GGUF
-
이전에 llama.cpp을 이야기하면서, GGUF에 대해 이야기 해보았는데, GGUF은 C++ 기반의 연산을 수행하여, 대규모 언어 모델(LLM)과 같은 딥러닝 모델을 효율적으로 로드하고 실행하기 위해 설계되었습니다.
-
그래서 기존에는 llama.cpp을 통해서 GGUF로 변환을 해주어야 했었는데, 이제 이 작업을 허깅페이스에서 지원을 해준다고 하여 글을 작성하게 되었습니다.
GGUF-MY-REPO
1) 허깅페이스 gguf 변환 레포 접속
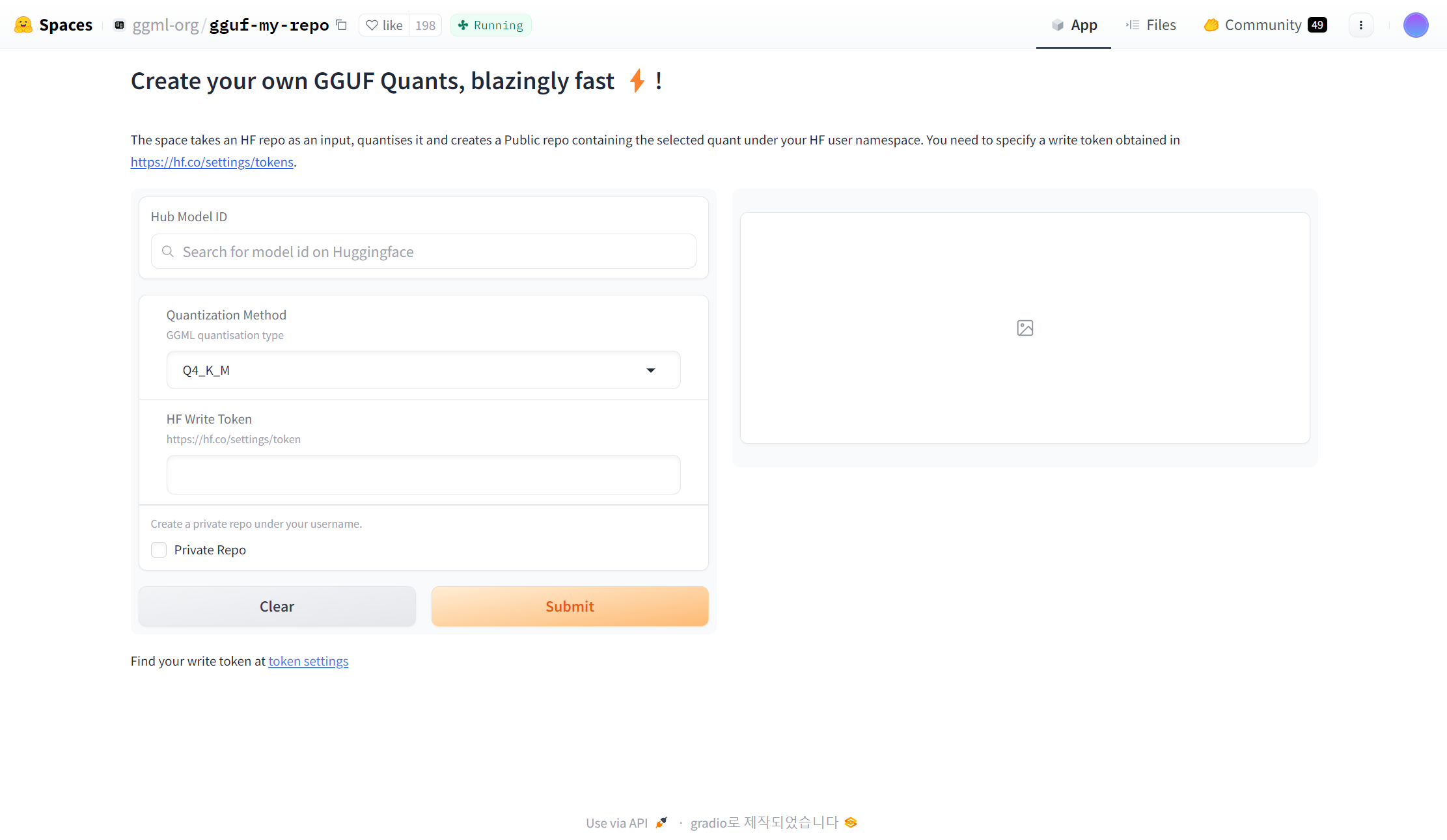
- 우선 https://huggingface.co/spaces/ggml-org/gguf-my-repo 해당 사이트를 가게 되면 LLM 모델을 GGUF 형태로 변환할 수 있는 Huggingface-space를 볼 수 있습니다.
2) 변환 할 모델 설정
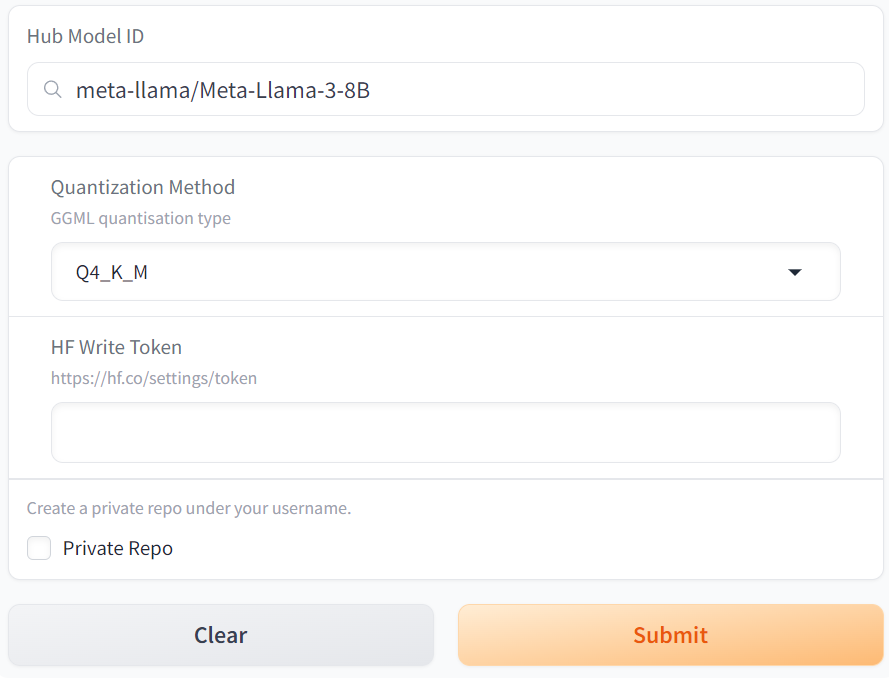
-
Hub Model에서는 변환하고 싶은 모델을 입력하고, 아래에 Quantization Method를 선택하면 되는데, 자세한 양자화 타입에 대해서는 https://huggingface.co/docs/hub/gguf 해당 사이트에서 상세하게 설명이 되어 있습니다.
-
주로 대부분 Q4_K_M과 Q5_K_M의 모델의 크기와 성능이 좋다고 알려져 있어 저도 해당 타입으로 양자화를 진행하였습니다.
-
그 후, 마지막으로 허깅페이스 계정의 Access Token 중 write 토큰을 입력하면 준비는 끝납니다.
-
제출하기를 누르면 10GB 모델 기준, 약 200초 정도 지나면 양자화가 된 모델이 본인 계정에 저장이 됩니다.
오늘은 이렇게 llama.cpp이 아닌 허깅페이스에서 제공하는 repo에서 보다 더 쉽게 양자화를 진행 해보았는데, 다음번에는 최신 LLM 기술 중 하나인 MergeKit과 이와 비슷한 fuseLLM에 대해 알아보겠습니다.

NLP Developer