LLM
1.LLM에 대해서

Large Language Model의 약자로, 대규모 데이터 세트에서 훈련된 언어 모델을 의미한다.해당 모델은 자연어처리에서 텍스트 생성, 요약, 분류, 감정 분석, 개체명 인식 등 다양한 작업을 수행할 수 있다.LLM을 만들기 위해 필요한 것1) 대규모 텍스트 데이
2.GPT-3.5 파인튜닝

이번에 LLM 관련 프로젝트를 하는데, 오픈소스로 공개된 여러 모델들을 사용을 해봤는데, 기대했던 성능이 잘 안나와서 GPT-3.5를 파인튜닝 시도를 해보았습니다.1) gpt에 파인튜닝 할 데이터셋(chat-completion 형식의 jsonl 파일)2) OpenA
3.[Model Review] Llama2

지금은 Alpaca, mistral, Solar, Orion 등 다양한 오픈소스 LLM이 등장하였지만 작년 9월까지만 하더라도 라마는 sLLM 분야에서 가장 강력한 오픈소스였습니다.기존 Llama1처럼 인터넷 데이터를 크롤링하여 약 2조개 정도의 토큰을 모았고, 사전
4.Ollama 튜토리얼

로컬 컴퓨터에서 개인 LLM 서버를 구성할 수 있게 도움을 주는 도구로, Mac,Linux와 Window에서 가능하며, 오늘은 리눅스와 윈도우에서 실행을 해보겠습니다.1) Linux 방식1) 우선, 저는 WSL을 통해 실행하였습니다.WSL 설치하는 방법은 https&#
5.[Model Review] 강력한 다중언어 모델-Orion

Orion-14B 모델은 중국어, 영어, 일본어, 한국어 등 2.5T 다국어 코퍼스를 대상으로 학습하였으며, 해당 언어에서 우수한 성능을 발휘함.Orion-14B에는 한국어가 2.5조개의 토큰에서 약 2.6% 정도 학습을 하였는데, 이 정도는 기존 2T 토큰에서 0.6
6.Orion 파인튜닝

이번에 자기소개서 첨삭 프로젝트를 진행하게 되었는데, 최종적으로 Orion 모델을 채택하게 되어, 해당 모델 파인튜닝을 진행하였습니다.모델 선정 이유Orion 모델은 2.5T 토큰으로 한국어, 일본어, 중국어, 영어 등 다양한 언어들로 학습을 하였고, 한국어 토큰은 O
7.로컬에서 LLM을 실행할 수 있는 llama.cpp

로컬에서 LLM 모델을 구동할 수 있도록 c++로 구현이 된 라이브러리오늘은 파인튜닝 한 모델을 GGUF 형식으로 변환하여 모델 크기를 줄여 로컬에서 실행할 수 있도록 진행해보겠습니다.1) 우선 github의 소스코드를 다운로드 하신 후, make 빌드를 진행하셔야 합
8.효율적인 미세조정 라이브러리 - Unsloth

Unsloth는 훈련속도를 재정의하여 생산성을 향상 시켰고, 미세 조정 시 메모리 사용량을 최대 60% 감소시키지만, 정확도 손실은 0%로 미세 조정에 최적화된 라이브러리로 소개가 되었습니다.그래서 오늘은 이 Unsloth로 가볍게 LLAMA를 미세조정하는 방법에 대해
9.이제는 어렵지 않게 GGUF 변환하기
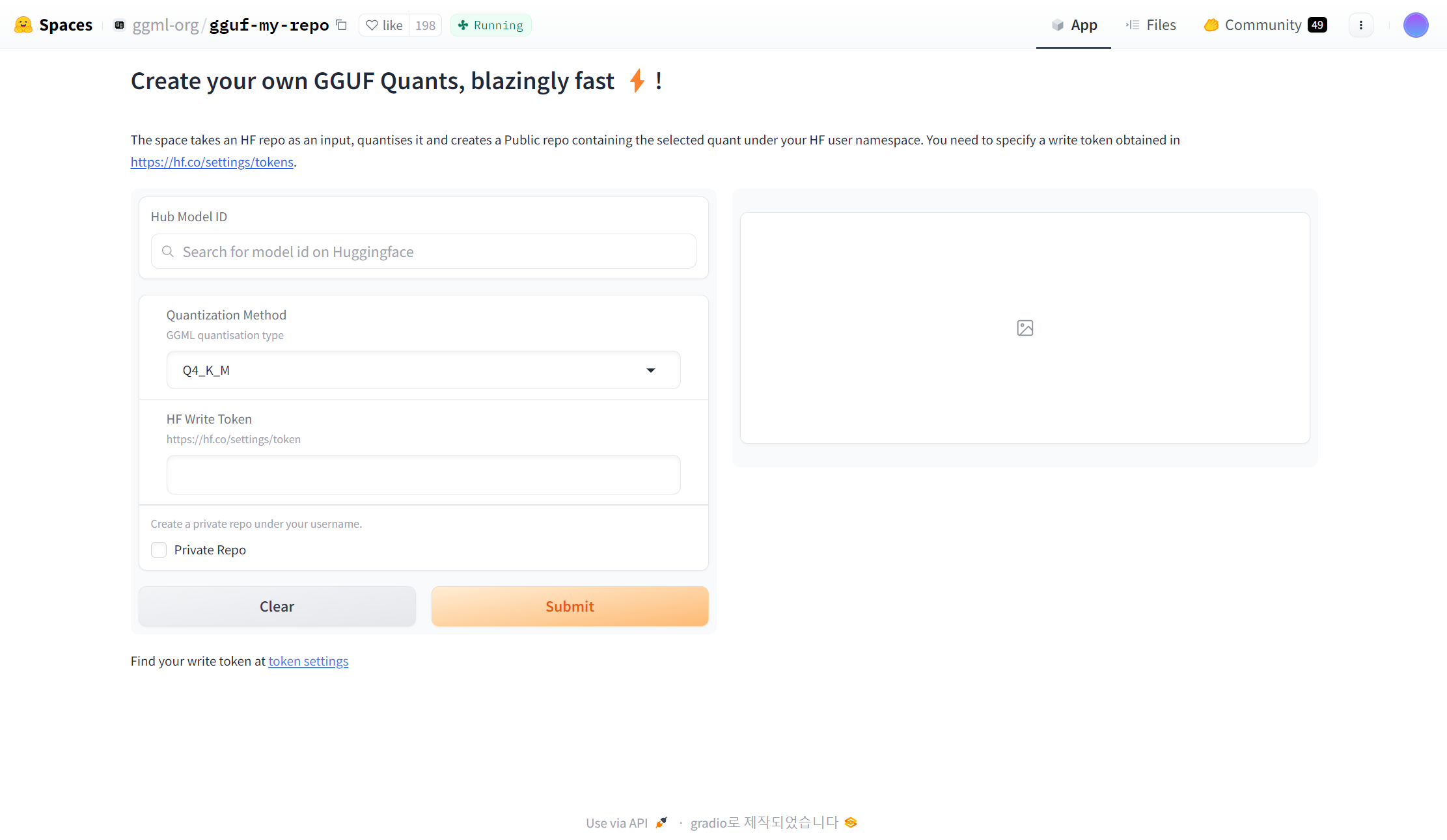
GGUF
10.한국어 LLM 개발 (1) - 토크나이저 확장
토크나이저
11.[논문 리뷰 및 활용] Chat-Vector
채팅 벡터를 활용하여 LLM의 기존 지식과 행동을 효율적으로 수행하는 방법을 소개합니다.위 작업을 수행하기 위해 meta의 llama-2 base 모델과 Instruction 모델 그리고, 특정 언어로 사전학습된 모델 3가지가 필요합니다.여기서는 중국어로 사전학습된 모