# 인공지능 라이브러리 활용하기
## 구글 speech로 음성 인식하기
책과는 다르게 라즈베리파이 마이크를 사용하지 않고 노트북 mic를 사용할 것이다.
### cloud Speech API 키 발급 받기
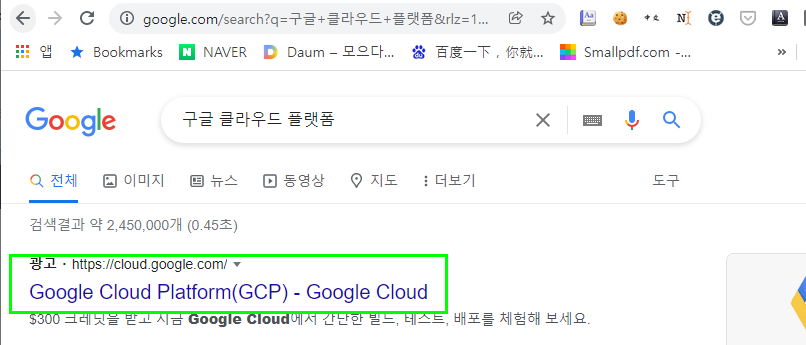
구글 클라우드 90일 활성화 후, 새프로젝트를 open한다.
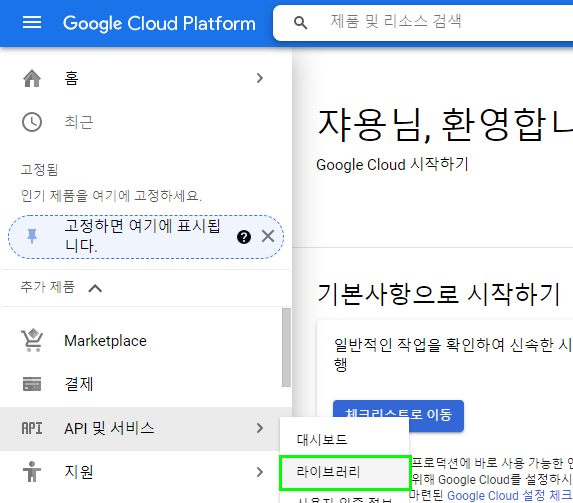
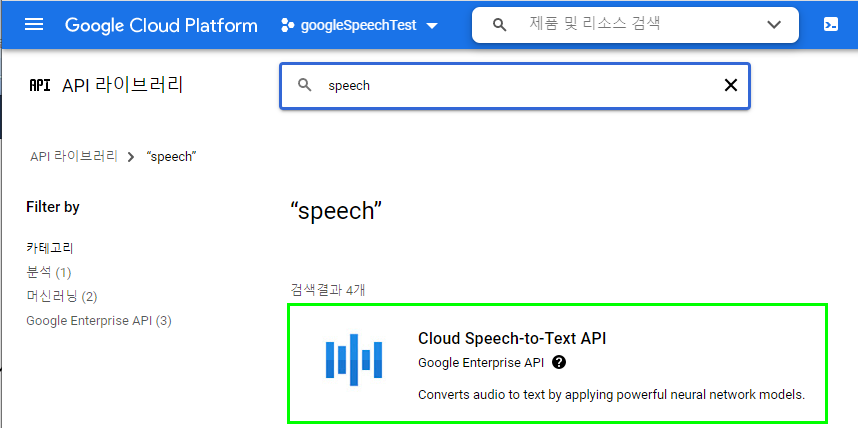
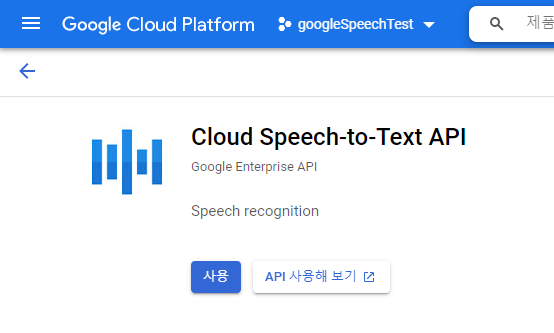
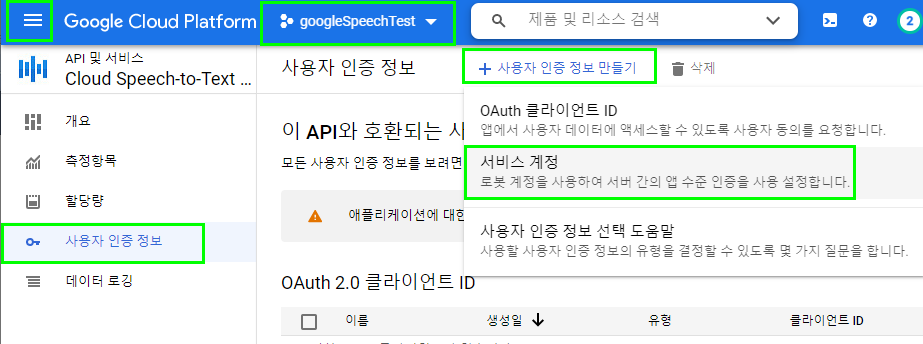
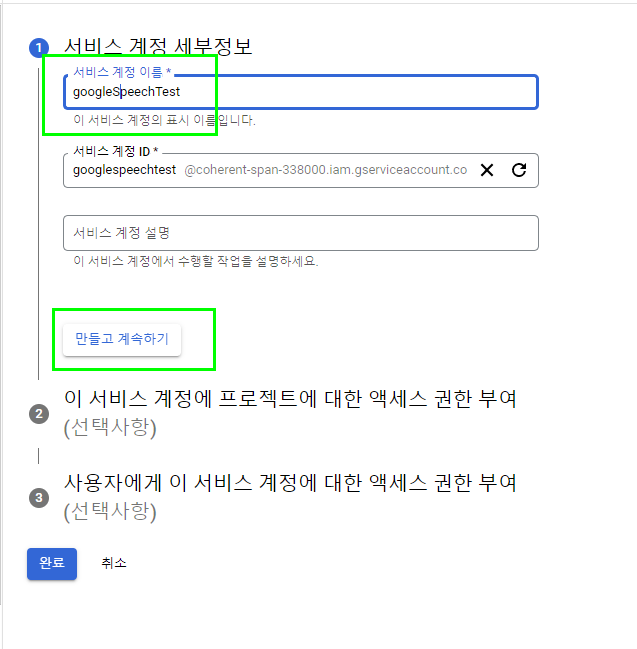
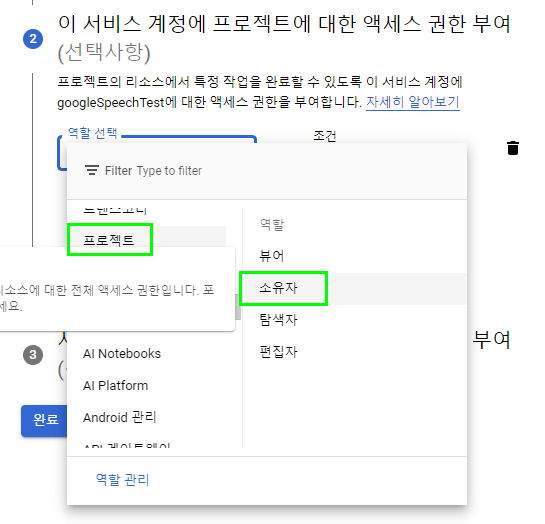
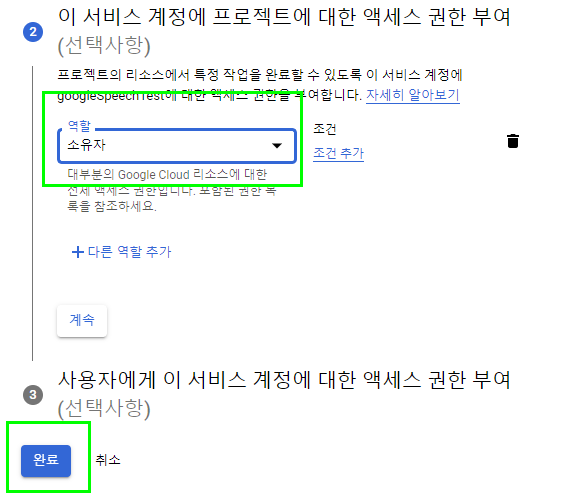


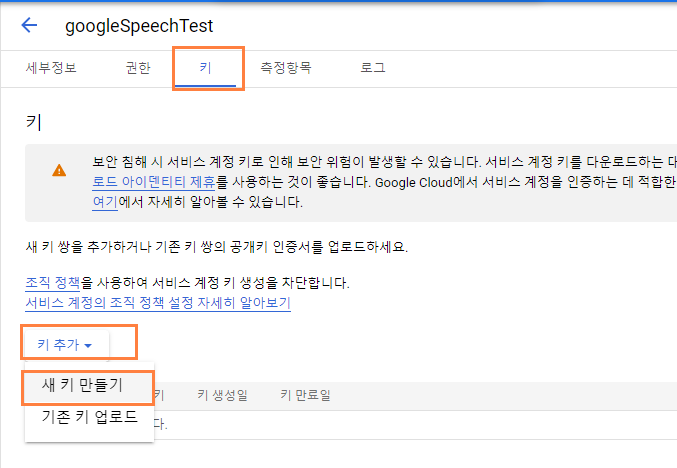

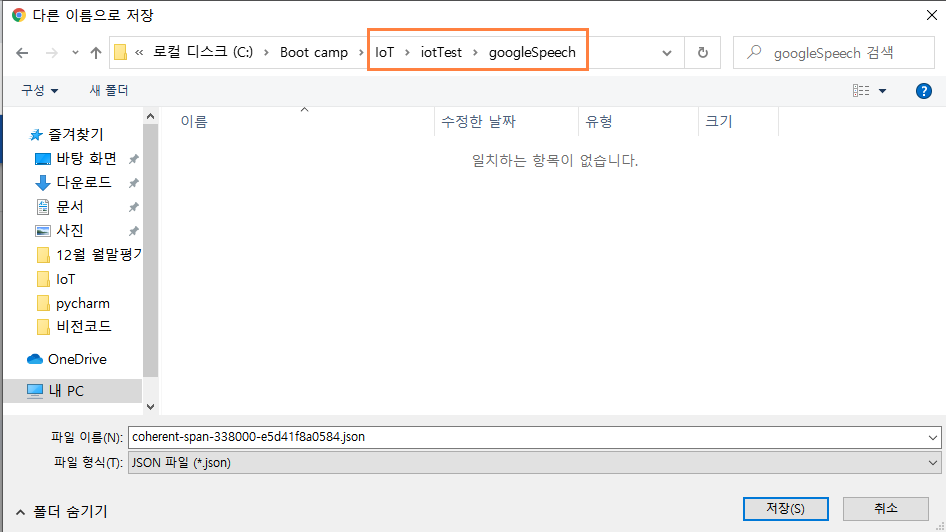

이후에 작성할 파이썬 프로그램에서 구글 음성 인식 API를 사용하기 위해서는 다음과 같이 키 파일 이름을 입력해 주어야 한다.
### 구글 음성 인식 라이브러리 설치하기
p315의 라이브러리 설치하자?
나는 아래와 같이 강사님이 공유해준 라이브러리를 아나콘다로 설치하였다.
설치를 pip로 했기 때문에 실행도 python으로 하면 된다.
pip install --upgrade google-auth pip install --upgrade google-api-python-client pip install google-cloud-speech pip install gTTS pip install pipwin pipwin install pyaudio
p316의 영어 음성 인식하기를 해보자
영어 음성 인식하기
- Boot camp/IoT/iotTest/googleSpeech/_23_gspeech.py
import os
from google.cloud import speech
from micstream import MicrophoneStream
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = \
"여기에 JSON형식의 내 키 값을 입력하면된다."
# Audio recording parameters
RATE = 44100
CHUNK = int(RATE /10) # 100ms
def listen_print_loop(responses):
for response in responses:
result = response.results[0]
transcript = result.alternatives[0].transcript
print(transcript)
if 'exit' in transcript or 'quit' in transcript:
print('Exiting..')
break
language_code = 'en-US' # aBCP-47 language tag
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding = speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz = RATE,
language_code = language_code)
streaming_config = speech.StreamingRecognitionConfig(config = config)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (speech.StreamingRecognizeRequest(audio_content = content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
listen_print_loop(responses)영어를 인식함을 알 수 있다.
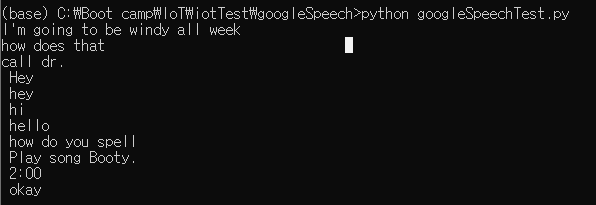
한국어 음성 인식하기
위 음성인식 코드에서 en-US -> ko-KR로 변경하면된다.
한글 읽고 말하기p 321
내가 마이크에 말하면 그대로 인식해서 컴퓨터 음성으로 출력한다.
노트북에 헤드셋 연결해서 말하면 훨씬 빠르게 인식한다.
- Boot camp/IoT/iotTest/googleSpeech/_23_gspeech.py
import os
from google.cloud import speech
from gtts import gTTS
from micstream import MicrophoneStream
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = \
"여기에 JSON형식의 내 키 값을 입력하면된다."
# Audio recording parameters
RATE = 44100
CHUNK = int(RATE /10) # 100ms
def do_TTS(text):
tts = gTTS(text = text, lang = 'ko')
a = os.path.exists('read.mp3')
if a:
os.remove('read.mp3') # 기존에 파일이 있다면 삭제
tts.save('read.mp3')
os.system('read.mp3') # os.system('mpg321 read.mpc')
def listen_print_loop(responses):
for response in responses:
result = response.results[0]
transcript = result.alternatives[0].transcript
print(transcript)
if '종료' in transcript or '그만' in transcript:
print('종료합니다..')
break
do_TTS(transcript) # 음성인식된 소리 넘기기
language_code = 'ko-KR' # aBCP-47 language tag
# 한글을 원하면 'ko-KR'로 설정하자 'en-US'
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding = speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz = RATE,
language_code = language_code)
streaming_config = speech.StreamingRecognitionConfig(config = config)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (speech.StreamingRecognizeRequest(audio_content = content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
listen_print_loop(responses)수업종료

공정 설비 개발/연구원에서 웹 서비스 개발자로 경력 이전하였습니다. Node.js 백엔드 기반 풀스택 개발자를 목표로 하고 있습니다.