 속도를 제공하며, 실시간 응답이 필요한 환경에서 큰 주목을 받고 있습니다.
- 이러한 성능의 핵심은 PagedAttention이라는 새로운 어텐션 기법에 있습니다.
🧠 PagedAttention이란?
- 기존 LLM 시스템은 출력 길이를 예측할 수 없기 때문에, 최악의 경우를 가정해 긴 시퀀스를 위한 메모리를 미리 확보합니다.
- 이로 인해 내부 단편화(Internal Fragmentation) 와 외부 단편화(External Fragmentation) 문제가 발생하게 됩니다.
- vLLM은 운영체제의 가상 메모리 페이징 기법에서 착안하여, KV 캐시를 불연속적으로 분할 관리(PagedAttention) 함으로써 메모리 낭비를 최소화합니다.
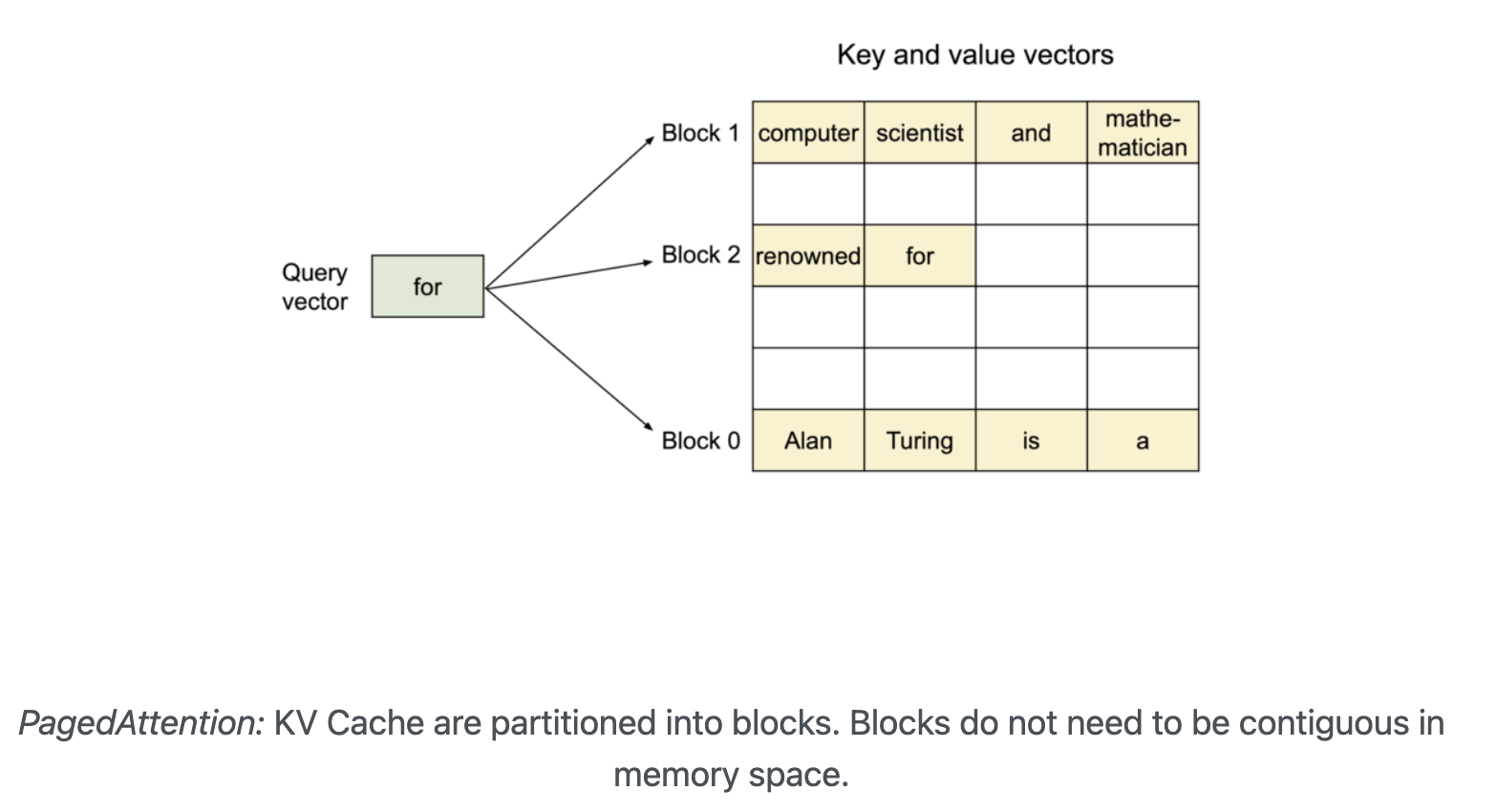
- 결과적으로 다수의 요청을 효율적으로 처리하며, 높은 throughput과 낮은 latency를 동시에 달성할 수 있습니다.
⚙️ 주요 파라미터 정리
| 파라미터 | 설명 |
|---|---|
generate | LLM 출력을 생성하는 핵심 함수 |
SamplingParams | 샘플링 옵션을 설정하는 클래스 |
temperature | 출력의 무작위성 제어 (0: 결정적 / 1: 창의적) |
max_tokens | 생성할 최대 토큰 수 |
top_p | 누적 확률 기반 샘플링 (0~1) |
top_k | 확률이 높은 k개의 후보 중에서 선택 |
🔧 vLLM으로 모델 서빙하기
1️⃣ 설치
pip install vllm
```python
from vllm import LLM, SamplingParms
# VLLM 모델 및 토크나이저 로드
BASE_MODEL = "추론에 사용할 모델명"
llm = LLM(model=BASE_MODEL, max_model_len=8192,download_dir='/data',tensor_parallel_size=8,gpu_memory_utilization=0.8)
# 샘플링 파라미터 설정
text = '질문(Prompt)'
sampling_params = SamplingParams(temperature=0, max_tokens=4096)
text = system_prompt + df['instruction'][0]
outputs = llm.generate([text],sampling_params)
response = outputs[0].outputs[0].text.strip()
print(response)vLLM을 활용하여 API 형태로 배포하기
# 터미널에서 실행
python -m vllm.entrypoints.api server \
--model #허깅페이스 모델명 or 모델 경로 \
--max-model-len= # 모델의 출력 최대 길이 지정 \
--tensor-parallel-size # 추론 및 Serving에 사용 할 gpu 갯수 지정
--gpu_memory_utilization=0~1 # gpu 1개 당 사용할 메모리 퍼센트 지정
# Jupyter Notebook 실행
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
class InputText(BaseModel):
text: str
item: str
@app.get('/')
async def root():
return "Hello World!"
@app.post('/editing')
async def edit_orion(input_text: InputText):
item = input_text.item
item_text = input_text.text
messages = [{"role": "user", "content": "질문"]
# instruct 모델은 chat template이 존재하여 아래와 같은 방법으로 진행가능
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
vllm_host = "http://localhost:8000"
url = f"{vllm_host}/generate"
headers = {"Content-Type": "application/json"}
data = {
"prompt": text,
"max_tokens": 4096,
"temperature": 0.1,
"top_k": 50,
"top_p": 0.95,
}
response = requests.post(url, headers=headers, data=json.dumps(data))- 이렇게 하면 손쉽게 FastAPI와 vLLM을 결합하여 LLM 서빙을 구축할 수 있습니다.
- LLM을 서빙하는 방식은 Triton, TensorRT-LLM, TGI 등 다양한 옵션이 존재하지만, vLLM은 높은 성능과 쉬운 사용성을 동시에 갖춘 강력한 추론 프레임워크입니다.
- 또한 GPTQ, AWQ 등 다양한 양자화 모델을 지원하지만,
GGUF 포맷은 미지원이라는 점은 아쉬운 부분입니다. 👉 이를 보완하기 위해 Aphrodite Engine이 있으며, 다음 글에서는 Aphrodite를 활용한 GGUF 기반 모델 서빙을 다룰 예정입니다.(현재는 gguf 확장자도 지원합니다.) - 추가적으로 CLI 환경에서 Specurative Decoding을 활용한다면 좀 더 빠른 추론이 가능합니다.
- 부하테스트를 진행하고 싶다면 benchmark_serving.py를 통해서 TTFT(첫 번째 토큰이 출력할 때가지 걸린시간), TPS(입력~응답까지 걸린 최종시간)을 확인할 수 있습니다.
참고 자료

NLP Developer